 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperCLIP: Adapting Vision-Language models with Hypernetworks
Dec 21, 2024Self-supervised vision-language models trained with contrastive objectives form the basis of current state-of-the-art methods in AI vision tasks. The success of these models is a direct consequence of the huge web-scale datasets used to train them, but they require correspondingly large vision components to properly learn powerful and general representations from such a broad data domain. This poses a challenge for deploying large vision-language models, especially in resource-constrained environments. To address this, we propose an alternate vision-language architecture, called HyperCLIP, that uses a small image encoder along with a hypernetwork that dynamically adapts image encoder weights to each new set of text inputs. All three components of the model (hypernetwork, image encoder, and text encoder) are pre-trained jointly end-to-end, and with a trained HyperCLIP model, we can generate new zero-shot deployment-friendly image classifiers for any task with a single forward pass through the text encoder and hypernetwork. HyperCLIP increases the zero-shot accuracy of SigLIP trained models with small image encoders by up to 3% on ImageNet and 5% on CIFAR-100 with minimal training throughput overhead.
Finetuning CLIP to Reason about Pairwise Differences
Sep 15, 2024

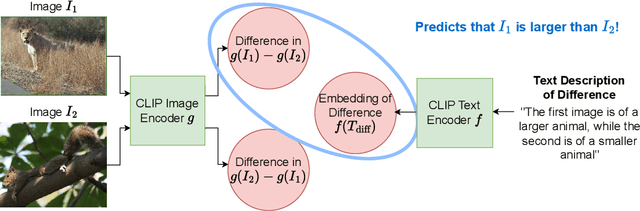

Vision-language models (VLMs) such as CLIP are trained via contrastive learning between text and image pairs, resulting in aligned image and text embeddings that are useful for many downstream tasks. A notable drawback of CLIP, however, is that the resulting embedding space seems to lack some of the structure of their purely text-based alternatives. For instance, while text embeddings have been long noted to satisfy \emph{analogies} in embedding space using vector arithmetic, CLIP has no such property. In this paper, we propose an approach to natively train CLIP in a contrastive manner to reason about differences in embedding space. We finetune CLIP so that the differences in image embedding space correspond to \emph{text descriptions of the image differences}, which we synthetically generate with large language models on image-caption paired datasets. We first demonstrate that our approach yields significantly improved capabilities in ranking images by a certain attribute (e.g., elephants are larger than cats), which is useful in retrieval or constructing attribute-based classifiers, and improved zeroshot classification performance on many downstream image classification tasks. In addition, our approach enables a new mechanism for inference that we refer to as comparative prompting, where we leverage prior knowledge of text descriptions of differences between classes of interest, achieving even larger performance gains in classification. Finally, we illustrate that the resulting embeddings obey a larger degree of geometric properties in embedding space, such as in text-to-image generation.
Leveraging Foundation Models to Improve Lightweight Clients in Federated Learning
Nov 14, 2023Federated Learning (FL) is a distributed training paradigm that enables clients scattered across the world to cooperatively learn a global model without divulging confidential data. However, FL faces a significant challenge in the form of heterogeneous data distributions among clients, which leads to a reduction in performance and robustness. A recent approach to mitigating the impact of heterogeneous data distributions is through the use of foundation models, which offer better performance at the cost of larger computational overheads and slower inference speeds. We introduce foundation model distillation to assist in the federated training of lightweight client models and increase their performance under heterogeneous data settings while keeping inference costs low. Our results show improvement in the global model performance on a balanced testing set, which contains rarely observed samples, even under extreme non-IID client data distributions. We conduct a thorough evaluation of our framework with different foundation model backbones on CIFAR10, with varying degrees of heterogeneous data distributions ranging from class-specific data partitions across clients to dirichlet data sampling, parameterized by values between 0.01 and 1.0.
