 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Visual Imaginations Improve Vision-and-Language Navigation Agents?
Mar 20, 2025
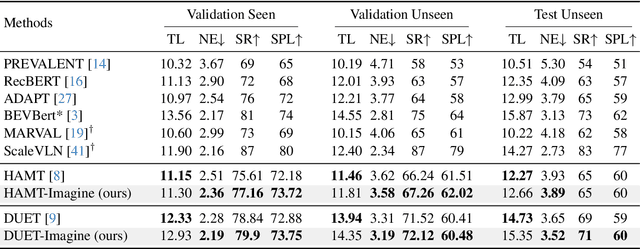

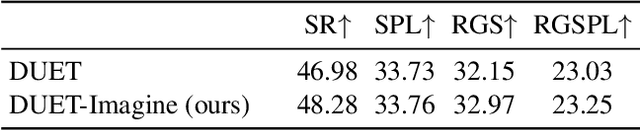
Vision-and-Language Navigation (VLN) agents are tasked with navigating an unseen environment using natural language instructions. In this work, we study if visual representations of sub-goals implied by the instructions can serve as navigational cues and lead to increased navigation performance. To synthesize these visual representations or imaginations, we leverage a text-to-image diffusion model on landmark references contained in segmented instructions. These imaginations are provided to VLN agents as an added modality to act as landmark cues and an auxiliary loss is added to explicitly encourage relating these with their corresponding referring expressions. Our findings reveal an increase in success rate (SR) of around 1 point and up to 0.5 points in success scaled by inverse path length (SPL) across agents. These results suggest that the proposed approach reinforces visual understanding compared to relying on language instructions alone. Code and data for our work can be found at https://www.akhilperincherry.com/VLN-Imagine-website/.
PARTNR: A Benchmark for Planning and Reasoning in Embodied Multi-agent Tasks
Oct 31, 2024
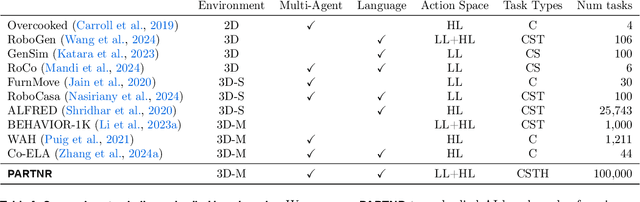

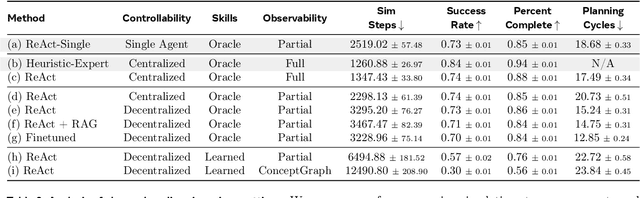
We present a benchmark for Planning And Reasoning Tasks in humaN-Robot collaboration (PARTNR) designed to study human-robot coordination in household activities. PARTNR tasks exhibit characteristics of everyday tasks, such as spatial, temporal, and heterogeneous agent capability constraints. We employ a semi-automated task generation pipeline using Large Language Models (LLMs), incorporating simulation in the loop for grounding and verification. PARTNR stands as the largest benchmark of its kind, comprising 100,000 natural language tasks, spanning 60 houses and 5,819 unique objects. We analyze state-of-the-art LLMs on PARTNR tasks, across the axes of planning, perception and skill execution. The analysis reveals significant limitations in SoTA models, such as poor coordination and failures in task tracking and recovery from errors. When LLMs are paired with real humans, they require 1.5x as many steps as two humans collaborating and 1.1x more steps than a single human, underscoring the potential for improvement in these models. We further show that fine-tuning smaller LLMs with planning data can achieve performance on par with models 9 times larger, while being 8.6x faster at inference. Overall, PARTNR highlights significant challenges facing collaborative embodied agents and aims to drive research in this direction.
