 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADAPT: Actively Discovering and Adapting to Preferences for any Task
Apr 05, 2025Assistive agents should be able to perform under-specified long-horizon tasks while respecting user preferences. We introduce Actively Discovering and Adapting to Preferences for any Task (ADAPT) -- a benchmark designed to evaluate agents' ability to adhere to user preferences across various household tasks through active questioning. Next, we propose Reflection-DPO, a novel training approach for adapting large language models (LLMs) to the task of active questioning. Reflection-DPO finetunes a 'student' LLM to follow the actions of a privileged 'teacher' LLM, and optionally ask a question to gather necessary information to better predict the teacher action. We find that prior approaches that use state-of-the-art LLMs fail to sufficiently follow user preferences in ADAPT due to insufficient questioning and poor adherence to elicited preferences. In contrast, Reflection-DPO achieves a higher rate of satisfying user preferences, outperforming a zero-shot chain-of-thought baseline by 6.1% on unseen users.
RobotMover: Learning to Move Large Objects by Imitating the Dynamic Chain
Feb 07, 2025Moving large objects, such as furniture, is a critical capability for robots operating in human environments. This task presents significant challenges due to two key factors: the need to synchronize whole-body movements to prevent collisions between the robot and the object, and the under-actuated dynamics arising from the substantial size and weight of the objects. These challenges also complicate performing these tasks via teleoperation. In this work, we introduce \method, a generalizable learning framework that leverages human-object interaction demonstrations to enable robots to perform large object manipulation tasks. Central to our approach is the Dynamic Chain, a novel representation that abstracts human-object interactions so that they can be retargeted to robotic morphologies. The Dynamic Chain is a spatial descriptor connecting the human and object root position via a chain of nodes, which encode the position and velocity of different interaction keypoints. We train policies in simulation using Dynamic-Chain-based imitation rewards and domain randomization, enabling zero-shot transfer to real-world settings without fine-tuning. Our approach outperforms both learning-based methods and teleoperation baselines across six evaluation metrics when tested on three distinct object types, both in simulation and on physical hardware. Furthermore, we successfully apply the learned policies to real-world tasks, such as moving a trash cart and rearranging chairs.
PARTNR: A Benchmark for Planning and Reasoning in Embodied Multi-agent Tasks
Oct 31, 2024
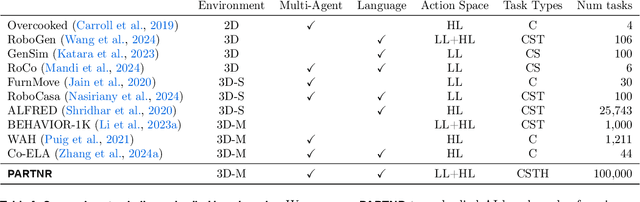