Understanding the Covariance Structure of Convolutional Filters
Oct 07, 2022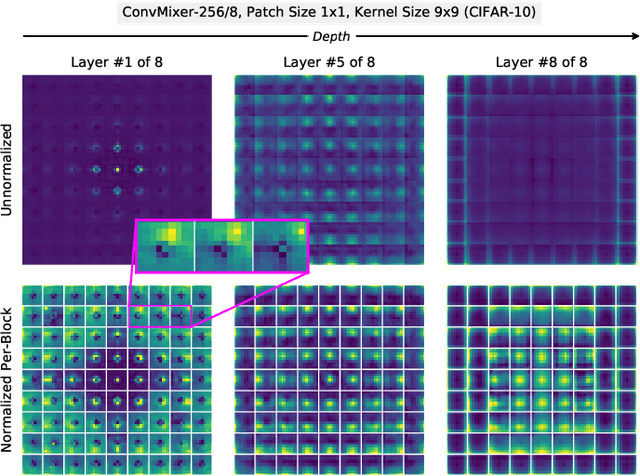
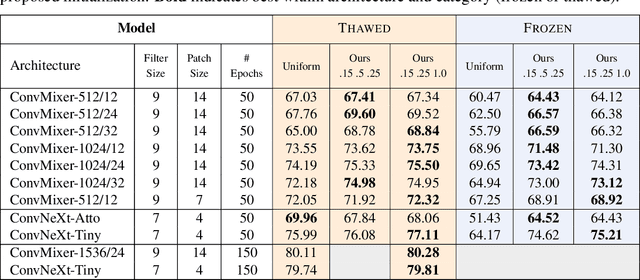
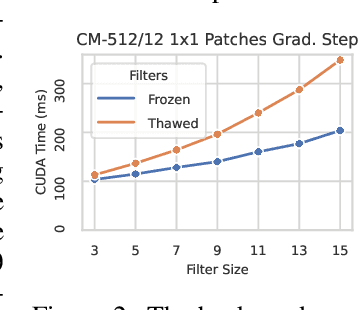

Neural network weights are typically initialized at random from univariate distributions, controlling just the variance of individual weights even in highly-structured operations like convolutions. Recent ViT-inspired convolutional networks such as ConvMixer and ConvNeXt use large-kernel depthwise convolutions whose learned filters have notable structure; this presents an opportunity to study their empirical covariances. In this work, we first observe that such learned filters have highly-structured covariance matrices, and moreover, we find that covariances calculated from small networks may be used to effectively initialize a variety of larger networks of different depths, widths, patch sizes, and kernel sizes, indicating a degree of model-independence to the covariance structure. Motivated by these findings, we then propose a learning-free multivariate initialization scheme for convolutional filters using a simple, closed-form construction of their covariance. Models using our initialization outperform those using traditional univariate initializations, and typically meet or exceed the performance of those initialized from the covariances of learned filters; in some cases, this improvement can be achieved without training the depthwise convolutional filters at all.
You Only Query Once: Effective Black Box Adversarial Attacks with Minimal Repeated Queries
Jan 29, 2021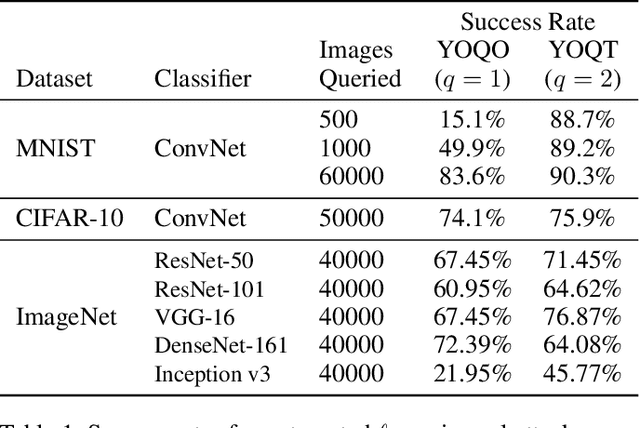



Researchers have repeatedly shown that it is possible to craft adversarial attacks on deep classifiers (small perturbations that significantly change the class label), even in the "black-box" setting where one only has query access to the classifier. However, all prior work in the black-box setting attacks the classifier by repeatedly querying the same image with minor modifications, usually thousands of times or more, making it easy for defenders to detect an ensuing attack. In this work, we instead show that it is possible to craft (universal) adversarial perturbations in the black-box setting by querying a sequence of different images only once. This attack prevents detection from high number of similar queries and produces a perturbation that causes misclassification when applied to any input to the classifier. In experiments, we show that attacks that adhere to this restriction can produce untargeted adversarial perturbations that fool the vast majority of MNIST and CIFAR-10 classifier inputs, as well as in excess of $60-70\%$ of inputs on ImageNet classifiers. In the targeted setting, we exhibit targeted black-box universal attacks on ImageNet classifiers with success rates above $20\%$ when only allowed one query per image, and $66\%$ when allowed two queries per image.
