 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-Judge: Can Omni-LLMs Serve as Human-Aligned Judges for Text-Conditioned Audio-Video Generation?
Feb 02, 2026State-of-the-art text-to-video generation models such as Sora 2 and Veo 3 can now produce high-fidelity videos with synchronized audio directly from a textual prompt, marking a new milestone in multi-modal generation. However, evaluating such tri-modal outputs remains an unsolved challenge. Human evaluation is reliable but costly and difficult to scale, while traditional automatic metrics, such as FVD, CLAP, and ViCLIP, focus on isolated modality pairs, struggle with complex prompts, and provide limited interpretability. Omni-modal large language models (omni-LLMs) present a promising alternative: they naturally process audio, video, and text, support rich reasoning, and offer interpretable chain-of-thought feedback. Driven by this, we introduce Omni-Judge, a study assessing whether omni-LLMs can serve as human-aligned judges for text-conditioned audio-video generation. Across nine perceptual and alignment metrics, Omni-Judge achieves correlation comparable to traditional metrics and excels on semantically demanding tasks such as audio-text alignment, video-text alignment, and audio-video-text coherence. It underperforms on high-FPS perceptual metrics, including video quality and audio-video synchronization, due to limited temporal resolution. Omni-Judge provides interpretable explanations that expose semantic or physical inconsistencies, enabling practical downstream uses such as feedback-based refinement. Our findings highlight both the potential and current limitations of omni-LLMs as unified evaluators for multi-modal generation.
Iterative Vision-and-Language Navigation
Oct 06, 2022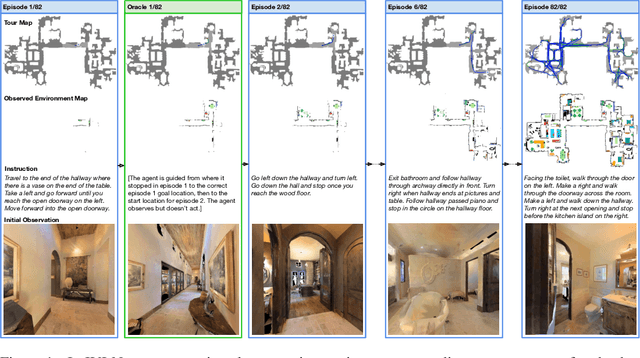
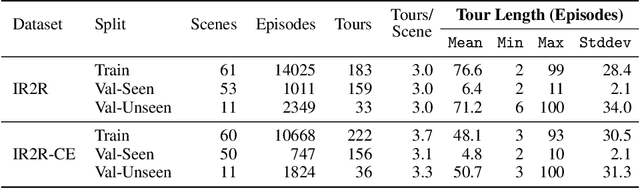
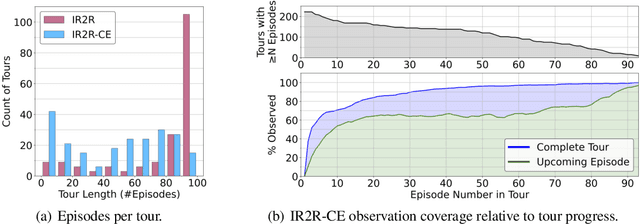

We present Iterative Vision-and-Language Navigation (IVLN), a paradigm for evaluating language-guided agents navigating in a persistent environment over time. Existing Vision-and-Language Navigation (VLN) benchmarks erase the agent's memory at the beginning of every episode, testing the ability to perform cold-start navigation with no prior information. However, deployed robots occupy the same environment for long periods of time. The IVLN paradigm addresses this disparity by training and evaluating VLN agents that maintain memory across tours of scenes that consist of up to 100 ordered instruction-following Room-to-Room (R2R) episodes, each defined by an individual language instruction and a target path. We present discrete and continuous Iterative Room-to-Room (IR2R) benchmarks comprising about 400 tours each in 80 indoor scenes. We find that extending the implicit memory of high-performing transformer VLN agents is not sufficient for IVLN, but agents that build maps can benefit from environment persistence, motivating a renewed focus on map-building agents in VLN.
