 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatch Normalization Preconditioning for Neural Network Training
Aug 02, 2021
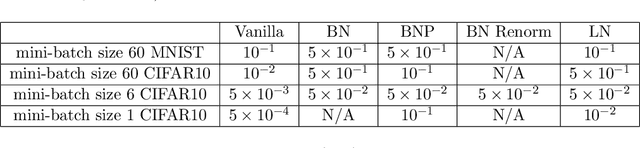

Batch normalization (BN) is a popular and ubiquitous method in deep learning that has been shown to decrease training time and improve generalization performance of neural networks. Despite its success, BN is not theoretically well understood. It is not suitable for use with very small mini-batch sizes or online learning. In this paper, we propose a new method called Batch Normalization Preconditioning (BNP). Instead of applying normalization explicitly through a batch normalization layer as is done in BN, BNP applies normalization by conditioning the parameter gradients directly during training. This is designed to improve the Hessian matrix of the loss function and hence convergence during training. One benefit is that BNP is not constrained on the mini-batch size and works in the online learning setting. Furthermore, its connection to BN provides theoretical insights on how BN improves training and how BN is applied to special architectures such as convolutional neural networks.