 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLVLMs and Humans Ground Differently in Referential Communication
Jan 28, 2026For generative AI agents to partner effectively with human users, the ability to accurately predict human intent is critical. But this ability to collaborate remains limited by a critical deficit: an inability to model common ground. Here, we present a referential communication experiment with a factorial design involving director-matcher pairs (human-human, human-AI, AI-human, and AI-AI) that interact with multiple turns in repeated rounds to match pictures of objects not associated with any obvious lexicalized labels. We release the online pipeline for data collection, the tools and analyses for accuracy, efficiency, and lexical overlap, and a corpus of 356 dialogues (89 pairs over 4 rounds each) that unmasks LVLMs' limitations in interactively resolving referring expressions, a crucial skill that underlies human language use.
OmniVox: Zero-Shot Emotion Recognition with Omni-LLMs
Mar 27, 2025



The use of omni-LLMs (large language models that accept any modality as input), particularly for multimodal cognitive state tasks involving speech, is understudied. We present OmniVox, the first systematic evaluation of four omni-LLMs on the zero-shot emotion recognition task. We evaluate on two widely used multimodal emotion benchmarks: IEMOCAP and MELD, and find zero-shot omni-LLMs outperform or are competitive with fine-tuned audio models. Alongside our audio-only evaluation, we also evaluate omni-LLMs on text only and text and audio. We present acoustic prompting, an audio-specific prompting strategy for omni-LLMs which focuses on acoustic feature analysis, conversation context analysis, and step-by-step reasoning. We compare our acoustic prompting to minimal prompting and full chain-of-thought prompting techniques. We perform a context window analysis on IEMOCAP and MELD, and find that using context helps, especially on IEMOCAP. We conclude with an error analysis on the generated acoustic reasoning outputs from the omni-LLMs.
Active Few-Shot Learning for Text Classification
Feb 26, 2025The rise of Large Language Models (LLMs) has boosted the use of Few-Shot Learning (FSL) methods in natural language processing, achieving acceptable performance even when working with limited training data. The goal of FSL is to effectively utilize a small number of annotated samples in the learning process. However, the performance of FSL suffers when unsuitable support samples are chosen. This problem arises due to the heavy reliance on a limited number of support samples, which hampers consistent performance improvement even when more support samples are added. To address this challenge, we propose an active learning-based instance selection mechanism that identifies effective support instances from the unlabeled pool and can work with different LLMs. Our experiments on five tasks show that our method frequently improves the performance of FSL. We make our implementation available on GitHub.
LLMs can Perform Multi-Dimensional Analytic Writing Assessments: A Case Study of L2 Graduate-Level Academic English Writing
Feb 17, 2025The paper explores the performance of LLMs in the context of multi-dimensional analytic writing assessments, i.e. their ability to provide both scores and comments based on multiple assessment criteria. Using a corpus of literature reviews written by L2 graduate students and assessed by human experts against 9 analytic criteria, we prompt several popular LLMs to perform the same task under various conditions. To evaluate the quality of feedback comments, we apply a novel feedback comment quality evaluation framework. This framework is interpretable, cost-efficient, scalable, and reproducible, compared to existing methods that rely on manual judgments. We find that LLMs can generate reasonably good and generally reliable multi-dimensional analytic assessments. We release our corpus for reproducibility.
Zero-Shot Belief: A Hard Problem for LLMs
Feb 12, 2025We present two LLM-based approaches to zero-shot source-and-target belief prediction on FactBank: a unified system that identifies events, sources, and belief labels in a single pass, and a hybrid approach that uses a fine-tuned DeBERTa tagger for event detection. We show that multiple open-sourced, closed-source, and reasoning-based LLMs struggle with the task. Using the hybrid approach, we achieve new state-of-the-art results on FactBank and offer a detailed error analysis. Our approach is then tested on the Italian belief corpus ModaFact.
Synthetic Audio Helps for Cognitive State Tasks
Feb 10, 2025

The NLP community has broadly focused on text-only approaches of cognitive state tasks, but audio can provide vital missing cues through prosody. We posit that text-to-speech models learn to track aspects of cognitive state in order to produce naturalistic audio, and that the signal audio models implicitly identify is orthogonal to the information that language models exploit. We present Synthetic Audio Data fine-tuning (SAD), a framework where we show that 7 tasks related to cognitive state modeling benefit from multimodal training on both text and zero-shot synthetic audio data from an off-the-shelf TTS system. We show an improvement over the text-only modality when adding synthetic audio data to text-only corpora. Furthermore, on tasks and corpora that do contain gold audio, we show our SAD framework achieves competitive performance with text and synthetic audio compared to text and gold audio.
* John Murzaku and Adil Soubki contributed equally to this work
Training LLMs to Recognize Hedges in Spontaneous Narratives
Aug 06, 2024
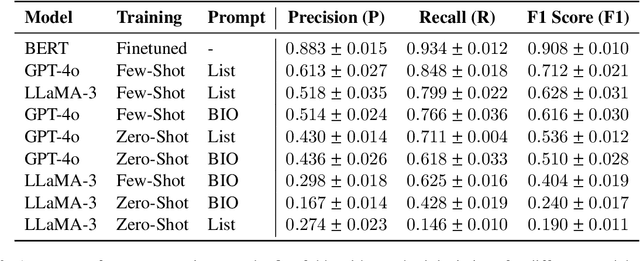

