 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining LLMs to Recognize Hedges in Spontaneous Narratives
Aug 06, 2024
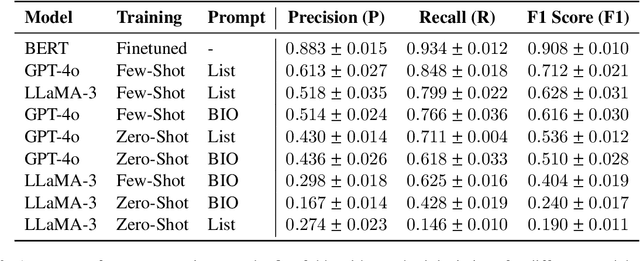

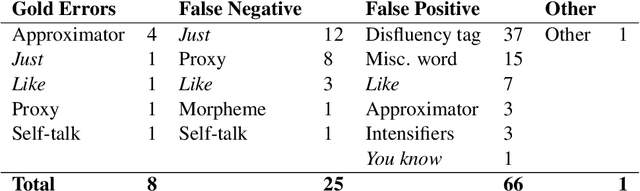
Hedges allow speakers to mark utterances as provisional, whether to signal non-prototypicality or "fuzziness", to indicate a lack of commitment to an utterance, to attribute responsibility for a statement to someone else, to invite input from a partner, or to soften critical feedback in the service of face-management needs. Here we focus on hedges in an experimentally parameterized corpus of 63 Roadrunner cartoon narratives spontaneously produced from memory by 21 speakers for co-present addressees, transcribed to text (Galati and Brennan, 2010). We created a gold standard of hedges annotated by human coders (the Roadrunner-Hedge corpus) and compared three LLM-based approaches for hedge detection: fine-tuning BERT, and zero and few-shot prompting with GPT-4o and LLaMA-3. The best-performing approach was a fine-tuned BERT model, followed by few-shot GPT-4o. After an error analysis on the top performing approaches, we used an LLM-in-the-Loop approach to improve the gold standard coding, as well as to highlight cases in which hedges are ambiguous in linguistically interesting ways that will guide future research. This is the first step in our research program to train LLMs to interpret and generate collateral signals appropriately and meaningfully in conversation.
* Amie Paige, Adil Soubki, and John Murzaku contributed equally to this study
A Centering Approach to Pronouns
Oct 10, 1994

In this paper we present a formalization of the centering approach to modeling attentional structure in discourse and use it as the basis for an algorithm to track discourse context and bind pronouns. As described in Grosz, Joshi and Weinstein (1986), the process of centering attention on entities in the discourse gives rise to the intersentential transitional states of continuing, retaining and shifting. We propose an extension to these states which handles some additional cases of multiple ambiguous pronouns. The algorithm has been implemented in an HPSG natural language system which serves as the interface to a database query application.
* plain latex but includes psfig.tex, 8 pages with one psfig, published in 25th Annual Meeting of the Association of Computational Linguistics, 1987