 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymTorch: A Framework for Symbolic Distillation of Deep Neural Networks
Feb 24, 2026Symbolic distillation replaces neural networks, or components thereof, with interpretable, closed-form mathematical expressions. This approach has shown promise in discovering physical laws and mathematical relationships directly from trained deep learning models, yet adoption remains limited due to the engineering barrier of integrating symbolic regression into deep learning workflows. We introduce SymTorch, a library that automates this distillation by wrapping neural network components, collecting their input-output behavior, and approximating them with human-readable equations via PySR. SymTorch handles the engineering challenges that have hindered adoption: GPU-CPU data transfer, input-output caching, model serialization, and seamless switching between neural and symbolic forward passes. We demonstrate SymTorch across diverse architectures including GNNs, PINNs and transformer models. Finally, we present a proof-of-concept for accelerating LLM inference by replacing MLP layers with symbolic surrogates, achieving an 8.3\% throughput improvement with moderate performance degradation.
Synthetic Audio Helps for Cognitive State Tasks
Feb 10, 2025

The NLP community has broadly focused on text-only approaches of cognitive state tasks, but audio can provide vital missing cues through prosody. We posit that text-to-speech models learn to track aspects of cognitive state in order to produce naturalistic audio, and that the signal audio models implicitly identify is orthogonal to the information that language models exploit. We present Synthetic Audio Data fine-tuning (SAD), a framework where we show that 7 tasks related to cognitive state modeling benefit from multimodal training on both text and zero-shot synthetic audio data from an off-the-shelf TTS system. We show an improvement over the text-only modality when adding synthetic audio data to text-only corpora. Furthermore, on tasks and corpora that do contain gold audio, we show our SAD framework achieves competitive performance with text and synthetic audio compared to text and gold audio.
* John Murzaku and Adil Soubki contributed equally to this work
Training LLMs to Recognize Hedges in Spontaneous Narratives
Aug 06, 2024
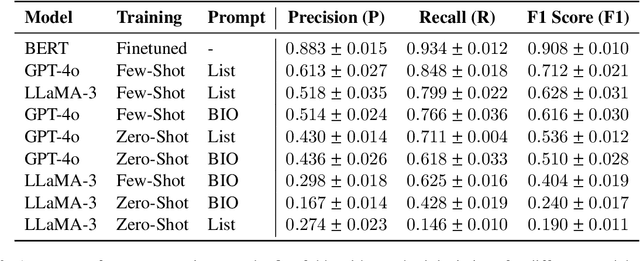

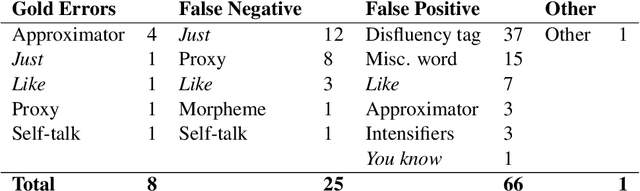
Hedges allow speakers to mark utterances as provisional, whether to signal non-prototypicality or "fuzziness", to indicate a lack of commitment to an utterance, to attribute responsibility for a statement to someone else, to invite input from a partner, or to soften critical feedback in the service of face-management needs. Here we focus on hedges in an experimentally parameterized corpus of 63 Roadrunner cartoon narratives spontaneously produced from memory by 21 speakers for co-present addressees, transcribed to text (Galati and Brennan, 2010). We created a gold standard of hedges annotated by human coders (the Roadrunner-Hedge corpus) and compared three LLM-based approaches for hedge detection: fine-tuning BERT, and zero and few-shot prompting with GPT-4o and LLaMA-3. The best-performing approach was a fine-tuned BERT model, followed by few-shot GPT-4o. After an error analysis on the top performing approaches, we used an LLM-in-the-Loop approach to improve the gold standard coding, as well as to highlight cases in which hedges are ambiguous in linguistically interesting ways that will guide future research. This is the first step in our research program to train LLMs to interpret and generate collateral signals appropriately and meaningfully in conversation.
* Amie Paige, Adil Soubki, and John Murzaku contributed equally to this study
Examining Gender and Power on Wikipedia Through Face and Politeness
Aug 05, 2024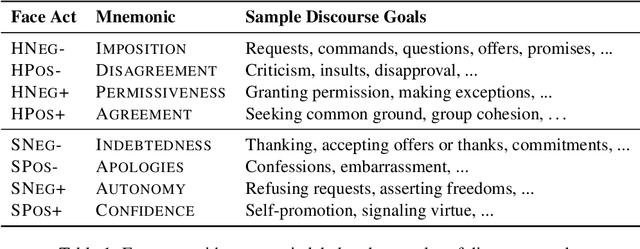
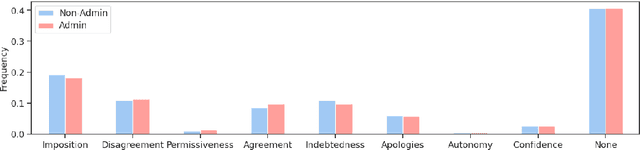

