 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLVLMs and Humans Ground Differently in Referential Communication
Jan 28, 2026For generative AI agents to partner effectively with human users, the ability to accurately predict human intent is critical. But this ability to collaborate remains limited by a critical deficit: an inability to model common ground. Here, we present a referential communication experiment with a factorial design involving director-matcher pairs (human-human, human-AI, AI-human, and AI-AI) that interact with multiple turns in repeated rounds to match pictures of objects not associated with any obvious lexicalized labels. We release the online pipeline for data collection, the tools and analyses for accuracy, efficiency, and lexical overlap, and a corpus of 356 dialogues (89 pairs over 4 rounds each) that unmasks LVLMs' limitations in interactively resolving referring expressions, a crucial skill that underlies human language use.
Measuring Iterative Temporal Reasoning with Time Puzzles
Jan 13, 2026We introduce Time Puzzles, a constraint-based date inference task for evaluating iterative temporal reasoning. Each puzzle combines factual temporal anchors with (cross-cultural) calendar relations, admits one or multiple valid solution dates, and is algorithmically generated for controlled, dynamic, and continual evaluation. Across 13 diverse LLMs, Time Puzzles well distinguishes their iterative temporal reasoning capabilities and remains challenging without tools: GPT-5 reaches only 49.3% accuracy and all other models stay below 31%, despite the dataset's simplicity. Web search consistently yields substantial gains and using code interpreter shows mixed effects, but all models perform much better when constraints are rewritten with explicit dates, revealing a gap in reliable tool use. Overall, Time Puzzles presents a simple, cost-effective diagnostic for tool-augmented iterative temporal reasoning.
Catch Me If You Can? Not Yet: LLMs Still Struggle to Imitate the Implicit Writing Styles of Everyday Authors
Sep 18, 2025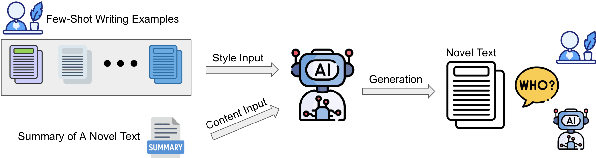

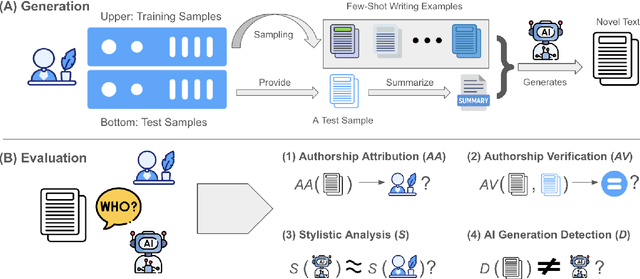
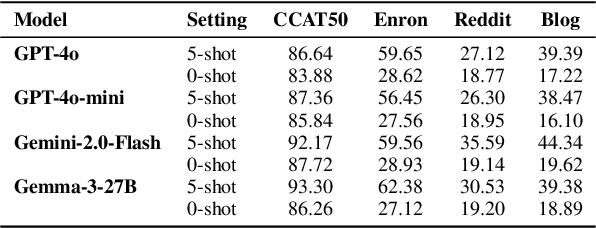
As large language models (LLMs) become increasingly integrated into personal writing tools, a critical question arises: can LLMs faithfully imitate an individual's writing style from just a few examples? Personal style is often subtle and implicit, making it difficult to specify through prompts yet essential for user-aligned generation. This work presents a comprehensive evaluation of state-of-the-art LLMs' ability to mimic personal writing styles via in-context learning from a small number of user-authored samples. We introduce an ensemble of complementary metrics-including authorship attribution, authorship verification, style matching, and AI detection-to robustly assess style imitation. Our evaluation spans over 40000 generations per model across domains such as news, email, forums, and blogs, covering writing samples from more than 400 real-world authors. Results show that while LLMs can approximate user styles in structured formats like news and email, they struggle with nuanced, informal writing in blogs and forums. Further analysis on various prompting strategies such as number of demonstrations reveal key limitations in effective personalization. Our findings highlight a fundamental gap in personalized LLM adaptation and the need for improved techniques to support implicit, style-consistent generation. To aid future research and for reproducibility, we open-source our data and code.