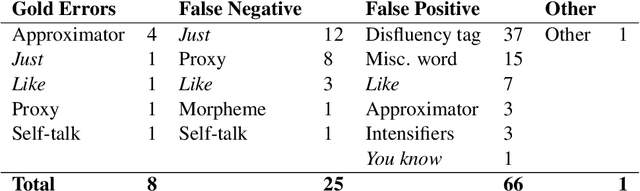
Hedges allow speakers to mark utterances as provisional, whether to signal non-prototypicality or "fuzziness", to indicate a lack of commitment to an utterance, to attribute responsibility for a statement to someone else, to invite input from a partner, or to soften critical feedback in the service of face-management needs. Here we focus on hedges in an experimentally parameterized corpus of 63 Roadrunner cartoon narratives spontaneously produced from memory by 21 speakers for co-present addressees, transcribed to text (Galati and Brennan, 2010). We created a gold standard of hedges annotated by human coders (the Roadrunner-Hedge corpus) and compared three LLM-based approaches for hedge detection: fine-tuning BERT, and zero and few-shot prompting with GPT-4o and LLaMA-3. The best-performing approach was a fine-tuned BERT model, followed by few-shot GPT-4o. After an error analysis on the top performing approaches, we used an LLM-in-the-Loop approach to improve the gold standard coding, as well as to highlight cases in which hedges are ambiguous in linguistically interesting ways that will guide future research. This is the first step in our research program to train LLMs to interpret and generate collateral signals appropriately and meaningfully in conversation.
* Amie Paige, Adil Soubki, and John Murzaku contributed equally to this study
Examining Gender and Power on Wikipedia Through Face and Politeness
Aug 05, 2024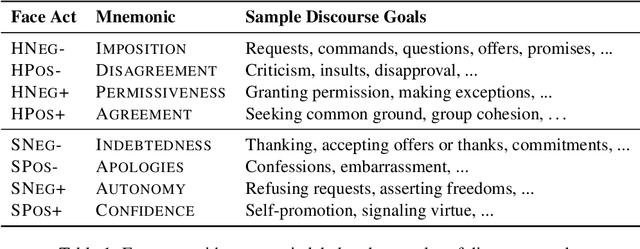
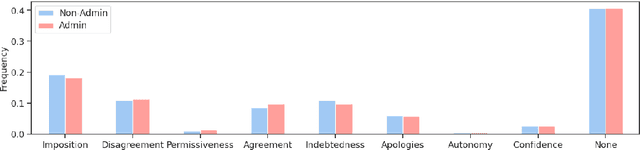

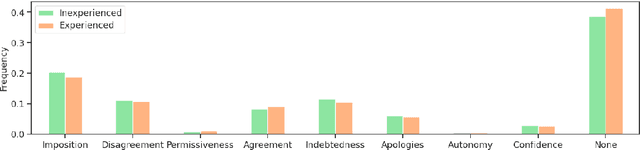
We propose a framework for analyzing discourse by combining two interdependent concepts from sociolinguistic theory: face acts and politeness. While politeness has robust existing tools and data, face acts are less resourced. We introduce a new corpus created by annotating Wikipedia talk pages with face acts and we use this to train a face act tagger. We then employ our framework to study how face and politeness interact with gender and power in discussions between Wikipedia editors. Among other findings, we observe that female Wikipedians are not only more polite, which is consistent with prior studies, but that this difference corresponds with significantly more language directed at humbling aspects of their own face. Interestingly, the distinction nearly vanishes once limiting to editors with administrative power.
Gram2Vec: An Interpretable Document Vectorizer
Jun 17, 2024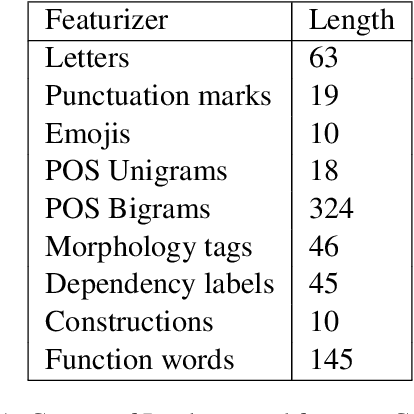



We present Gram2Vec, a grammatical style embedding algorithm that embeds documents into a higher dimensional space by extracting the normalized relative frequencies of grammatical features present in the text. Compared to neural approaches, Gram2Vec offers inherent interpretability based on how the feature vectors are generated. In our demo, we present a way to visualize a mapping of authors to documents based on their Gram2Vec vectors and highlight the ability to drop or add features to view which authors make certain linguistic choices. Next, we use authorship attribution as an application to show how Gram2Vec can explain why a document is attributed to a certain author, using cosine similarities between the Gram2Vec feature vectors to calculate the distances between candidate documents and a query document.
Evaluating LLMs with Multiple Problems at once: A New Paradigm for Probing LLM Capabilities
Jun 16, 2024Current LLM evaluation predominantly performs evaluation with prompts comprising single problems. We propose multi-problem evaluation as an additional approach to study the multiple problem handling capabilities of LLMs. We present a systematic study in this regard by comprehensively examining 7 LLMs on 4 related types of tasks constructed from 6 classification benchmarks. The 4 task types include traditional single-problem tasks, homogeneous multi-problem tasks, and two index selection tasks that embed the multi-problem tasks. We find that LLMs are competent multi-problem solvers: they generally perform (nearly) as well on multi-problem tasks as on single-problem tasks. Furthermore, contrary to common expectation, they often do not suffer from a positional bias with long inputs. This makes multi-problem prompting a simple and cost-efficient prompting method of practical significance. However, our results also strongly indicate that LLMs lack true understanding: they perform significantly worse in the two index selection tasks than in the multi-problem task under various evaluation settings, although they can indeed do index selection in general.