 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-series Forecast for Indoor Zone Air Temperature with Long Horizons: A Case Study with Sensor-based Data from a Smart Building
Dec 22, 2025With the press of global climate change, extreme weather and sudden weather changes are becoming increasingly common. To maintain a comfortable indoor environment and minimize the contribution of the building to climate change as much as possible, higher requirements are placed on the operation and control of HVAC systems, e.g., more energy-efficient and flexible to response to the rapid change of weather. This places demands on the rapid modeling and prediction of zone air temperatures of buildings. Compared to the traditional simulation-based approach such as EnergyPlus and DOE2, a hybrid approach combined physics and data-driven is more suitable. Recently, the availability of high-quality datasets and algorithmic breakthroughs have driven a considerable amount of work in this field. However, in the niche of short- and long-term predictions, there are still some gaps in existing research. This paper aims to develop a time series forecast model to predict the zone air temperature in a building located in America on a 2-week horizon. The findings could be further improved to support intelligent control and operation of HVAC systems (i.e. demand flexibility) and could also be used as hybrid building energy modeling.
Catch Me If You Can? Not Yet: LLMs Still Struggle to Imitate the Implicit Writing Styles of Everyday Authors
Sep 18, 2025

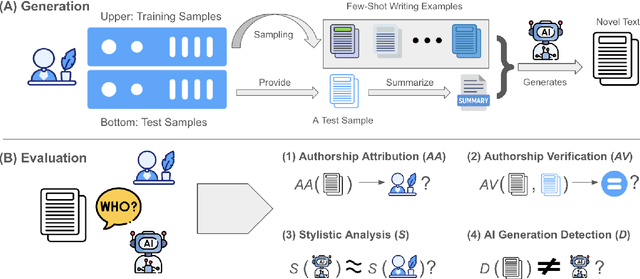
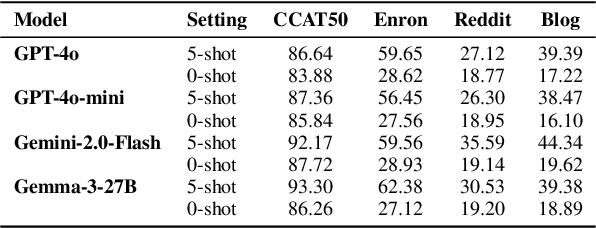
As large language models (LLMs) become increasingly integrated into personal writing tools, a critical question arises: can LLMs faithfully imitate an individual's writing style from just a few examples? Personal style is often subtle and implicit, making it difficult to specify through prompts yet essential for user-aligned generation. This work presents a comprehensive evaluation of state-of-the-art LLMs' ability to mimic personal writing styles via in-context learning from a small number of user-authored samples. We introduce an ensemble of complementary metrics-including authorship attribution, authorship verification, style matching, and AI detection-to robustly assess style imitation. Our evaluation spans over 40000 generations per model across domains such as news, email, forums, and blogs, covering writing samples from more than 400 real-world authors. Results show that while LLMs can approximate user styles in structured formats like news and email, they struggle with nuanced, informal writing in blogs and forums. Further analysis on various prompting strategies such as number of demonstrations reveal key limitations in effective personalization. Our findings highlight a fundamental gap in personalized LLM adaptation and the need for improved techniques to support implicit, style-consistent generation. To aid future research and for reproducibility, we open-source our data and code.
Auto-Train-Once: Controller Network Guided Automatic Network Pruning from Scratch
Mar 21, 2024



Current techniques for deep neural network (DNN) pruning often involve intricate multi-step processes that require domain-specific expertise, making their widespread adoption challenging. To address the limitation, the Only-Train-Once (OTO) and OTOv2 are proposed to eliminate the need for additional fine-tuning steps by directly training and compressing a general DNN from scratch. Nevertheless, the static design of optimizers (in OTO) can lead to convergence issues of local optima. In this paper, we proposed the Auto-Train-Once (ATO), an innovative network pruning algorithm designed to automatically reduce the computational and storage costs of DNNs. During the model training phase, our approach not only trains the target model but also leverages a controller network as an architecture generator to guide the learning of target model weights. Furthermore, we developed a novel stochastic gradient algorithm that enhances the coordination between model training and controller network training, thereby improving pruning performance. We provide a comprehensive convergence analysis as well as extensive experiments, and the results show that our approach achieves state-of-the-art performance across various model architectures (including ResNet18, ResNet34, ResNet50, ResNet56, and MobileNetv2) on standard benchmark datasets (CIFAR-10, CIFAR-100, and ImageNet).
