 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperCLIP: Adapting Vision-Language models with Hypernetworks
Dec 21, 2024Self-supervised vision-language models trained with contrastive objectives form the basis of current state-of-the-art methods in AI vision tasks. The success of these models is a direct consequence of the huge web-scale datasets used to train them, but they require correspondingly large vision components to properly learn powerful and general representations from such a broad data domain. This poses a challenge for deploying large vision-language models, especially in resource-constrained environments. To address this, we propose an alternate vision-language architecture, called HyperCLIP, that uses a small image encoder along with a hypernetwork that dynamically adapts image encoder weights to each new set of text inputs. All three components of the model (hypernetwork, image encoder, and text encoder) are pre-trained jointly end-to-end, and with a trained HyperCLIP model, we can generate new zero-shot deployment-friendly image classifiers for any task with a single forward pass through the text encoder and hypernetwork. HyperCLIP increases the zero-shot accuracy of SigLIP trained models with small image encoders by up to 3% on ImageNet and 5% on CIFAR-100 with minimal training throughput overhead.
Leveraging Foundation Models to Improve Lightweight Clients in Federated Learning
Nov 14, 2023Federated Learning (FL) is a distributed training paradigm that enables clients scattered across the world to cooperatively learn a global model without divulging confidential data. However, FL faces a significant challenge in the form of heterogeneous data distributions among clients, which leads to a reduction in performance and robustness. A recent approach to mitigating the impact of heterogeneous data distributions is through the use of foundation models, which offer better performance at the cost of larger computational overheads and slower inference speeds. We introduce foundation model distillation to assist in the federated training of lightweight client models and increase their performance under heterogeneous data settings while keeping inference costs low. Our results show improvement in the global model performance on a balanced testing set, which contains rarely observed samples, even under extreme non-IID client data distributions. We conduct a thorough evaluation of our framework with different foundation model backbones on CIFAR10, with varying degrees of heterogeneous data distributions ranging from class-specific data partitions across clients to dirichlet data sampling, parameterized by values between 0.01 and 1.0.
Text-driven Prompt Generation for Vision-Language Models in Federated Learning
Oct 09, 2023



Prompt learning for vision-language models, e.g., CoOp, has shown great success in adapting CLIP to different downstream tasks, making it a promising solution for federated learning due to computational reasons. Existing prompt learning techniques replace hand-crafted text prompts with learned vectors that offer improvements on seen classes, but struggle to generalize to unseen classes. Our work addresses this challenge by proposing Federated Text-driven Prompt Generation (FedTPG), which learns a unified prompt generation network across multiple remote clients in a scalable manner. The prompt generation network is conditioned on task-related text input, thus is context-aware, making it suitable to generalize for both seen and unseen classes. Our comprehensive empirical evaluations on nine diverse image classification datasets show that our method is superior to existing federated prompt learning methods, that achieve overall better generalization on both seen and unseen classes and is also generalizable to unseen datasets.