Navigating to Objects Specified by Images
Apr 03, 2023
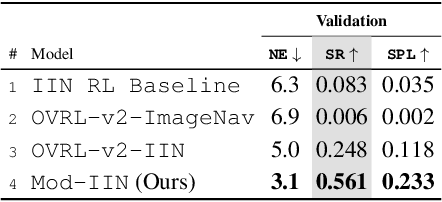
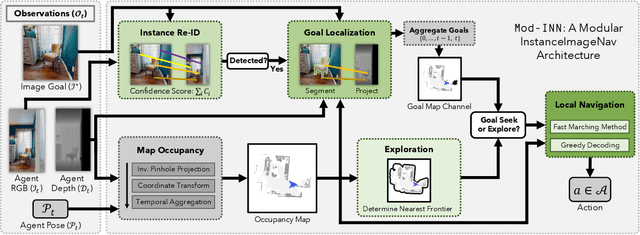
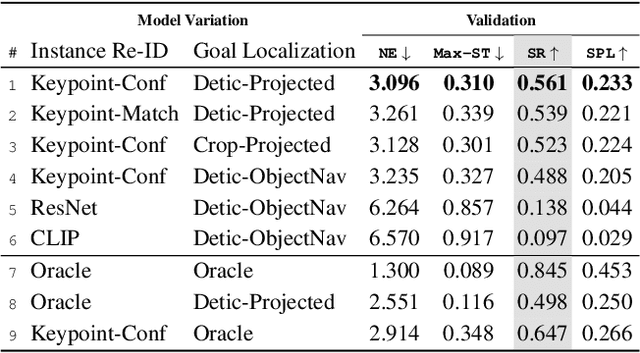
Images are a convenient way to specify which particular object instance an embodied agent should navigate to. Solving this task requires semantic visual reasoning and exploration of unknown environments. We present a system that can perform this task in both simulation and the real world. Our modular method solves sub-tasks of exploration, goal instance re-identification, goal localization, and local navigation. We re-identify the goal instance in egocentric vision using feature-matching and localize the goal instance by projecting matched features to a map. Each sub-task is solved using off-the-shelf components requiring zero fine-tuning. On the HM3D InstanceImageNav benchmark, this system outperforms a baseline end-to-end RL policy 7x and a state-of-the-art ImageNav model 2.3x (56% vs 25% success). We deploy this system to a mobile robot platform and demonstrate effective real-world performance, achieving an 88% success rate across a home and an office environment.
Instance-Specific Image Goal Navigation: Training Embodied Agents to Find Object Instances
Nov 29, 2022
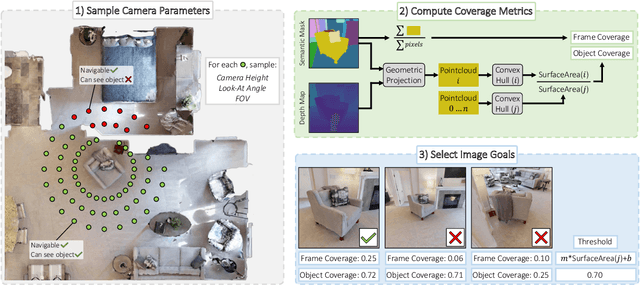
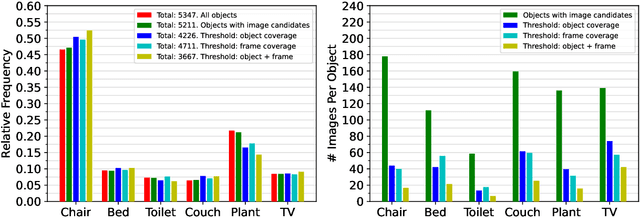

We consider the problem of embodied visual navigation given an image-goal (ImageNav) where an agent is initialized in an unfamiliar environment and tasked with navigating to a location 'described' by an image. Unlike related navigation tasks, ImageNav does not have a standardized task definition which makes comparison across methods difficult. Further, existing formulations have two problematic properties; (1) image-goals are sampled from random locations which can lead to ambiguity (e.g., looking at walls), and (2) image-goals match the camera specification and embodiment of the agent; this rigidity is limiting when considering user-driven downstream applications. We present the Instance-specific ImageNav task (InstanceImageNav) to address these limitations. Specifically, the goal image is 'focused' on some particular object instance in the scene and is taken with camera parameters independent of the agent. We instantiate InstanceImageNav in the Habitat Simulator using scenes from the Habitat-Matterport3D dataset (HM3D) and release a standardized benchmark to measure community progress.