Leveraging Foundation Models to Improve Lightweight Clients in Federated Learning
Nov 14, 2023Federated Learning (FL) is a distributed training paradigm that enables clients scattered across the world to cooperatively learn a global model without divulging confidential data. However, FL faces a significant challenge in the form of heterogeneous data distributions among clients, which leads to a reduction in performance and robustness. A recent approach to mitigating the impact of heterogeneous data distributions is through the use of foundation models, which offer better performance at the cost of larger computational overheads and slower inference speeds. We introduce foundation model distillation to assist in the federated training of lightweight client models and increase their performance under heterogeneous data settings while keeping inference costs low. Our results show improvement in the global model performance on a balanced testing set, which contains rarely observed samples, even under extreme non-IID client data distributions. We conduct a thorough evaluation of our framework with different foundation model backbones on CIFAR10, with varying degrees of heterogeneous data distributions ranging from class-specific data partitions across clients to dirichlet data sampling, parameterized by values between 0.01 and 1.0.
Text-driven Prompt Generation for Vision-Language Models in Federated Learning
Oct 09, 2023



Prompt learning for vision-language models, e.g., CoOp, has shown great success in adapting CLIP to different downstream tasks, making it a promising solution for federated learning due to computational reasons. Existing prompt learning techniques replace hand-crafted text prompts with learned vectors that offer improvements on seen classes, but struggle to generalize to unseen classes. Our work addresses this challenge by proposing Federated Text-driven Prompt Generation (FedTPG), which learns a unified prompt generation network across multiple remote clients in a scalable manner. The prompt generation network is conditioned on task-related text input, thus is context-aware, making it suitable to generalize for both seen and unseen classes. Our comprehensive empirical evaluations on nine diverse image classification datasets show that our method is superior to existing federated prompt learning methods, that achieve overall better generalization on both seen and unseen classes and is also generalizable to unseen datasets.
Cross-corpus Readability Compatibility Assessment for English Texts
Jun 16, 2023
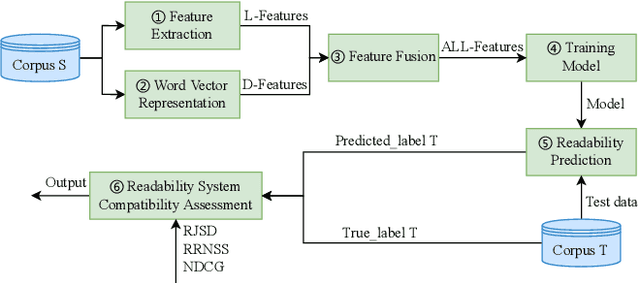

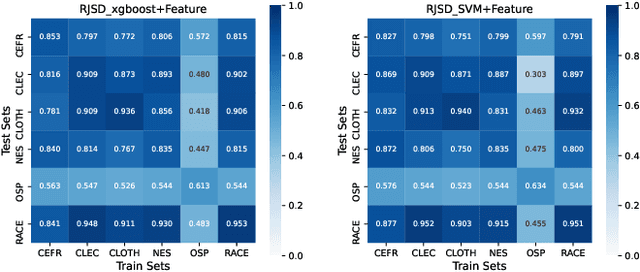
Text readability assessment has gained significant attention from researchers in various domains. However, the lack of exploration into corpus compatibility poses a challenge as different research groups utilize different corpora. In this study, we propose a novel evaluation framework, Cross-corpus text Readability Compatibility Assessment (CRCA), to address this issue. The framework encompasses three key components: (1) Corpus: CEFR, CLEC, CLOTH, NES, OSP, and RACE. Linguistic features, GloVe word vector representations, and their fusion features were extracted. (2) Classification models: Machine learning methods (XGBoost, SVM) and deep learning methods (BiLSTM, Attention-BiLSTM) were employed. (3) Compatibility metrics: RJSD, RRNSS, and NDCG metrics. Our findings revealed: (1) Validated corpus compatibility, with OSP standing out as significantly different from other datasets. (2) An adaptation effect among corpora, feature representations, and classification methods. (3) Consistent outcomes across the three metrics, validating the robustness of the compatibility assessment framework. The outcomes of this study offer valuable insights into corpus selection, feature representation, and classification methods, and it can also serve as a beginning effort for cross-corpus transfer learning.