Q-TART: Quickly Training for Adversarial Robustness and in-Transferability
Apr 14, 2022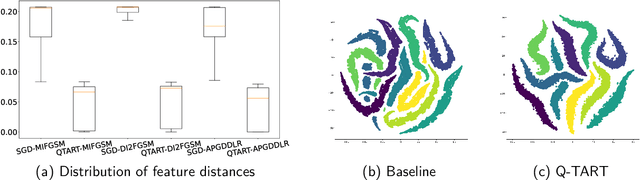
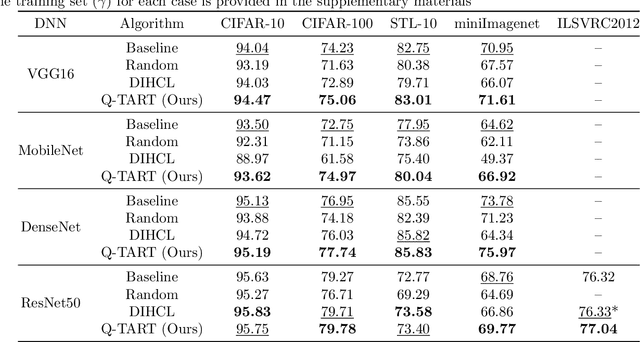
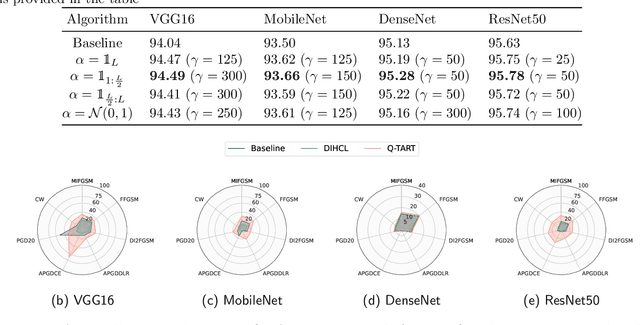
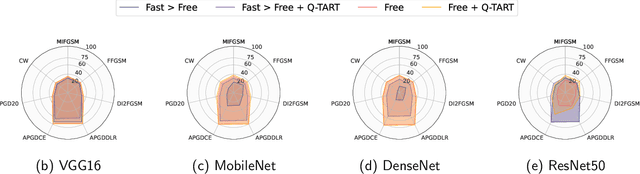
Raw deep neural network (DNN) performance is not enough; in real-world settings, computational load, training efficiency and adversarial security are just as or even more important. We propose to simultaneously tackle Performance, Efficiency, and Robustness, using our proposed algorithm Q-TART, Quickly Train for Adversarial Robustness and in-Transferability. Q-TART follows the intuition that samples highly susceptible to noise strongly affect the decision boundaries learned by DNNs, which in turn degrades their performance and adversarial susceptibility. By identifying and removing such samples, we demonstrate improved performance and adversarial robustness while using only a subset of the training data. Through our experiments we highlight Q-TART's high performance across multiple Dataset-DNN combinations, including ImageNet, and provide insights into the complementary behavior of Q-TART alongside existing adversarial training approaches to increase robustness by over 1.3% while using up to 17.9% less training time.
Slimming Neural Networks using Adaptive Connectivity Scores
Jun 26, 2020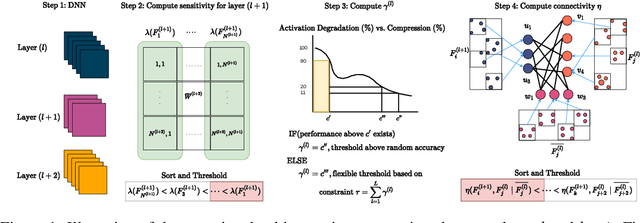

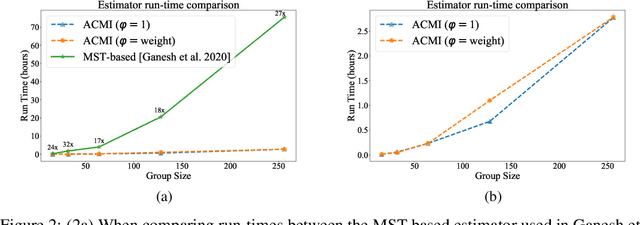
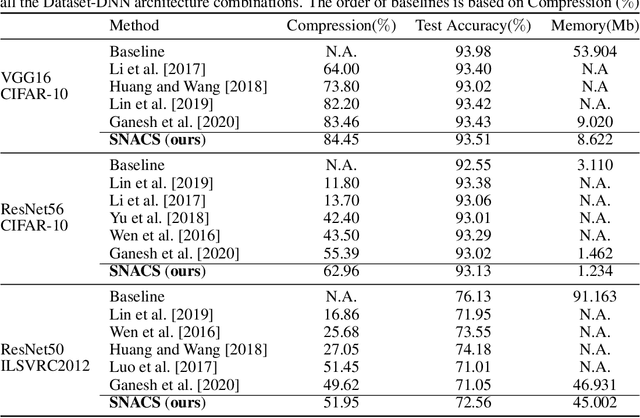
There are two broad approaches to deep neural network (DNN) pruning: 1) applying a deterministic constraint on the weight matrices, which takes advantage of their ease of implementation and the learned structures of the weight matrix, and 2) using a probabilistic framework aimed at maintaining the flow of information between layers, which leverages the connections between filters and their downstream impact. Each approach's advantage supplements the missing portions of the alternate approach yet no one has combined and fully capitalized on both of them. Further,there are some common practical issues that affect both, e.g., intense manual effort to analyze sensitivity and set the upper pruning limits of layers. In this work,we propose Slimming Neural networks using Adaptive Connectivity Measures(SNACS), as an algorithm that uses a probabilistic framework for compression while incorporating weight-based constraints at multiple levels to capitalize on both their strengths and overcome previous issues. We propose a hash-based estimator of Adaptive Conditional Mutual Information(ACMI) to evaluate the connectivity between filters of different layers, which includes a magnitude-based scaling criteria that leverages weight matrices. To reduce the amount of unnecessary manual effort required to set the upper pruning limit of different layers in a DNN we propose a set of operating constraints to help automatically set them. Further, we take extended advantage of weight matrices by defining a sensitivity criteria for filters that measures the strength of their contributions to the following layer and highlights critical filters that need to be protected from pruning. We show that our proposed approach is faster by over 17x the nearest comparable method and outperforms all existing pruning approaches on three standard Dataset-DNN benchmarks: CIFAR10-VGG16, CIFAR10-ResNet56 and ILSVRC2012-ResNet50.