A community-powered search of machine learning strategy space to find NMR property prediction models
Aug 13, 2020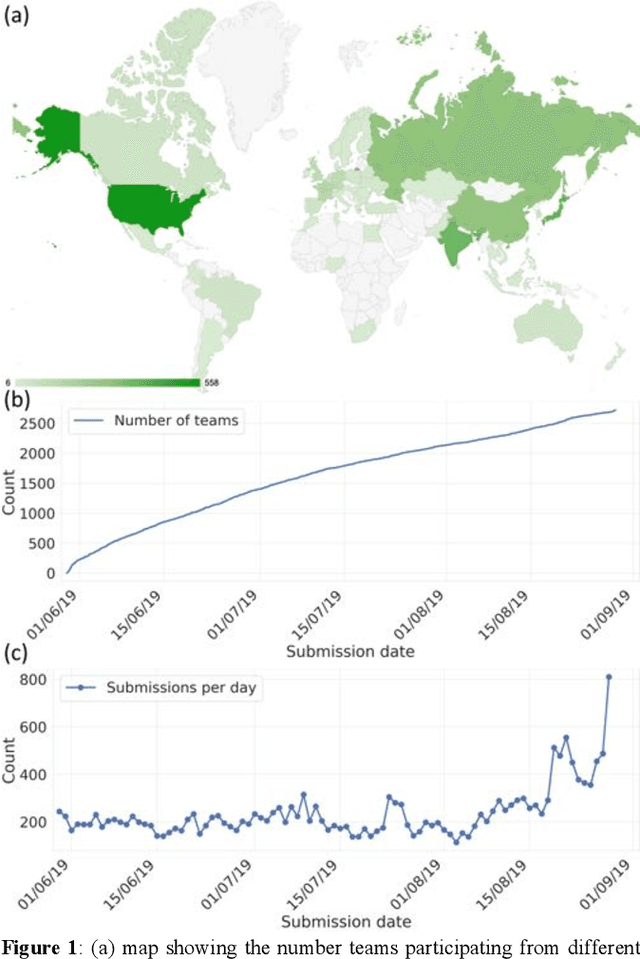
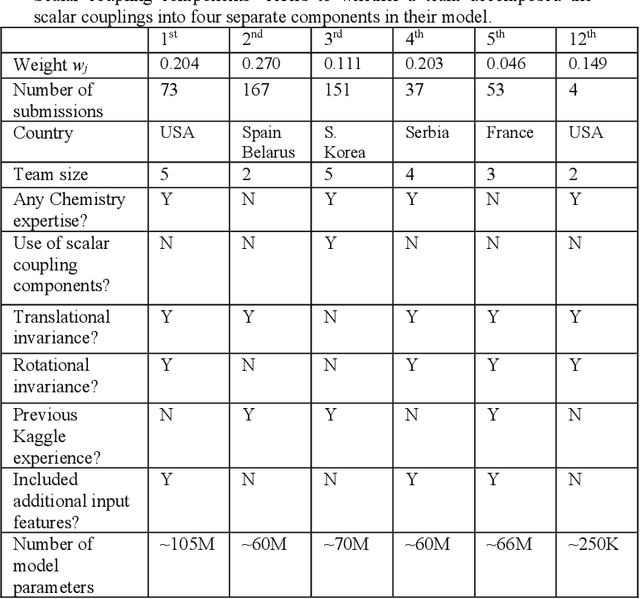
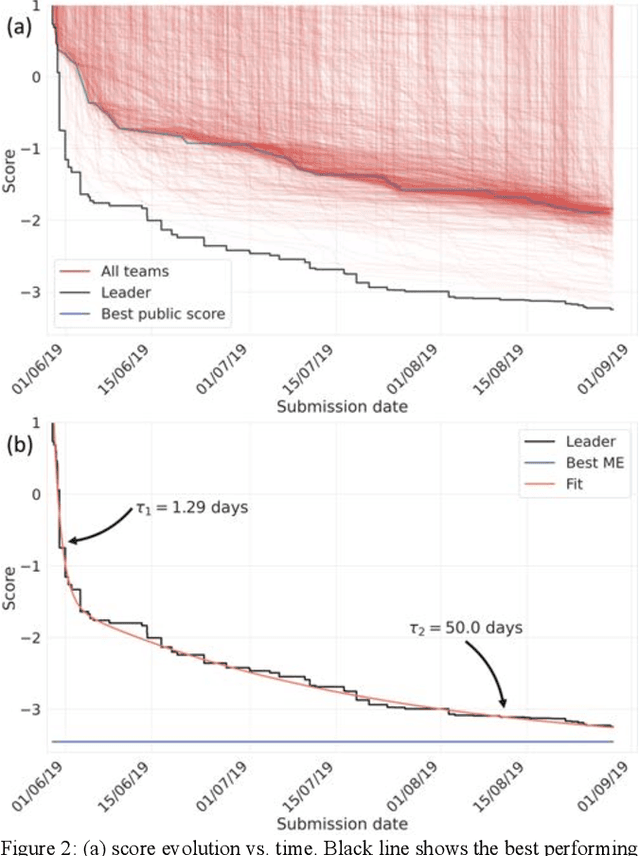
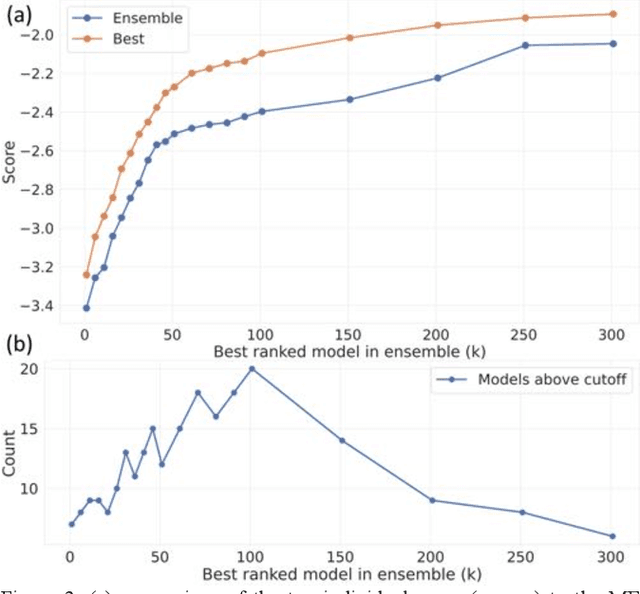
The rise of machine learning (ML) has created an explosion in the potential strategies for using data to make scientific predictions. For physical scientists wishing to apply ML strategies to a particular domain, it can be difficult to assess in advance what strategy to adopt within a vast space of possibilities. Here we outline the results of an online community-powered effort to swarm search the space of ML strategies and develop algorithms for predicting atomic-pairwise nuclear magnetic resonance (NMR) properties in molecules. Using an open-source dataset, we worked with Kaggle to design and host a 3-month competition which received 47,800 ML model predictions from 2,700 teams in 84 countries. Within 3 weeks, the Kaggle community produced models with comparable accuracy to our best previously published "in-house" efforts. A meta-ensemble model constructed as a linear combination of the top predictions has a prediction accuracy which exceeds that of any individual model, 7-19x better than our previous state-of-the-art. The results highlight the potential of transformer architectures for predicting quantum mechanical (QM) molecular properties.
