 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSim-2-Sim Transfer for Vision-and-Language Navigation in Continuous Environments
Paper and Code
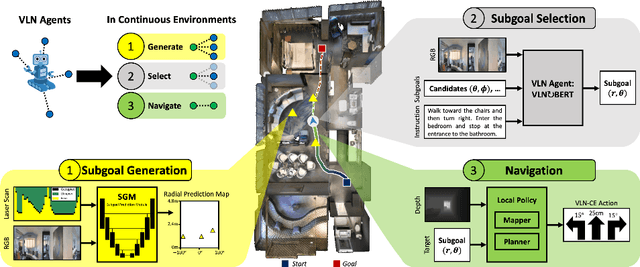
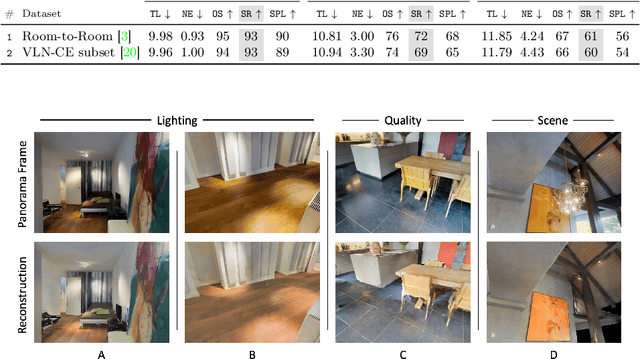


Recent work in Vision-and-Language Navigation (VLN) has presented two environmental paradigms with differing realism -- the standard VLN setting built on topological environments where navigation is abstracted away, and the VLN-CE setting where agents must navigate continuous 3D environments using low-level actions. Despite sharing the high-level task and even the underlying instruction-path data, performance on VLN-CE lags behind VLN significantly. In this work, we explore this gap by transferring an agent from the abstract environment of VLN to the continuous environment of VLN-CE. We find that this sim-2-sim transfer is highly effective, improving over the prior state of the art in VLN-CE by +12% success rate. While this demonstrates the potential for this direction, the transfer does not fully retain the original performance of the agent in the abstract setting. We present a sequence of experiments to identify what differences result in performance degradation, providing clear directions for further improvement.