TTAGN: Temporal Transaction Aggregation Graph Network for Ethereum Phishing Scams Detection
Apr 28, 2022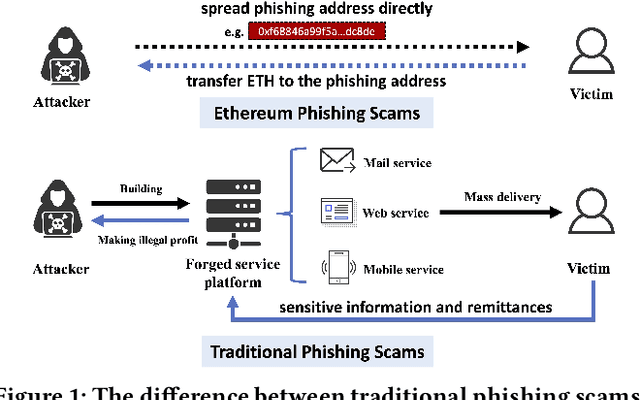
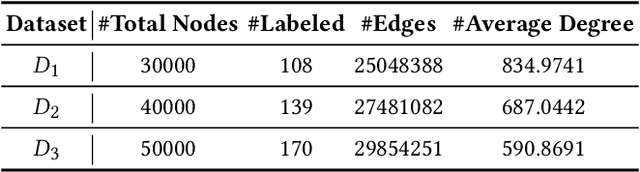
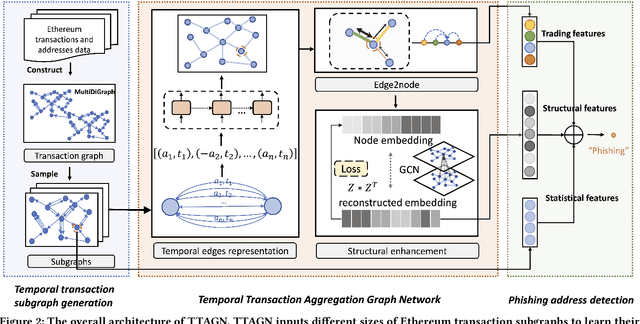
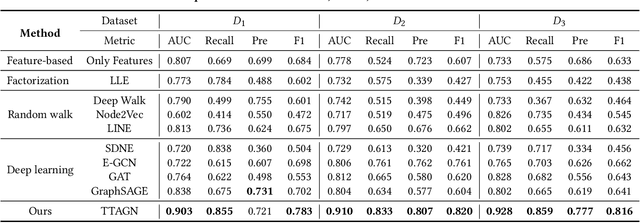
In recent years, phishing scams have become the most serious type of crime involved in Ethereum, the second-largest blockchain platform. The existing phishing scams detection technology on Ethereum mostly uses traditional machine learning or network representation learning to mine the key information from the transaction network to identify phishing addresses. However, these methods adopt the last transaction record or even completely ignore these records, and only manual-designed features are taken for the node representation. In this paper, we propose a Temporal Transaction Aggregation Graph Network (TTAGN) to enhance phishing scams detection performance on Ethereum. Specifically, in the temporal edges representation module, we model the temporal relationship of historical transaction records between nodes to construct the edge representation of the Ethereum transaction network. Moreover, the edge representations around the node are aggregated to fuse topological interactive relationships into its representation, also named as trading features, in the edge2node module. We further combine trading features with common statistical and structural features obtained by graph neural networks to identify phishing addresses. Evaluated on real-world Ethereum phishing scams datasets, our TTAGN (92.8% AUC, and 81.6% F1score) outperforms the state-of-the-art methods, and the effectiveness of temporal edges representation and edge2node module is also demonstrated.