MINT: Deep Network Compression via Mutual Information-based Neuron Trimming
Mar 18, 2020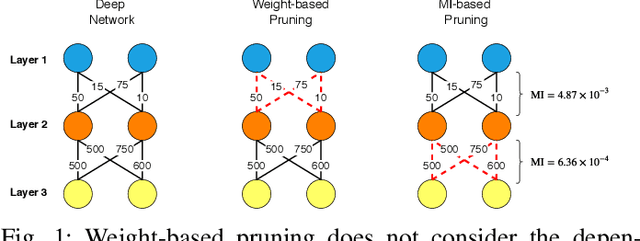
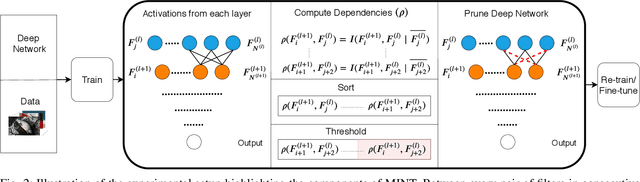
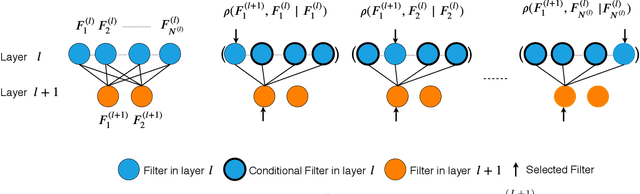
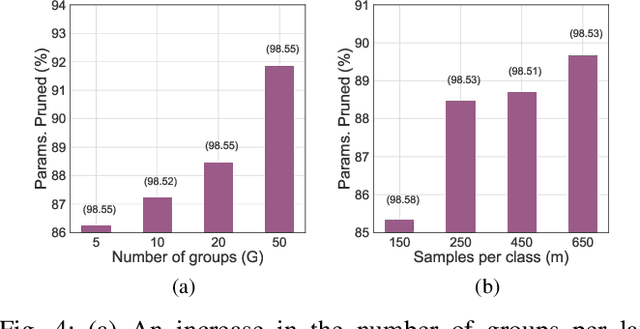
Most approaches to deep neural network compression via pruning either evaluate a filter's importance using its weights or optimize an alternative objective function with sparsity constraints. While these methods offer a useful way to approximate contributions from similar filters, they often either ignore the dependency between layers or solve a more difficult optimization objective than standard cross-entropy. Our method, Mutual Information-based Neuron Trimming (MINT), approaches deep compression via pruning by enforcing sparsity based on the strength of the relationship between filters of adjacent layers, across every pair of layers. The relationship is calculated using conditional geometric mutual information which evaluates the amount of similar information exchanged between the filters using a graph-based criterion. When pruning a network, we ensure that retained filters contribute the majority of the information towards succeeding layers which ensures high performance. Our novel approach outperforms existing state-of-the-art compression-via-pruning methods on the standard benchmarks for this task: MNIST, CIFAR-10, and ILSVRC2012, across a variety of network architectures. In addition, we discuss our observations of a common denominator between our pruning methodology's response to adversarial attacks and calibration statistics when compared to the original network.
