 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperCLIP: Adapting Vision-Language models with Hypernetworks
Dec 21, 2024Self-supervised vision-language models trained with contrastive objectives form the basis of current state-of-the-art methods in AI vision tasks. The success of these models is a direct consequence of the huge web-scale datasets used to train them, but they require correspondingly large vision components to properly learn powerful and general representations from such a broad data domain. This poses a challenge for deploying large vision-language models, especially in resource-constrained environments. To address this, we propose an alternate vision-language architecture, called HyperCLIP, that uses a small image encoder along with a hypernetwork that dynamically adapts image encoder weights to each new set of text inputs. All three components of the model (hypernetwork, image encoder, and text encoder) are pre-trained jointly end-to-end, and with a trained HyperCLIP model, we can generate new zero-shot deployment-friendly image classifiers for any task with a single forward pass through the text encoder and hypernetwork. HyperCLIP increases the zero-shot accuracy of SigLIP trained models with small image encoders by up to 3% on ImageNet and 5% on CIFAR-100 with minimal training throughput overhead.
Dynamic Batch Norm Statistics Update for Natural Robustness
Oct 31, 2023DNNs trained on natural clean samples have been shown to perform poorly on corrupted samples, such as noisy or blurry images. Various data augmentation methods have been recently proposed to improve DNN's robustness against common corruptions. Despite their success, they require computationally expensive training and cannot be applied to off-the-shelf trained models. Recently, it has been shown that updating BatchNorm (BN) statistics of an off-the-shelf model on a single corruption improves its accuracy on that corruption significantly. However, adopting the idea at inference time when the type of corruption is unknown and changing decreases the effectiveness of this method. In this paper, we harness the Fourier domain to detect the corruption type, a challenging task in the image domain. We propose a unified framework consisting of a corruption-detection model and BN statistics update that improves the corruption accuracy of any off-the-shelf trained model. We benchmark our framework on different models and datasets. Our results demonstrate about 8% and 4% accuracy improvement on CIFAR10-C and ImageNet-C, respectively. Furthermore, our framework can further improve the accuracy of state-of-the-art robust models, such as AugMix and DeepAug.
A deep active learning system for species identification and counting in camera trap images
Oct 22, 2019

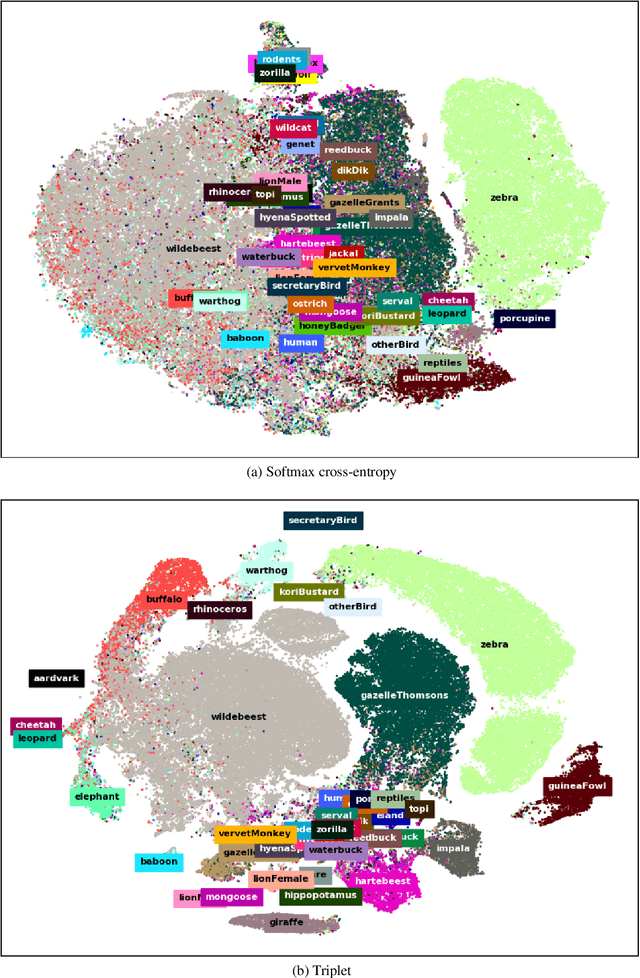
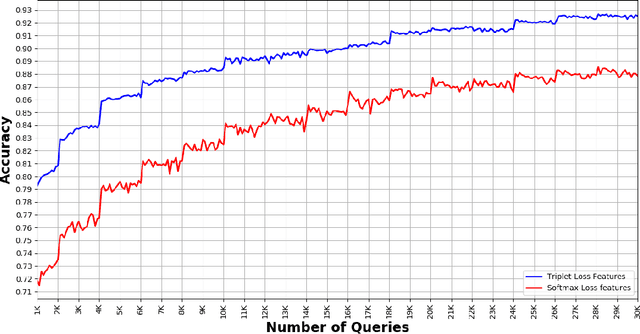
Biodiversity conservation depends on accurate, up-to-date information about wildlife population distributions. Motion-activated cameras, also known as camera traps, are a critical tool for population surveys, as they are cheap and non-intrusive. However, extracting useful information from camera trap images is a cumbersome process: a typical camera trap survey may produce millions of images that require slow, expensive manual review. Consequently, critical information is often lost due to resource limitations, and critical conservation questions may be answered too slowly to support decision-making. Computer vision is poised to dramatically increase efficiency in image-based biodiversity surveys, and recent studies have harnessed deep learning techniques for automatic information extraction from camera trap images. However, the accuracy of results depends on the amount, quality, and diversity of the data available to train models, and the literature has focused on projects with millions of relevant, labeled training images. Many camera trap projects do not have a large set of labeled images and hence cannot benefit from existing machine learning techniques. Furthermore, even projects that do have labeled data from similar ecosystems have struggled to adopt deep learning methods because image classification models overfit to specific image backgrounds (i.e., camera locations). In this paper, we focus not on automating the labeling of camera trap images, but on accelerating this process. We combine the power of machine intelligence and human intelligence to build a scalable, fast, and accurate active learning system to minimize the manual work required to identify and count animals in camera trap images. Our proposed scheme can match the state of the art accuracy on a 3.2 million image dataset with as few as 14,100 manual labels, which means decreasing manual labeling effort by over 99.5%.