Cross-View Exocentric to Egocentric Video Synthesis
Jul 07, 2021

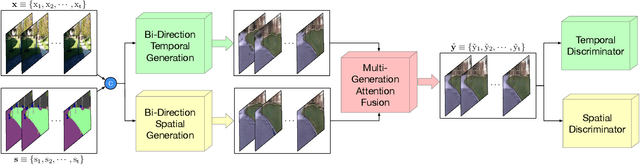

Cross-view video synthesis task seeks to generate video sequences of one view from another dramatically different view. In this paper, we investigate the exocentric (third-person) view to egocentric (first-person) view video generation task. This is challenging because egocentric view sometimes is remarkably different from the exocentric view. Thus, transforming the appearances across the two different views is a non-trivial task. Particularly, we propose a novel Bi-directional Spatial Temporal Attention Fusion Generative Adversarial Network (STA-GAN) to learn both spatial and temporal information to generate egocentric video sequences from the exocentric view. The proposed STA-GAN consists of three parts: temporal branch, spatial branch, and attention fusion. First, the temporal and spatial branches generate a sequence of fake frames and their corresponding features. The fake frames are generated in both downstream and upstream directions for both temporal and spatial branches. Next, the generated four different fake frames and their corresponding features (spatial and temporal branches in two directions) are fed into a novel multi-generation attention fusion module to produce the final video sequence. Meanwhile, we also propose a novel temporal and spatial dual-discriminator for more robust network optimization. Extensive experiments on the Side2Ego and Top2Ego datasets show that the proposed STA-GAN significantly outperforms the existing methods.
ViP: Video Platform for PyTorch
Oct 07, 2019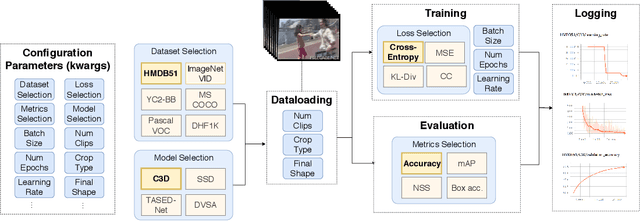

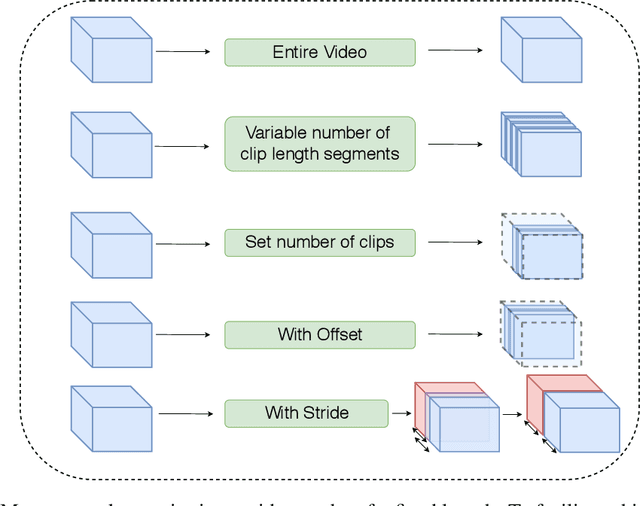
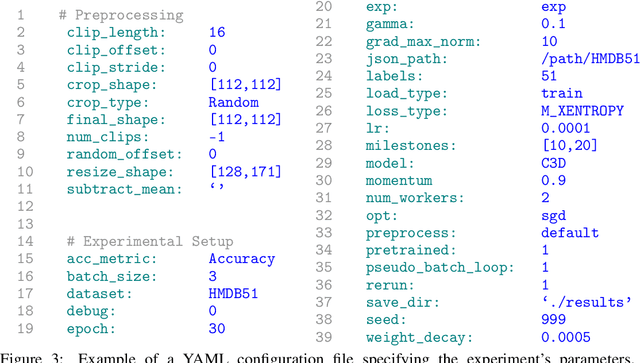
This work presents the Video Platform for PyTorch (ViP), a deep learning-based framework designed to handle and extend to any problem domain based on videos. ViP supports (1) a single unified interface applicable to all video problem domains, (2) quick prototyping of video models, (3) executing large-batch operations with reduced memory consumption, and (4) easy and reproducible experimental setups. ViP's core functionality is built with flexibility and modularity in mind to allow for smooth data flow between different parts of the platform and benchmarking against existing methods. In providing a software platform that supports multiple video-based problem domains, we allow for more cross-pollination of models, ideas and stronger generalization in the video understanding research community.