Hard Label Black-box Adversarial Attacks in Low Query Budget Regimes
Jul 13, 2020
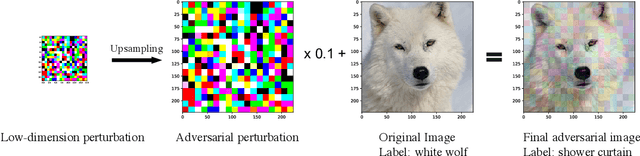

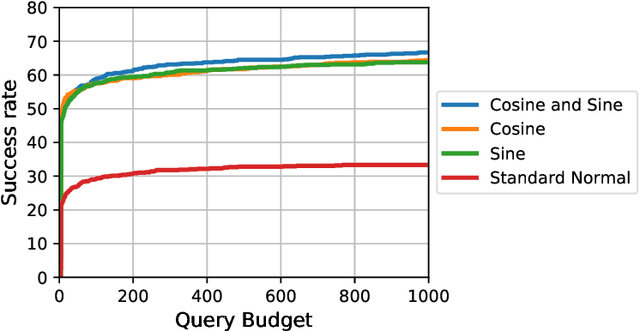
We focus on the problem of black-box adversarial attacks, where the aim is to generate adversarial examples for deep learning models solely based on information limited to output labels (hard label) to a queried data input. We use Bayesian optimization (BO) to specifically cater to scenarios involving low query budgets to develop efficient adversarial attacks. Issues with BO's performance in high dimensions are avoided by searching for adversarial examples in structured low-dimensional subspace. Our proposed approach achieves better performance to state of the art black-box adversarial attacks that require orders of magnitude more queries than ours.
Black-box Adversarial Attacks with Bayesian Optimization
Sep 30, 2019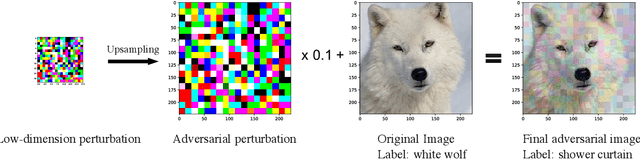
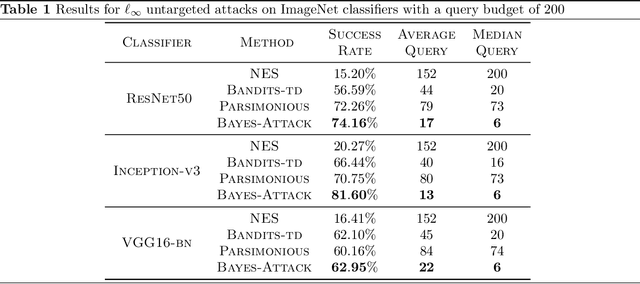
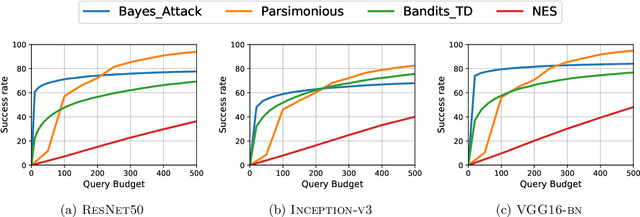
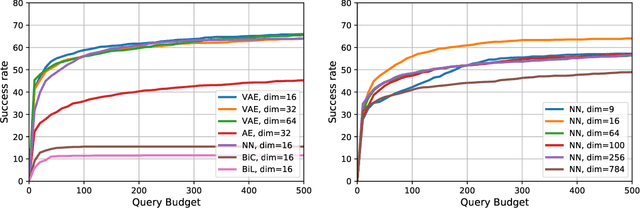
We focus on the problem of black-box adversarial attacks, where the aim is to generate adversarial examples using information limited to loss function evaluations of input-output pairs. We use Bayesian optimization~(BO) to specifically cater to scenarios involving low query budgets to develop query efficient adversarial attacks. We alleviate the issues surrounding BO in regards to optimizing high dimensional deep learning models by effective dimension upsampling techniques. Our proposed approach achieves performance comparable to the state of the art black-box adversarial attacks albeit with a much lower average query count. In particular, in low query budget regimes, our proposed method reduces the query count up to $80\%$ with respect to the state of the art methods.
