 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatch Normalization Preconditioning for Neural Network Training
Aug 02, 2021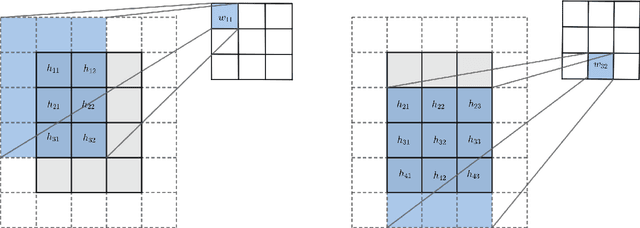
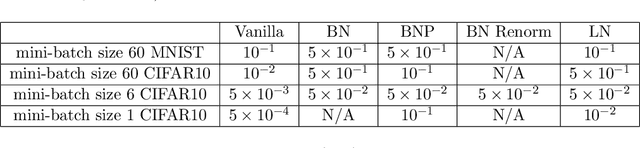

Batch normalization (BN) is a popular and ubiquitous method in deep learning that has been shown to decrease training time and improve generalization performance of neural networks. Despite its success, BN is not theoretically well understood. It is not suitable for use with very small mini-batch sizes or online learning. In this paper, we propose a new method called Batch Normalization Preconditioning (BNP). Instead of applying normalization explicitly through a batch normalization layer as is done in BN, BNP applies normalization by conditioning the parameter gradients directly during training. This is designed to improve the Hessian matrix of the loss function and hence convergence during training. One benefit is that BNP is not constrained on the mini-batch size and works in the online learning setting. Furthermore, its connection to BN provides theoretical insights on how BN improves training and how BN is applied to special architectures such as convolutional neural networks.
Eigenvalue Normalized Recurrent Neural Networks for Short Term Memory
Nov 18, 2019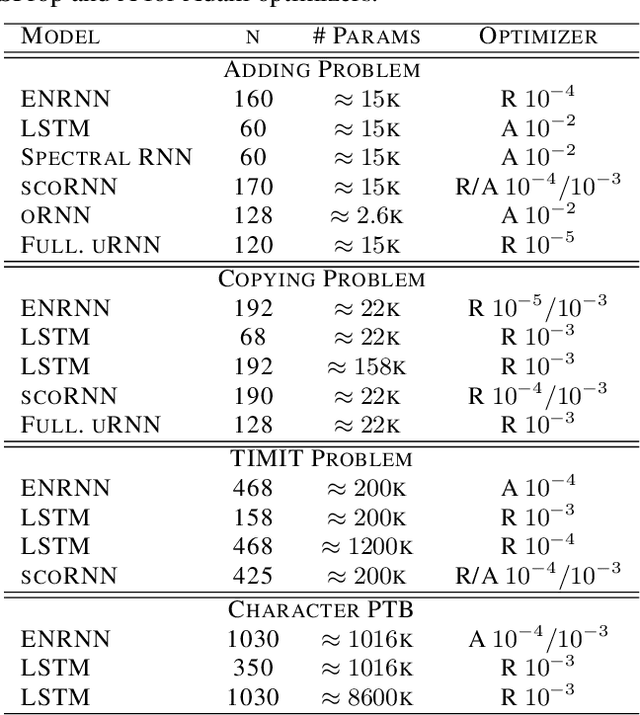
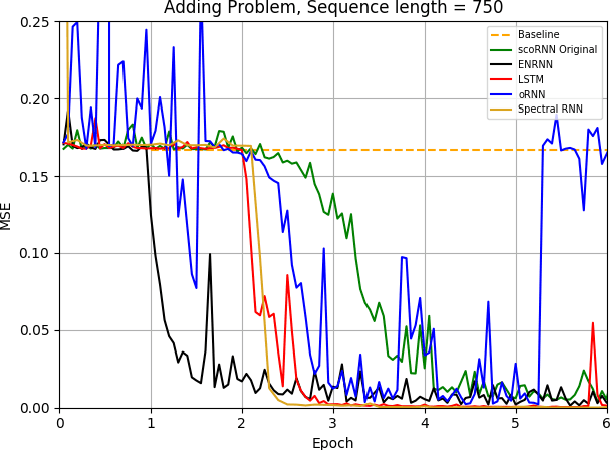
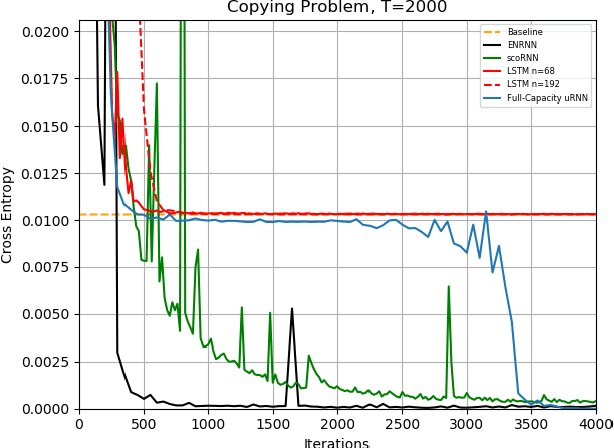
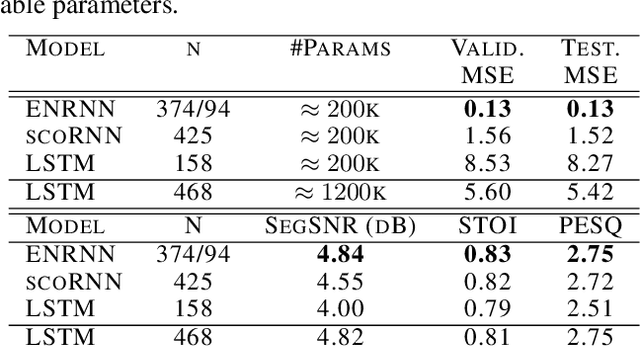
Several variants of recurrent neural networks (RNNs) with orthogonal or unitary recurrent matrices have recently been developed to mitigate the vanishing/exploding gradient problem and to model long-term dependencies of sequences. However, with the eigenvalues of the recurrent matrix on the unit circle, the recurrent state retains all input information which may unnecessarily consume model capacity. In this paper, we address this issue by proposing an architecture that expands upon an orthogonal/unitary RNN with a state that is generated by a recurrent matrix with eigenvalues in the unit disc. Any input to this state dissipates in time and is replaced with new inputs, simulating short-term memory. A gradient descent algorithm is derived for learning such a recurrent matrix. The resulting method, called the Eigenvalue Normalized RNN (ENRNN), is shown to be highly competitive in several experiments.