LLMs can Perform Multi-Dimensional Analytic Writing Assessments: A Case Study of L2 Graduate-Level Academic English Writing
Feb 17, 2025The paper explores the performance of LLMs in the context of multi-dimensional analytic writing assessments, i.e. their ability to provide both scores and comments based on multiple assessment criteria. Using a corpus of literature reviews written by L2 graduate students and assessed by human experts against 9 analytic criteria, we prompt several popular LLMs to perform the same task under various conditions. To evaluate the quality of feedback comments, we apply a novel feedback comment quality evaluation framework. This framework is interpretable, cost-efficient, scalable, and reproducible, compared to existing methods that rely on manual judgments. We find that LLMs can generate reasonably good and generally reliable multi-dimensional analytic assessments. We release our corpus for reproducibility.
Evaluating LLMs with Multiple Problems at once: A New Paradigm for Probing LLM Capabilities
Jun 16, 2024Current LLM evaluation predominantly performs evaluation with prompts comprising single problems. We propose multi-problem evaluation as an additional approach to study the multiple problem handling capabilities of LLMs. We present a systematic study in this regard by comprehensively examining 7 LLMs on 4 related types of tasks constructed from 6 classification benchmarks. The 4 task types include traditional single-problem tasks, homogeneous multi-problem tasks, and two index selection tasks that embed the multi-problem tasks. We find that LLMs are competent multi-problem solvers: they generally perform (nearly) as well on multi-problem tasks as on single-problem tasks. Furthermore, contrary to common expectation, they often do not suffer from a positional bias with long inputs. This makes multi-problem prompting a simple and cost-efficient prompting method of practical significance. However, our results also strongly indicate that LLMs lack true understanding: they perform significantly worse in the two index selection tasks than in the multi-problem task under various evaluation settings, although they can indeed do index selection in general.
Clustering Document Parts: Detecting and Characterizing Influence Campaigns From Documents
Feb 27, 2024



We propose a novel clustering pipeline to detect and characterize influence campaigns from documents. This approach clusters parts of document, detects clusters that likely reflect an influence campaign, and then identifies documents linked to an influence campaign via their association with the high-influence clusters. Our approach outperforms both the direct document-level classification and the direct document-level clustering approach in predicting if a document is part of an influence campaign. We propose various novel techniques to enhance our pipeline, including using an existing event factuality prediction system to obtain document parts, and aggregating multiple clustering experiments to improve the performance of both cluster and document classification. Classifying documents on the top of clustering not only accurately extracts the parts of the documents that are relevant to influence campaigns, but also capture influence campaigns as a coordinated and holistic phenomenon. Our approach makes possible more fine-grained and interpretable characterizations of influence campaigns from documents.
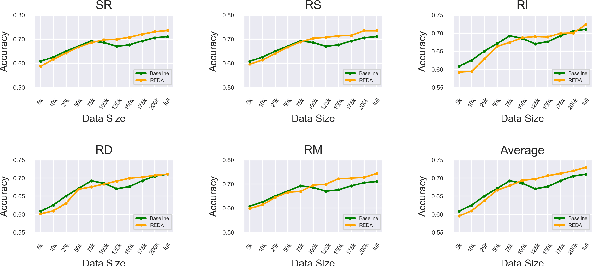
Probabilistic Linguistic Knowledge and Token-level Text Augmentation
Jul 03, 2023This paper investigates the effectiveness of token-level text augmentation and the role of probabilistic linguistic knowledge within a linguistically-motivated evaluation context. Two text augmentation programs, REDA and REDA$_{NG}$, were developed, both implementing five token-level text editing operations: Synonym Replacement (SR), Random Swap (RS), Random Insertion (RI), Random Deletion (RD), and Random Mix (RM). REDA$_{NG}$ leverages pretrained $n$-gram language models to select the most likely augmented texts from REDA's output. Comprehensive and fine-grained experiments were conducted on a binary question matching classification task in both Chinese and English. The results strongly refute the general effectiveness of the five token-level text augmentation techniques under investigation, whether applied together or separately, and irrespective of various common classification model types used, including transformers. Furthermore, the role of probabilistic linguistic knowledge is found to be minimal.