Retrospectives on the Embodied AI Workshop
Oct 17, 2022

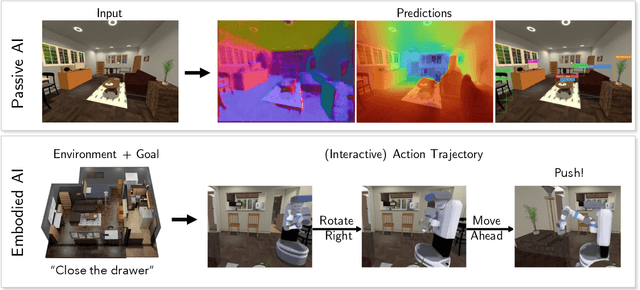
We present a retrospective on the state of Embodied AI research. Our analysis focuses on 13 challenges presented at the Embodied AI Workshop at CVPR. These challenges are grouped into three themes: (1) visual navigation, (2) rearrangement, and (3) embodied vision-and-language. We discuss the dominant datasets within each theme, evaluation metrics for the challenges, and the performance of state-of-the-art models. We highlight commonalities between top approaches to the challenges and identify potential future directions for Embodied AI research.
Iterative Vision-and-Language Navigation
Oct 06, 2022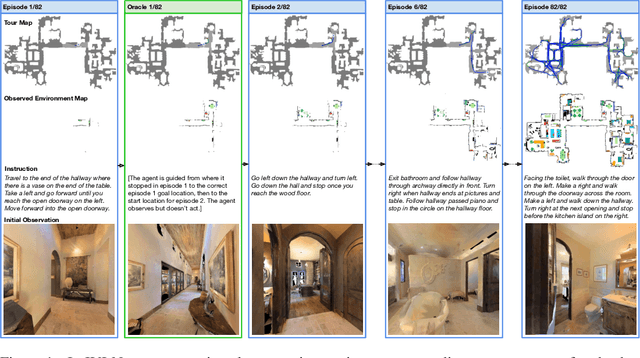
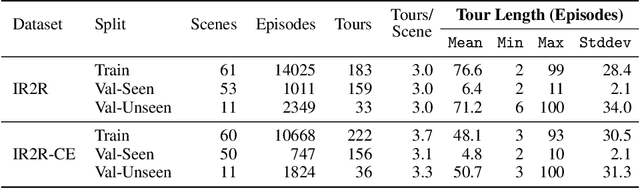
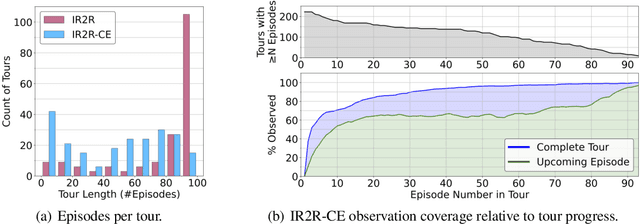

We present Iterative Vision-and-Language Navigation (IVLN), a paradigm for evaluating language-guided agents navigating in a persistent environment over time. Existing Vision-and-Language Navigation (VLN) benchmarks erase the agent's memory at the beginning of every episode, testing the ability to perform cold-start navigation with no prior information. However, deployed robots occupy the same environment for long periods of time. The IVLN paradigm addresses this disparity by training and evaluating VLN agents that maintain memory across tours of scenes that consist of up to 100 ordered instruction-following Room-to-Room (R2R) episodes, each defined by an individual language instruction and a target path. We present discrete and continuous Iterative Room-to-Room (IR2R) benchmarks comprising about 400 tours each in 80 indoor scenes. We find that extending the implicit memory of high-performing transformer VLN agents is not sufficient for IVLN, but agents that build maps can benefit from environment persistence, motivating a renewed focus on map-building agents in VLN.