Orthogonal Recurrent Neural Networks with Scaled Cayley Transform
Jun 19, 2018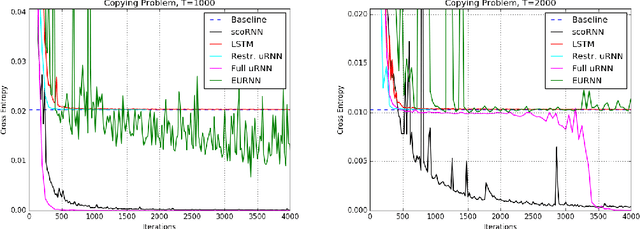
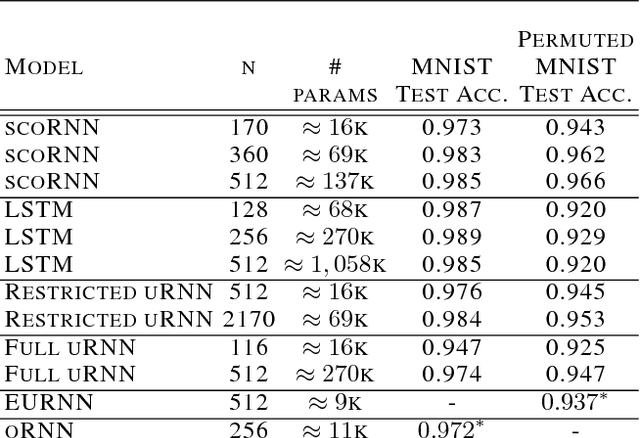
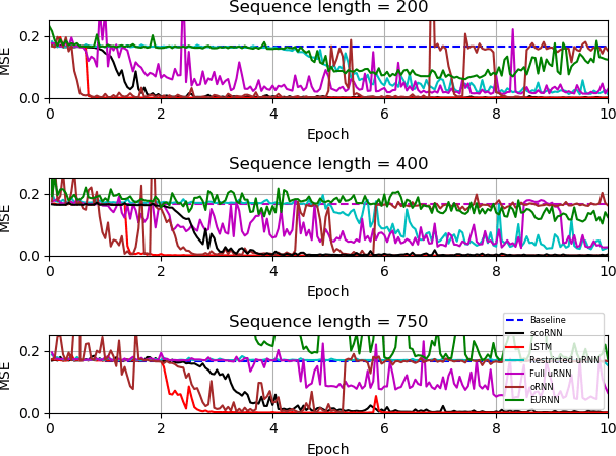
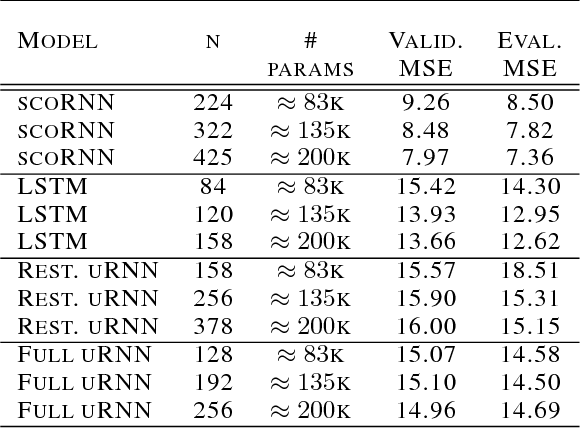
Recurrent Neural Networks (RNNs) are designed to handle sequential data but suffer from vanishing or exploding gradients. Recent work on Unitary Recurrent Neural Networks (uRNNs) have been used to address this issue and in some cases, exceed the capabilities of Long Short-Term Memory networks (LSTMs). We propose a simpler and novel update scheme to maintain orthogonal recurrent weight matrices without using complex valued matrices. This is done by parametrizing with a skew-symmetric matrix using the Cayley transform. Such a parametrization is unable to represent matrices with negative one eigenvalues, but this limitation is overcome by scaling the recurrent weight matrix by a diagonal matrix consisting of ones and negative ones. The proposed training scheme involves a straightforward gradient calculation and update step. In several experiments, the proposed scaled Cayley orthogonal recurrent neural network (scoRNN) achieves superior results with fewer trainable parameters than other unitary RNNs.