Rethinking Curriculum Learning with Incremental Labels and Adaptive Compensation
Jan 13, 2020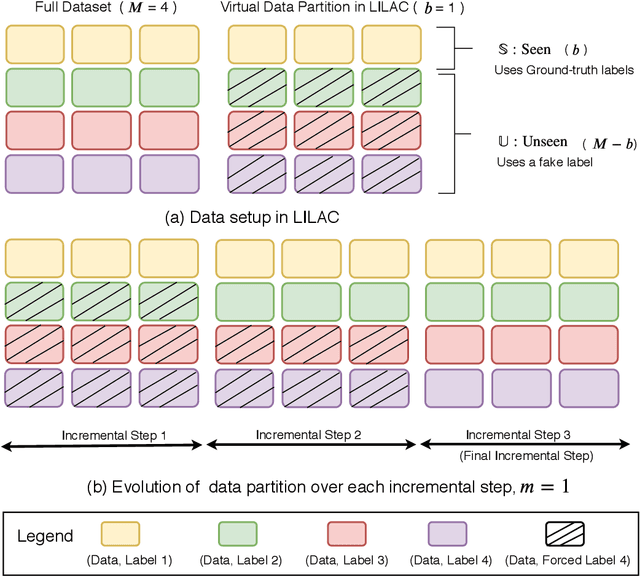
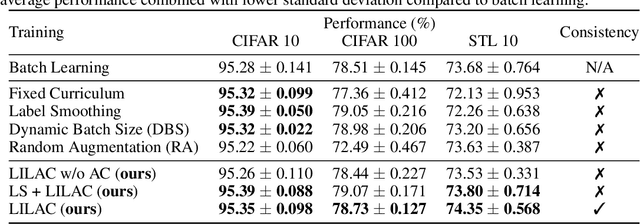
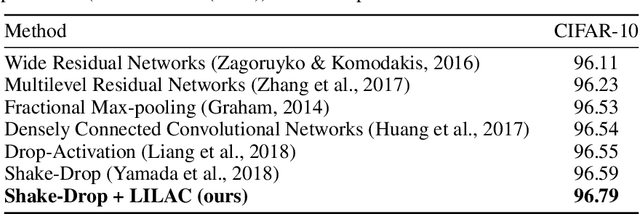
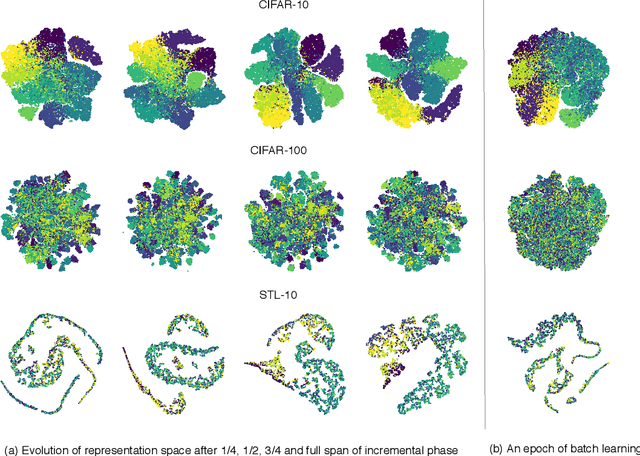
Like humans, deep networks learn better when samples are organized and introduced in a meaningful order or curriculum (Weinshall et al., 2018). While con-ventional approaches to curriculum learning emphasize the difficulty of samples as the core incremental strategy, it forces networks to learn from small subsets of data while introducing pre-computation overheads. In this work, we propose Learning with Incremental Labels and Adaptive Compensation(LILAC), which takes a novel approach to curriculum learning. LILAC emphasizes incrementally learning labels instead of incrementally learning difficult samples. It works in two distinct phases: first, in the incremental label introduction phase, we recursively reveal ground-truth labels in small installments while using a fake label for the remaining data. In the adaptive compensation phase, we compensate for failed predictions by adaptively altering the target vector to a smoother distribution. We evaluate LILAC against the closest comparable methods in batch and curriculum learning and label smoothing, across three standard image benchmarks, CIFAR-10, CIFAR-100, and STL-10. We show that our method outperforms batch learning with higher mean recognition accuracy as well as lower standard deviation in performance consistently across all benchmarks. We further extend LILAC to show the highest performance on CIFAR-10 for methods using simple data augmentation while exhibiting label-order invariance among other properties.