Asymptotic Escape of Spurious Critical Points on the Low-rank Matrix Manifold
Jul 20, 2021
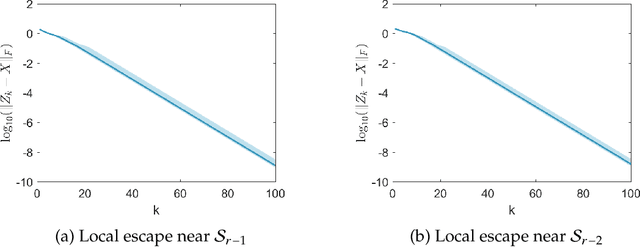
We show that the Riemannian gradient descent algorithm on the low-rank matrix manifold almost surely escapes some spurious critical points on the boundary of the manifold. Given that the low-rank matrix manifold is an incomplete set, this result is the first to overcome this difficulty and partially justify the global use of the Riemannian gradient descent on the manifold. The spurious critical points are some rank-deficient matrices that capture only part of the SVD components of the ground truth. They exhibit very singular behavior and evade the classical analysis of strict saddle points. We show that using the dynamical low-rank approximation and a rescaled gradient flow, some of the spurious critical points can be converted to classical strict saddle points, which leads to the desired result. Numerical experiments are provided to support our theoretical findings.
Fast Global Convergence for Low-rank Matrix Recovery via Riemannian Gradient Descent with Random Initialization
Dec 31, 2020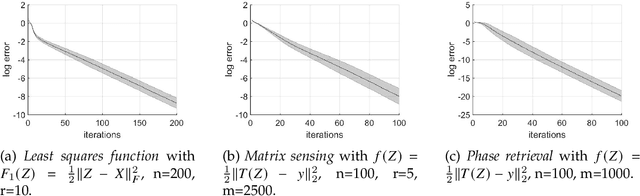
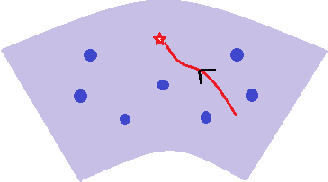
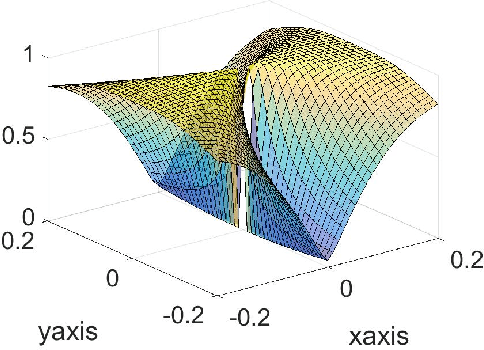
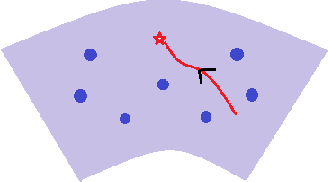
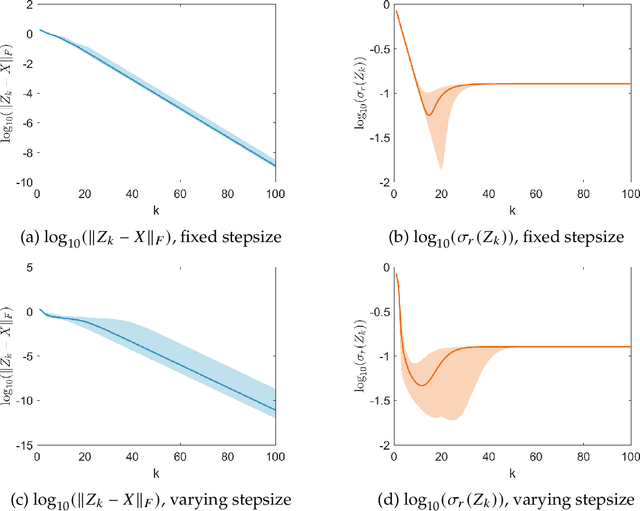
In this paper, we propose a new global analysis framework for a class of low-rank matrix recovery problems on the Riemannian manifold. We analyze the global behavior for the Riemannian optimization with random initialization. We use the Riemannian gradient descent algorithm to minimize a least squares loss function, and study the asymptotic behavior as well as the exact convergence rate. We reveal a previously unknown geometric property of the low-rank matrix manifold, which is the existence of spurious critical points for the simple least squares function on the manifold. We show that under some assumptions, the Riemannian gradient descent starting from a random initialization with high probability avoids these spurious critical points and only converges to the ground truth in nearly linear convergence