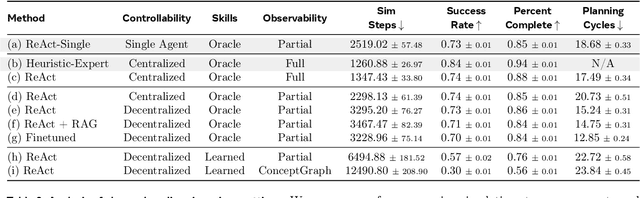
We present a benchmark for Planning And Reasoning Tasks in humaN-Robot collaboration (PARTNR) designed to study human-robot coordination in household activities. PARTNR tasks exhibit characteristics of everyday tasks, such as spatial, temporal, and heterogeneous agent capability constraints. We employ a semi-automated task generation pipeline using Large Language Models (LLMs), incorporating simulation in the loop for grounding and verification. PARTNR stands as the largest benchmark of its kind, comprising 100,000 natural language tasks, spanning 60 houses and 5,819 unique objects. We analyze state-of-the-art LLMs on PARTNR tasks, across the axes of planning, perception and skill execution. The analysis reveals significant limitations in SoTA models, such as poor coordination and failures in task tracking and recovery from errors. When LLMs are paired with real humans, they require 1.5x as many steps as two humans collaborating and 1.1x more steps than a single human, underscoring the potential for improvement in these models. We further show that fine-tuning smaller LLMs with planning data can achieve performance on par with models 9 times larger, while being 8.6x faster at inference. Overall, PARTNR highlights significant challenges facing collaborative embodied agents and aims to drive research in this direction.
IndoorSim-to-OutdoorReal: Learning to Navigate Outdoors without any Outdoor Experience
May 10, 2023We present IndoorSim-to-OutdoorReal (I2O), an end-to-end learned visual navigation approach, trained solely in simulated short-range indoor environments, and demonstrates zero-shot sim-to-real transfer to the outdoors for long-range navigation on the Spot robot. Our method uses zero real-world experience (indoor or outdoor), and requires the simulator to model no predominantly-outdoor phenomenon (sloped grounds, sidewalks, etc). The key to I2O transfer is in providing the robot with additional context of the environment (i.e., a satellite map, a rough sketch of a map by a human, etc.) to guide the robot's navigation in the real-world. The provided context-maps do not need to be accurate or complete -- real-world obstacles (e.g., trees, bushes, pedestrians, etc.) are not drawn on the map, and openings are not aligned with where they are in the real-world. Crucially, these inaccurate context-maps provide a hint to the robot about a route to take to the goal. We find that our method that leverages Context-Maps is able to successfully navigate hundreds of meters in novel environments, avoiding novel obstacles on its path, to a distant goal without a single collision or human intervention. In comparison, policies without the additional context fail completely. Lastly, we test the robustness of the Context-Map policy by adding varying degrees of noise to the map in simulation. We find that the Context-Map policy is surprisingly robust to noise in the provided context-map. In the presence of significantly inaccurate maps (corrupted with 50% noise, or entirely blank maps), the policy gracefully regresses to the behavior of a policy with no context. Videos are available at https://www.joannetruong.com/projects/i2o.html
ViNL: Visual Navigation and Locomotion Over Obstacles
Oct 26, 2022



We present Visual Navigation and Locomotion over obstacles (ViNL), which enables a quadrupedal robot to navigate unseen apartments while stepping over small obstacles that lie in its path (e.g., shoes, toys, cables), similar to how humans and pets lift their feet over objects as they walk. ViNL consists of: (1) a visual navigation policy that outputs linear and angular velocity commands that guides the robot to a goal coordinate in unfamiliar indoor environments; and (2) a visual locomotion policy that controls the robot's joints to avoid stepping on obstacles while following provided velocity commands. Both the policies are entirely "model-free", i.e. sensors-to-actions neural networks trained end-to-end. The two are trained independently in two entirely different simulators and then seamlessly co-deployed by feeding the velocity commands from the navigator to the locomotor, entirely "zero-shot" (without any co-training). While prior works have developed learning methods for visual navigation or visual locomotion, to the best of our knowledge, this is the first fully learned approach that leverages vision to accomplish both (1) intelligent navigation in new environments, and (2) intelligent visual locomotion that aims to traverse cluttered environments without disrupting obstacles. On the task of navigation to distant goals in unknown environments, ViNL using just egocentric vision significantly outperforms prior work on robust locomotion using privileged terrain maps (+32.8% success and -4.42 collisions per meter). Additionally, we ablate our locomotion policy to show that each aspect of our approach helps reduce obstacle collisions. Videos and code at http://www.joannetruong.com/projects/vinl.html
Retrospectives on the Embodied AI Workshop
Oct 17, 2022