Sim-2-Sim Transfer for Vision-and-Language Navigation in Continuous Environments
Apr 24, 2022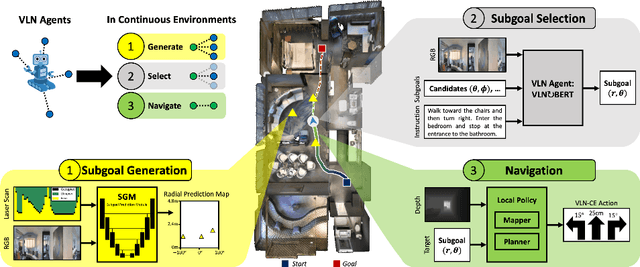
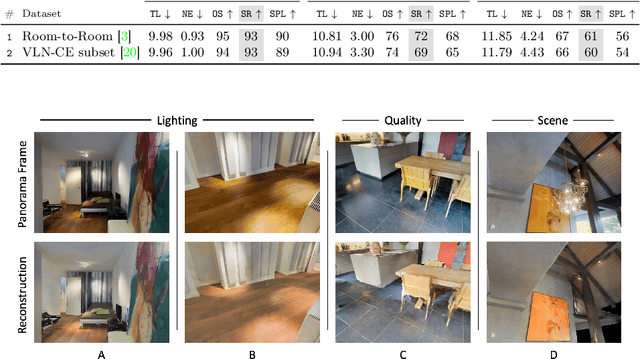


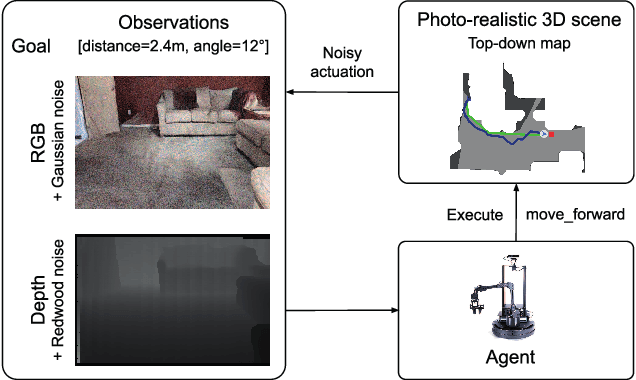
Recent work in Vision-and-Language Navigation (VLN) has presented two environmental paradigms with differing realism -- the standard VLN setting built on topological environments where navigation is abstracted away, and the VLN-CE setting where agents must navigate continuous 3D environments using low-level actions. Despite sharing the high-level task and even the underlying instruction-path data, performance on VLN-CE lags behind VLN significantly. In this work, we explore this gap by transferring an agent from the abstract environment of VLN to the continuous environment of VLN-CE. We find that this sim-2-sim transfer is highly effective, improving over the prior state of the art in VLN-CE by +12% success rate. While this demonstrates the potential for this direction, the transfer does not fully retain the original performance of the agent in the abstract setting. We present a sequence of experiments to identify what differences result in performance degradation, providing clear directions for further improvement.
Waypoint Models for Instruction-guided Navigation in Continuous Environments
Oct 05, 2021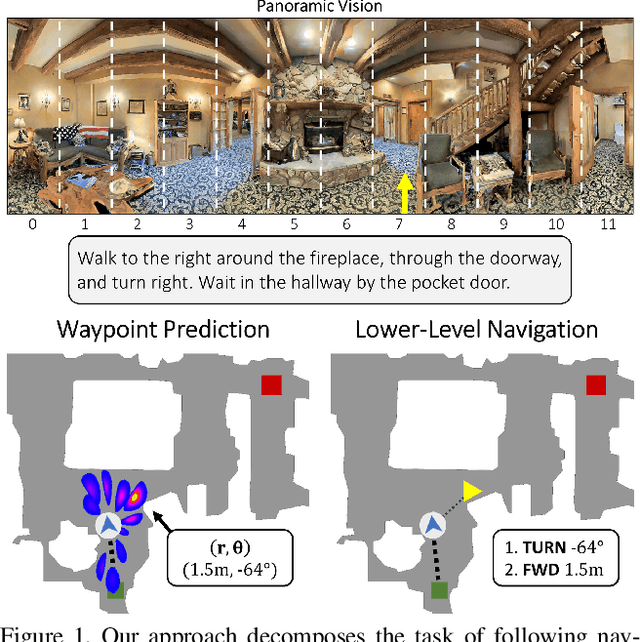
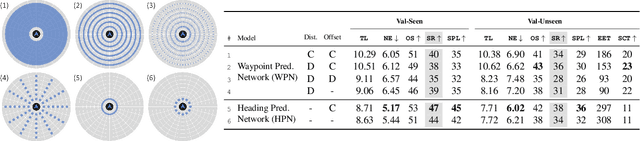
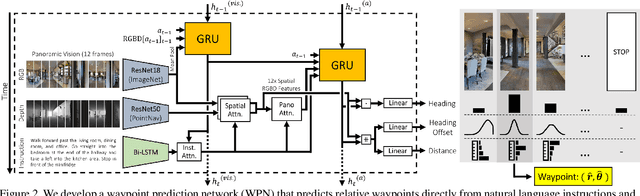

Little inquiry has explicitly addressed the role of action spaces in language-guided visual navigation -- either in terms of its effect on navigation success or the efficiency with which a robotic agent could execute the resulting trajectory. Building on the recently released VLN-CE setting for instruction following in continuous environments, we develop a class of language-conditioned waypoint prediction networks to examine this question. We vary the expressivity of these models to explore a spectrum between low-level actions and continuous waypoint prediction. We measure task performance and estimated execution time on a profiled LoCoBot robot. We find more expressive models result in simpler, faster to execute trajectories, but lower-level actions can achieve better navigation metrics by approximating shortest paths better. Further, our models outperform prior work in VLN-CE and set a new state-of-the-art on the public leaderboard -- increasing success rate by 4% with our best model on this challenging task.