Orthogonal Recurrent Neural Networks with Scaled Cayley Transform
Jun 19, 2018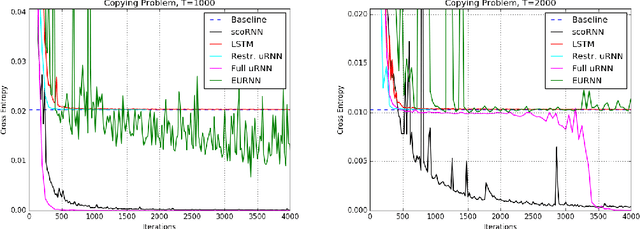
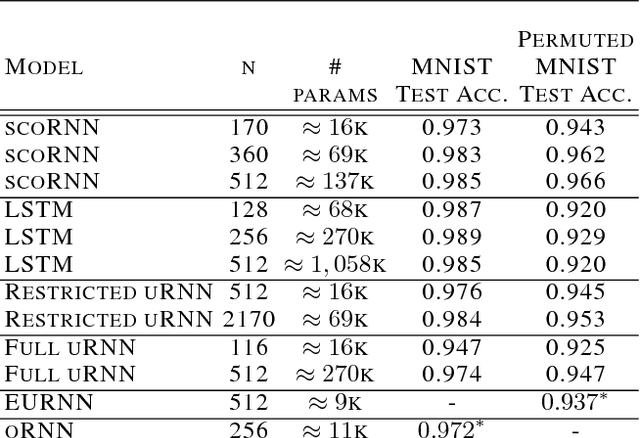
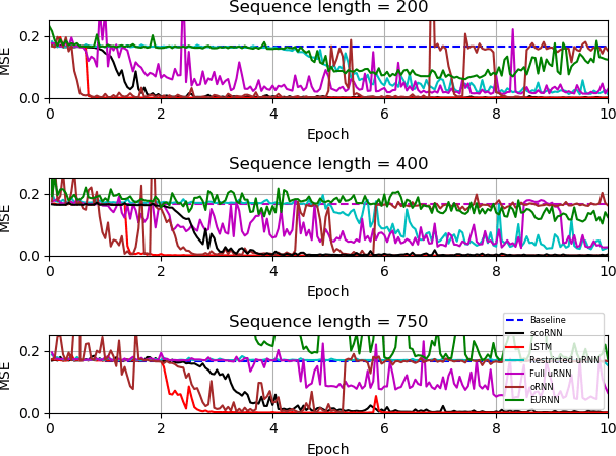
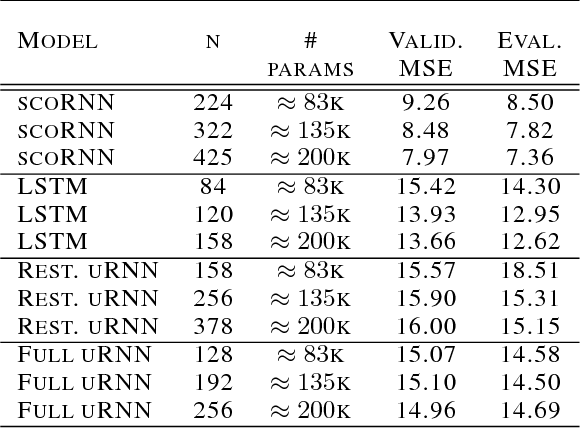
Recurrent Neural Networks (RNNs) are designed to handle sequential data but suffer from vanishing or exploding gradients. Recent work on Unitary Recurrent Neural Networks (uRNNs) have been used to address this issue and in some cases, exceed the capabilities of Long Short-Term Memory networks (LSTMs). We propose a simpler and novel update scheme to maintain orthogonal recurrent weight matrices without using complex valued matrices. This is done by parametrizing with a skew-symmetric matrix using the Cayley transform. Such a parametrization is unable to represent matrices with negative one eigenvalues, but this limitation is overcome by scaling the recurrent weight matrix by a diagonal matrix consisting of ones and negative ones. The proposed training scheme involves a straightforward gradient calculation and update step. In several experiments, the proposed scaled Cayley orthogonal recurrent neural network (scoRNN) achieves superior results with fewer trainable parameters than other unitary RNNs.