ViP: Video Platform for PyTorch
Oct 07, 2019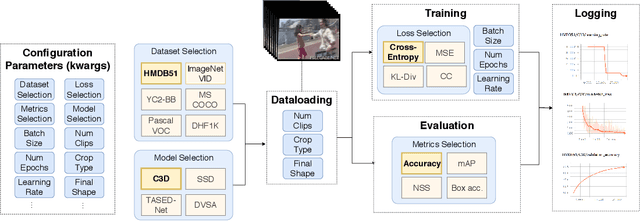

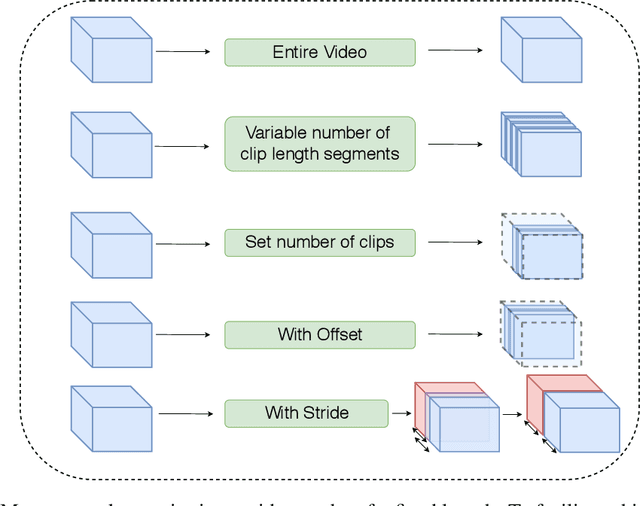
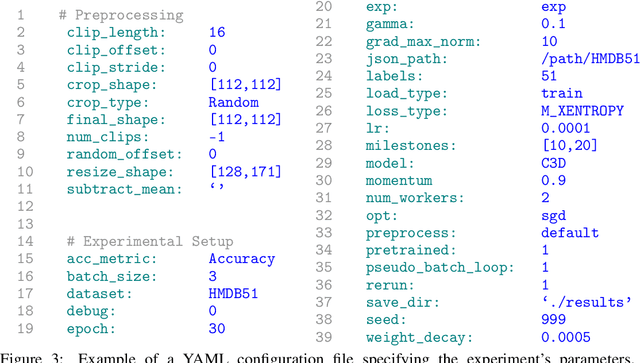
This work presents the Video Platform for PyTorch (ViP), a deep learning-based framework designed to handle and extend to any problem domain based on videos. ViP supports (1) a single unified interface applicable to all video problem domains, (2) quick prototyping of video models, (3) executing large-batch operations with reduced memory consumption, and (4) easy and reproducible experimental setups. ViP's core functionality is built with flexibility and modularity in mind to allow for smooth data flow between different parts of the platform and benchmarking against existing methods. In providing a software platform that supports multiple video-based problem domains, we allow for more cross-pollination of models, ideas and stronger generalization in the video understanding research community.
Geometric Online Adaptation: Graph-Based OSFS for Streaming Samples
Oct 02, 2019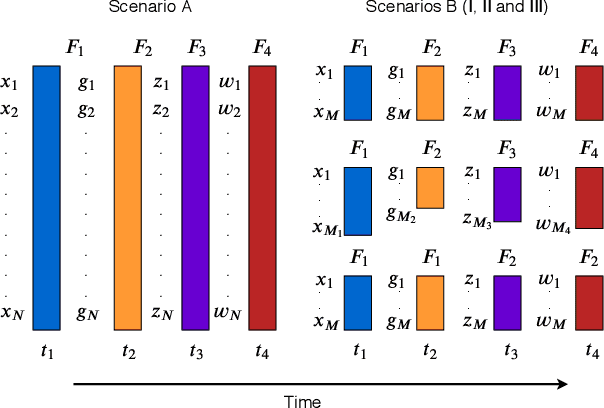
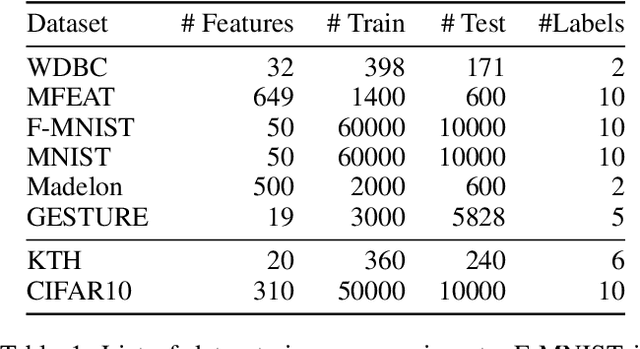
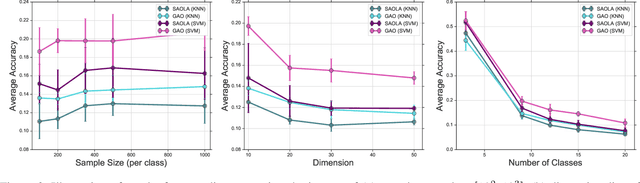
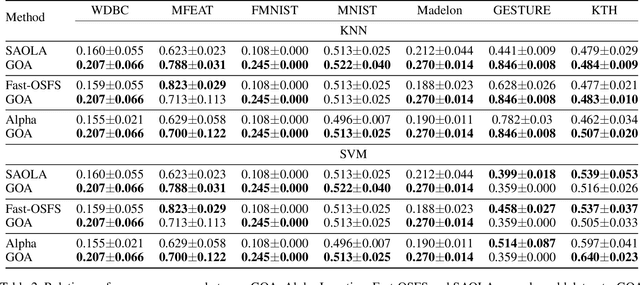
Feature selection seeks a curated subset of available features such that they contain sufficient discriminative information for a given learning task. Online streaming feature selection (OSFS) further extends this to the streaming scenario where the model gets only a single pass at features, one at a time. While this problem setting allows for training high performance models with low computational and storage requirements, this setting also makes the assumption that there is a fixed number of samples, which is often invalidated in many real-world problems. In this paper, we consider a new setting called Online Streaming Feature Selection with Streaming Samples (OSFS-SS) with a fixed class label space, where both the features