Where Are You? Localization from Embodied Dialog
Nov 16, 2020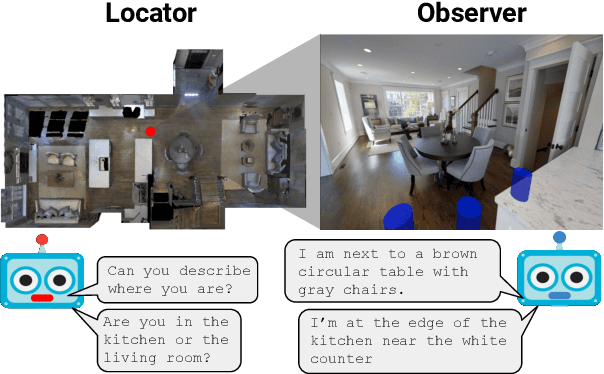
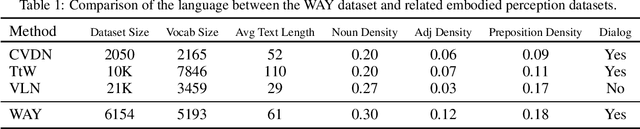
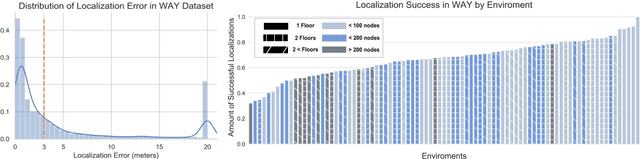
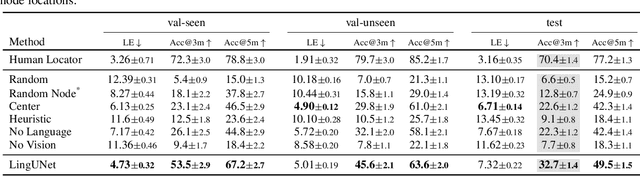
We present Where Are You? (WAY), a dataset of ~6k dialogs in which two humans -- an Observer and a Locator -- complete a cooperative localization task. The Observer is spawned at random in a 3D environment and can navigate from first-person views while answering questions from the Locator. The Locator must localize the Observer in a detailed top-down map by asking questions and giving instructions. Based on this dataset, we define three challenging tasks: Localization from Embodied Dialog or LED (localizing the Observer from dialog history), Embodied Visual Dialog (modeling the Observer), and Cooperative Localization (modeling both agents). In this paper, we focus on the LED task -- providing a strong baseline model with detailed ablations characterizing both dataset biases and the importance of various modeling choices. Our best model achieves 32.7% success at identifying the Observer's location within 3m in unseen buildings, vs. 70.4% for human Locators.
Beyond the Nav-Graph: Vision-and-Language Navigation in Continuous Environments
Apr 06, 2020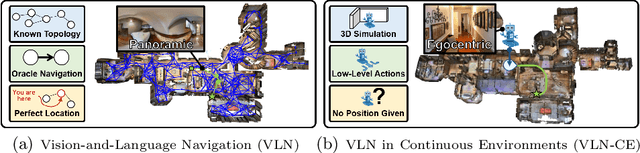


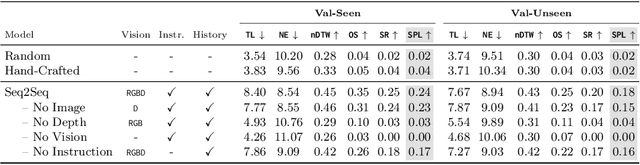
We develop a language-guided navigation task set in a continuous 3D environment where agents must execute low-level actions to follow natural language navigation directions. By being situated in continuous environments, this setting lifts a number of assumptions implicit in prior work that represents environments as a sparse graph of panoramas with edges corresponding to navigability. Specifically, our setting drops the presumptions of known environment topologies, short-range oracle navigation, and perfect agent localization. To contextualize this new task, we develop models that mirror many of the advances made in prior settings as well as single-modality baselines. While some of these techniques transfer, we find significantly lower absolute performance in the continuous setting -- suggesting that performance in prior `navigation-graph' settings may be inflated by the strong implicit assumptions.