Learning Transductions and Alignments with RNN Seq2seq Models
Mar 13, 2023The paper studies the capabilities of Recurrent-Neural-Network sequence to sequence (RNN seq2seq) models in learning four string-to-string transduction tasks: identity, reversal, total reduplication, and input-specified reduplication. These transductions are traditionally well studied under finite state transducers and attributed with varying complexity. We find that RNN seq2seq models are only able to approximate a mapping that fits the training or in-distribution data. Attention helps significantly, but does not solve the out-of-distribution generalization limitation. Task complexity and RNN variants also play a role in the results. Our results are best understood in terms of the complexity hierarchy of formal languages as opposed to that of string transductions.
Random Text Perturbations Work, but not Always
Sep 02, 2022
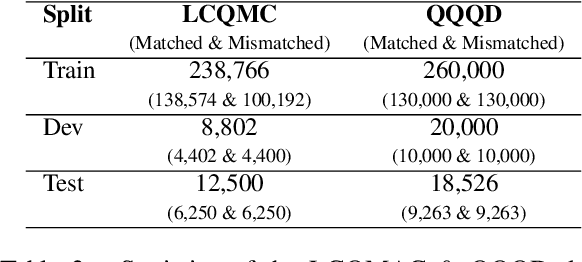
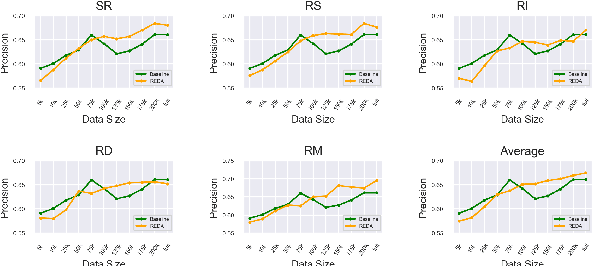
We present three large-scale experiments on binary text matching classification task both in Chinese and English to evaluate the effectiveness and generalizability of random text perturbations as a data augmentation approach for NLP. It is found that the augmentation can bring both negative and positive effects to the test set performance of three neural classification models, depending on whether the models train on enough original training examples. This remains true no matter whether five random text editing operations, used to augment text, are applied together or separately. Our study demonstrates with strong implication that the effectiveness of random text perturbations is task specific and not generally positive.
Linguistic Knowledge in Data Augmentation for Natural Language Processing: An Example on Chinese Question Matching
Dec 15, 2021


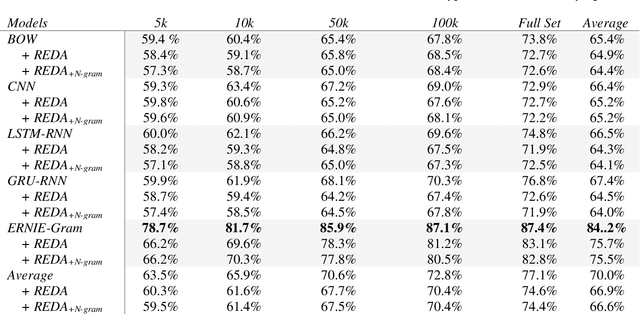
To investigate the role of linguistic knowledge in data augmentation (DA) for Natural Language Processing (NLP), particularly, whether more linguistic knowledge leads to a better DA approach, we designed two adapted DA programs and applied them to LCQMC (a Large-scale Chinese Question Matching Corpus) for a binary Chinese question matching classification task. The two DA programs produce augmented texts by five simple text editing operations (or DA techniques), largely irrespective of language generation rules, but one is enhanced with a pre-trained n-gram language model to fuse it with prior linguistic knowledge. We then trained four neural network models (BOW, CNN, LSTM-RNN, and GRU-RNN) and a pre-trained model (ERNIE-Gram) on the LCQMC train sets of varying size as well as the related augmented train sets produced by the two DA programs. The test set performances of the five classification models show that adding probabilistic linguistic knowledge as constrains does not make the base DA program better, since there are no significant performance differences between the models trained on the two types of augmented train sets, both when the five DA techniques are applied together or separately. Moreover, due to the inability of the five DA techniques to make strictly paraphrastic augmented texts, the results indicate the need of sufficient amounts of training examples for the classification models trained on them to mediate the negative impact of false matching augmented text pairs and improve performances, a limitation of random text editing perturbations used a DA approach.