and the samples are simultaneously streamed. We extend the state-of-the-art OSFS method to work in this setting. Furthermore, we introduce a novel algorithm, that has applications in both the OSFS and OSFS-SS settings, called Geometric Online Adaptation (GOA) which uses a graph-based class conditional geometric dependency (CGD) criterion to measure feature relevance and maintain a minimal feature subset with relatively high classification performance. We evaluate the proposed GOA algorithm on both simulation and real world datasets highlighting how in both the OSFS and OSFS-SS settings it achieves higher performance while maintaining smaller feature subsets than relevant baselines.
M-PACT: An Open Source Platform for Repeatable Activity Classification Research
Oct 05, 2018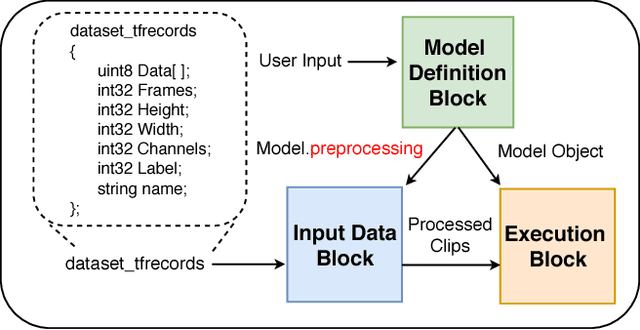
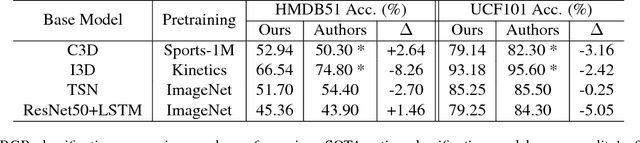

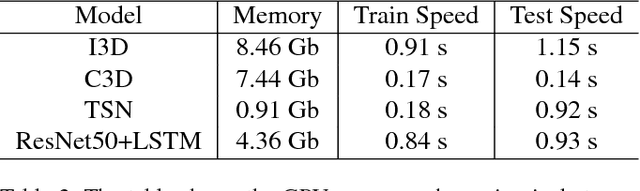
There are many hurdles that prevent the replication of existing work which hinders the development of new activity classification models. These hurdles include switching between multiple deep learning libraries and the development of boilerplate experimental pipelines. We present M-PACT to overcome existing issues by removing the need to develop boilerplate code which allows users to quickly prototype action classification models while leveraging existing state-of-the-art (SOTA) models available in the platform. M-PACT is the first to offer four SOTA activity classification models, I3D, C3D, ResNet50+LSTM, and TSN, under a single platform with reproducible competitive results. This platform allows for the generation of models and results over activity recognition datasets through the use of modular code, various preprocessing and neural network layers, and seamless data flow. In this paper, we present the system architecture, detail the functions of various modules, and describe the basic tools to develop a new model in M-PACT.