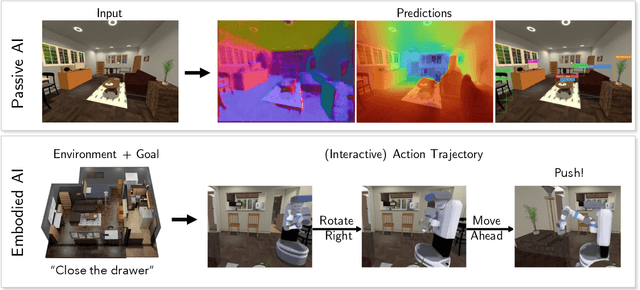
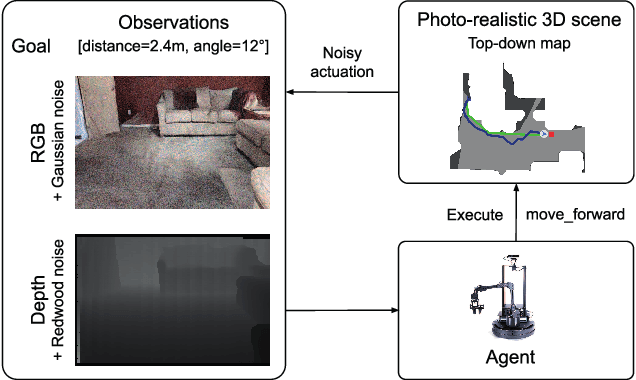
We present a retrospective on the state of Embodied AI research. Our analysis focuses on 13 challenges presented at the Embodied AI Workshop at CVPR. These challenges are grouped into three themes: (1) visual navigation, (2) rearrangement, and (3) embodied vision-and-language. We discuss the dominant datasets within each theme, evaluation metrics for the challenges, and the performance of state-of-the-art models. We highlight commonalities between top approaches to the challenges and identify potential future directions for Embodied AI research.
Rethinking Sim2Real: Lower Fidelity Simulation Leads to Higher Sim2Real Transfer in Navigation
Jul 21, 2022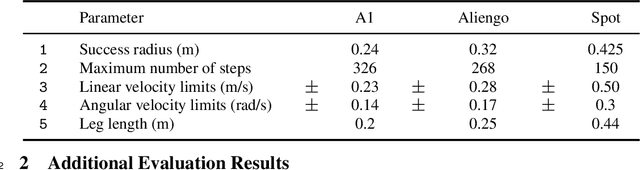
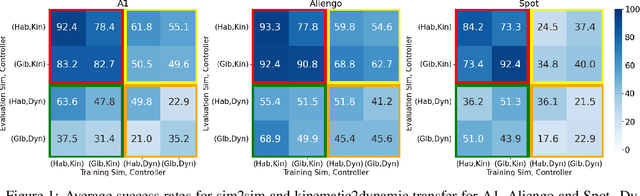


If we want to train robots in simulation before deploying them in reality, it seems natural and almost self-evident to presume that reducing the sim2real gap involves creating simulators of increasing fidelity (since reality is what it is). We challenge this assumption and present a contrary hypothesis -- sim2real transfer of robots may be improved with lower (not higher) fidelity simulation. We conduct a systematic large-scale evaluation of this hypothesis on the problem of visual navigation -- in the real world, and on 2 different simulators (Habitat and iGibson) using 3 different robots (A1, AlienGo, Spot). Our results show that, contrary to expectation, adding fidelity does not help with learning; performance is poor due to slow simulation speed (preventing large-scale learning) and overfitting to inaccuracies in simulation physics. Instead, building simple models of the robot motion using real-world data can improve learning and generalization.
Bi-directional Domain Adaptation for Sim2Real Transfer of Embodied Navigation Agents
Nov 24, 2020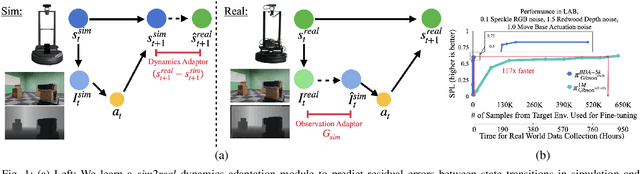


