 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEigenvalue Normalized Recurrent Neural Networks for Short Term Memory
Paper and Code
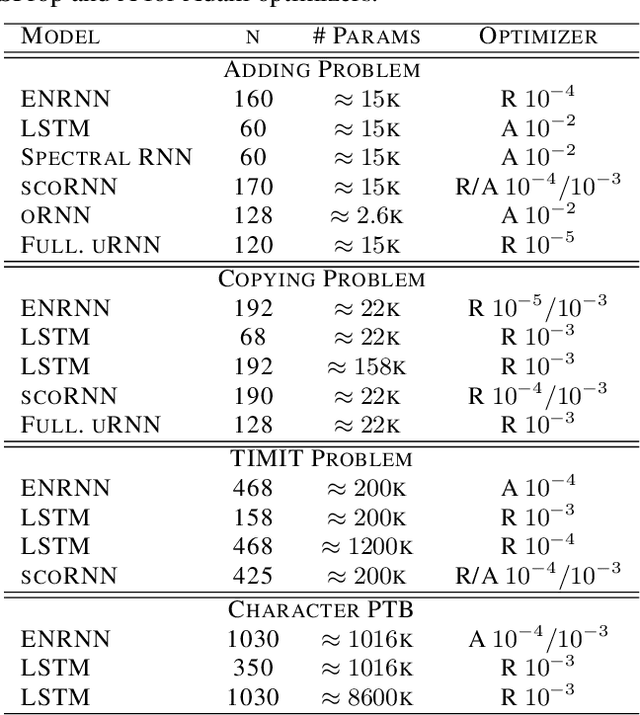
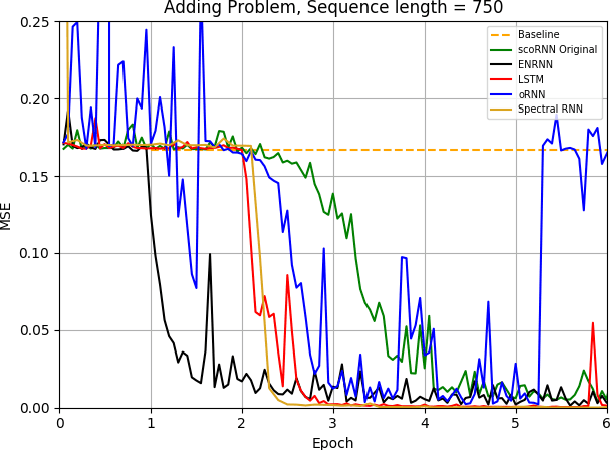
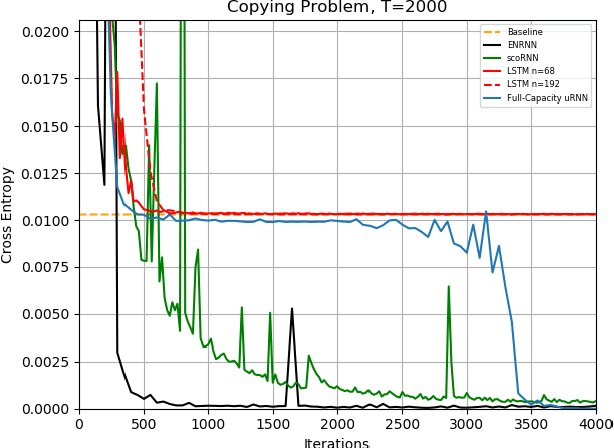
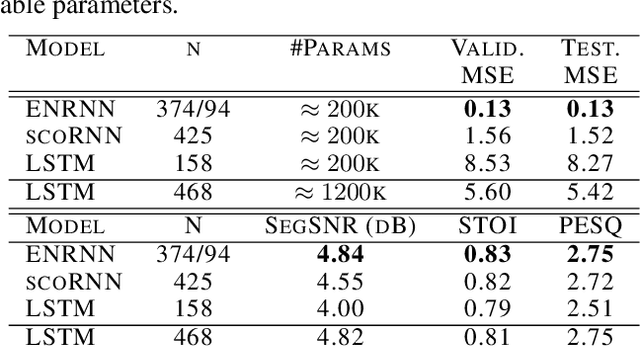
Several variants of recurrent neural networks (RNNs) with orthogonal or unitary recurrent matrices have recently been developed to mitigate the vanishing/exploding gradient problem and to model long-term dependencies of sequences. However, with the eigenvalues of the recurrent matrix on the unit circle, the recurrent state retains all input information which may unnecessarily consume model capacity. In this paper, we address this issue by proposing an architecture that expands upon an orthogonal/unitary RNN with a state that is generated by a recurrent matrix with eigenvalues in the unit disc. Any input to this state dissipates in time and is replaced with new inputs, simulating short-term memory. A gradient descent algorithm is derived for learning such a recurrent matrix. The resulting method, called the Eigenvalue Normalized RNN (ENRNN), is shown to be highly competitive in several experiments.