Greedy Multiple Instance Learning via Codebook Learning and Nearest Neighbor Voting
May 03, 2012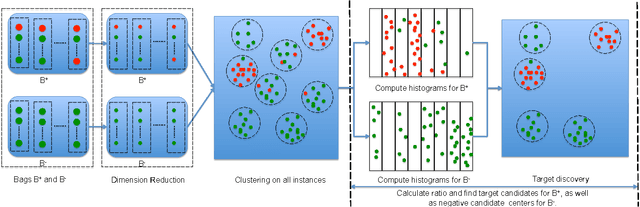
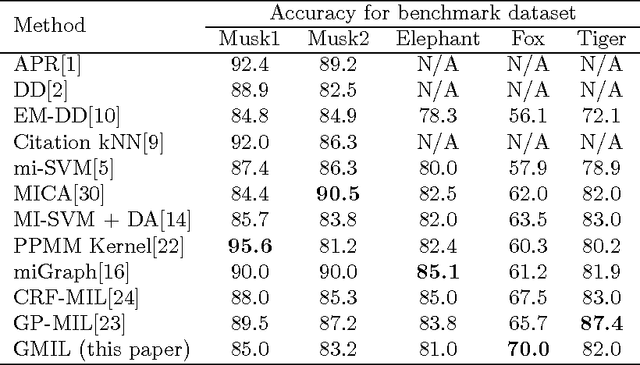
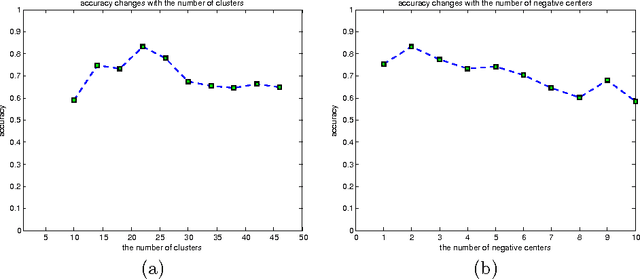
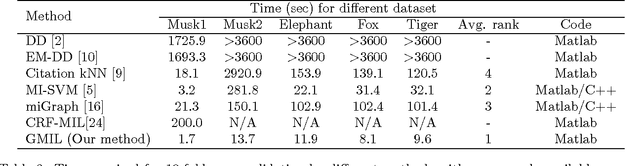
Multiple instance learning (MIL) has attracted great attention recently in machine learning community. However, most MIL algorithms are very slow and cannot be applied to large datasets. In this paper, we propose a greedy strategy to speed up the multiple instance learning process. Our contribution is two fold. First, we propose a density ratio model, and show that maximizing a density ratio function is the low bound of the DD model under certain conditions. Secondly, we make use of a histogram ratio between positive bags and negative bags to represent the density ratio function and find codebooks separately for positive bags and negative bags by a greedy strategy. For testing, we make use of a nearest neighbor strategy to classify new bags. We test our method on both small benchmark datasets and the large TRECVID MED11 dataset. The experimental results show that our method yields comparable accuracy to the current state of the art, while being up to at least one order of magnitude faster.