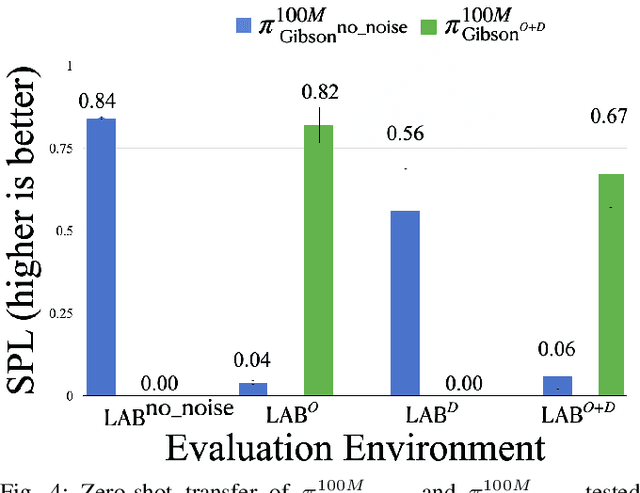
Deep reinforcement learning models are notoriously data hungry, yet real-world data is expensive and time consuming to obtain. The solution that many have turned to is to use simulation for training before deploying the robot in a real environment. Simulation offers the ability to train large numbers of robots in parallel, and offers an abundance of data. However, no simulation is perfect, and robots trained solely in simulation fail to generalize to the real-world, resulting in a "sim-vs-real gap". How can we overcome the trade-off between the abundance of less accurate, artificial data from simulators and the scarcity of reliable, real-world data? In this paper, we propose Bi-directional Domain Adaptation (BDA), a novel approach to bridge the sim-vs-real gap in both directions -- real2sim to bridge the visual domain gap, and sim2real to bridge the dynamics domain gap. We demonstrate the benefits of BDA on the task of PointGoal Navigation. BDA with only 5k real-world (state, action, next-state) samples matches the performance of a policy fine-tuned with ~600k samples, resulting in a speed-up of ~120x.
Learning Navigation Skills for Legged Robots with Learned Robot Embeddings
Nov 24, 2020

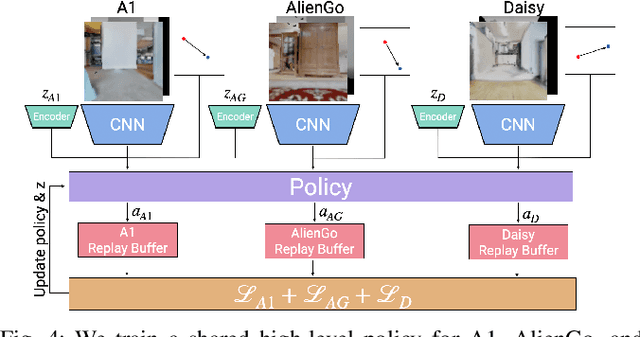
Navigation policies are commonly learned on idealized cylinder agents in simulation, without modelling complex dynamics, like contact dynamics, arising from the interaction between the robot and the environment. Such policies perform poorly when deployed on complex and dynamic robots, such as legged robots. In this work, we learn hierarchical navigation policies that account for the low-level dynamics of legged robots, such as maximum speed, slipping, and achieve good performance at navigating cluttered indoor environments. Once such a policy is learned on one legged robot, it does not directly generalize to a different robot due to dynamical differences, which increases the cost of learning such a policy on new robots. To overcome this challenge, we learn dynamics-aware navigation policies across multiple robots with robot-specific embeddings, which enable generalization to new unseen robots. We train our policies across three legged robots - 2 quadrupeds (A1, AlienGo) and a hexapod (Daisy). At test time, we study the performance of our learned policy on two new legged robots (Laikago, 4-legged Daisy) and show that our learned policy can sample-efficiently generalize to previously unseen robots.
Sim-to-Real Transfer for Vision-and-Language Navigation
Nov 07, 2020



We study the challenging problem of releasing a robot in a previously unseen environment, and having it follow unconstrained natural language navigation instructions. Recent work on the task of Vision-and-Language Navigation (VLN) has achieved significant progress in simulation. To assess the implications of this work for robotics, we transfer a VLN agent trained in simulation to a physical robot. To bridge the gap between the high-level discrete action space learned by the VLN agent, and the robot's low-level continuous action space, we propose a subgoal model to identify nearby waypoints, and use domain randomization to mitigate visual domain differences. For accurate sim and real comparisons in parallel environments, we annotate a 325m2 office space with 1.3km of navigation instructions, and create a digitized replica in simulation. We find that sim-to-real transfer to an environment not seen in training is successful if an occupancy map and navigation graph can be collected and annotated in advance (success rate of 46.8% vs. 55.9% in sim), but much more challenging in the hardest setting with no prior mapping at all (success rate of 22.5%).