rate, i.e. $\mathcal{O}(\text{log}(\frac{1}{\epsilon})+ \text{log}(n))$ iterations to reach an $\epsilon$-accurate solution. We use two applications as examples for our global analysis. The first one is a rank-1 matrix recovery problem. The second one is the Gaussian phase retrieval problem. The second example only satisfies the weak isometry property, but has behavior similar to that of the first one except for an extra saddle set. Our convergence guarantee is nearly optimal and almost dimension-free, which fully explains the numerical observations. The global analysis can be potentially extended to other data problems with random measurement structures and empirical least squares loss functions.
Meta-Learning for Neural Relation Classification with Distant Supervision
Oct 26, 2020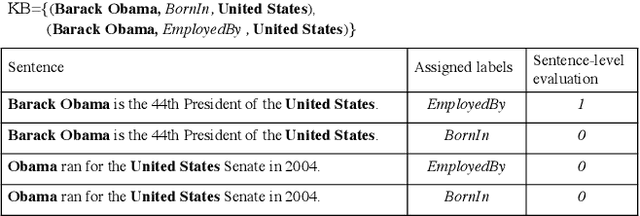
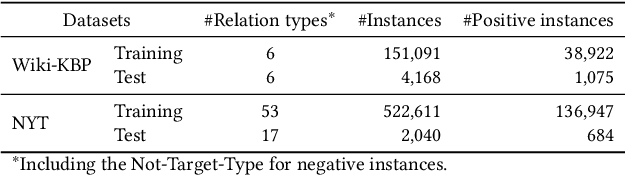
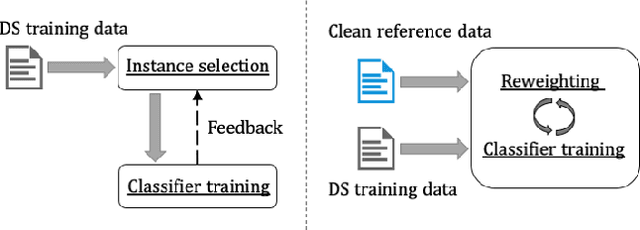
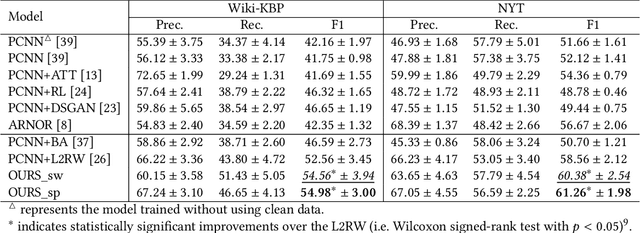
Distant supervision provides a means to create a large number of weakly labeled data at low cost for relation classification. However, the resulting labeled instances are very noisy, containing data with wrong labels. Many approaches have been proposed to select a subset of reliable instances for neural model training, but they still suffer from noisy labeling problem or underutilization of the weakly-labeled data. To better select more reliable training instances, we introduce a small amount of manually labeled data as reference to guide the selection process. In this paper, we propose a meta-learning based approach, which learns to reweight noisy training data under the guidance of reference data. As the clean reference data is usually very small, we propose to augment it by dynamically distilling the most reliable elite instances from the noisy data. Experiments on several datasets demonstrate that the reference data can effectively guide the selection of training data, and our augmented approach consistently improves the performance of relation classification comparing to the existing state-of-the-art methods.
* 10 pages, 7 figures; corrected one encoding error in CIKM pdf