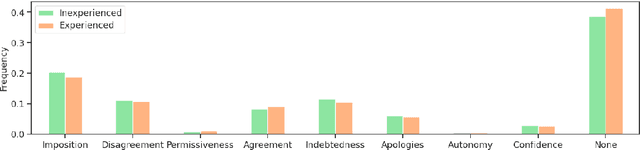
We propose a framework for analyzing discourse by combining two interdependent concepts from sociolinguistic theory: face acts and politeness. While politeness has robust existing tools and data, face acts are less resourced. We introduce a new corpus created by annotating Wikipedia talk pages with face acts and we use this to train a face act tagger. We then employ our framework to study how face and politeness interact with gender and power in discussions between Wikipedia editors. Among other findings, we observe that female Wikipedians are not only more polite, which is consistent with prior studies, but that this difference corresponds with significantly more language directed at humbling aspects of their own face. Interestingly, the distinction nearly vanishes once limiting to editors with administrative power.
Multimodal Belief Prediction
Jun 11, 2024
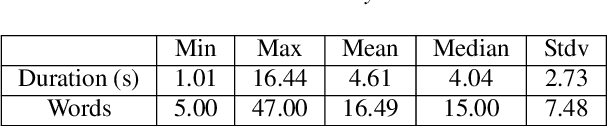


Recognizing a speaker's level of commitment to a belief is a difficult task; humans do not only interpret the meaning of the words in context, but also understand cues from intonation and other aspects of the audio signal. Many papers and corpora in the NLP community have approached the belief prediction task using text-only approaches. We are the first to frame and present results on the multimodal belief prediction task. We use the CB-Prosody corpus (CBP), containing aligned text and audio with speaker belief annotations. We first report baselines and significant features using acoustic-prosodic features and traditional machine learning methods. We then present text and audio baselines for the CBP corpus fine-tuning on BERT and Whisper respectively. Finally, we present our multimodal architecture which fine-tunes on BERT and Whisper and uses multiple fusion methods, improving on both modalities alone.
* John Murzaku and Adil Soubki contributed equally to this work
Intention and Face in Dialog
Jun 06, 2024
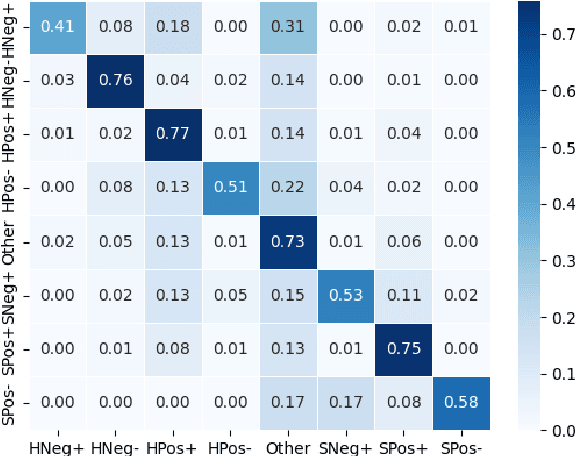


The notion of face described by Brown and Levinson (1987) has been studied in great detail, but a critical aspect of the framework, that which focuses on how intentions mediate the planning of turns which impose upon face, has received far less attention. We present an analysis of three computational systems trained for classifying both intention and politeness, focusing on how the former influences the latter. In politeness theory, agents attend to the desire to have their wants appreciated (positive face), and a complementary desire to act unimpeded and maintain freedom (negative face). Similar to speech acts, utterances can perform so-called face acts which can either raise or threaten the positive or negative face of the speaker or hearer. We begin by using an existing corpus to train a model which classifies face acts, achieving a new SoTA in the process. We then observe that every face act has an underlying intention that motivates it and perform additional experiments integrating dialog act annotations to provide these intentions by proxy. Our analysis finds that dialog acts improve performance on face act detection for minority classes and points to a close relationship between aspects of face and intent.
Views Are My Own, But Also Yours: Benchmarking Theory of Mind using Common Ground
Mar 04, 2024



Evaluating the theory of mind (ToM) capabilities of language models (LMs) has recently received much attention. However, many existing benchmarks rely on synthetic data which risks misaligning the resulting experiments with human behavior. We introduce the first ToM dataset based on naturally occurring spoken dialogs, Common-ToM, and show that LMs struggle to demonstrate ToM. We then show that integrating a simple, explicit representation of beliefs improves LM performance on Common-ToM.
Finding Common Ground: Annotating and Predicting Common Ground in Spoken Conversations
Nov 02, 2023



When we communicate with other humans, we do not simply generate a sequence of words. Rather, we use our cognitive state (beliefs, desires, intentions) and our model of the audience's cognitive state to create utterances that affect the audience's cognitive state in the intended manner. An important part of cognitive state is the common ground, which is the content the speaker believes, and the speaker believes the audience believes, and so on. While much attention has been paid to common ground in cognitive science, there has not been much work in natural language processing. In this paper, we introduce a new annotation and corpus to capture common ground. We then describe some initial experiments extracting propositions from dialog and tracking their status in the common ground from the perspective of each speaker.