 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Education and Research: An Empirical and User Survey-based Analysis
Dec 08, 2025Pretrained Large Language Models (LLMs) have achieved remarkable success across diverse domains, with education and research emerging as particularly impactful areas. Among current state-of-the-art LLMs, ChatGPT and DeepSeek exhibit strong capabilities in mathematics, science, medicine, literature, and programming. In this study, we present a comprehensive evaluation of these two LLMs through background technology analysis, empirical experiments, and a real-world user survey. The evaluation explores trade-offs among model accuracy, computational efficiency, and user experience in educational and research affairs. We benchmarked these LLMs performance in text generation, programming, and specialized problem-solving. Experimental results show that ChatGPT excels in general language understanding and text generation, while DeepSeek demonstrates superior performance in programming tasks due to its efficiency-focused design. Moreover, both models deliver medically accurate diagnostic outputs and effectively solve complex mathematical problems. Complementing these quantitative findings, a survey of students, educators, and researchers highlights the practical benefits and limitations of these models, offering deeper insights into their role in advancing education and research.
Intelligent Multimodal Multi-Sensor Fusion-Based UAV Identification, Localization, and Countermeasures for Safeguarding Low-Altitude Economy
Oct 27, 2025The development of the low-altitude economy has led to a growing prominence of uncrewed aerial vehicle (UAV) safety management issues. Therefore, accurate identification, real-time localization, and effective countermeasures have become core challenges in airspace security assurance. This paper introduces an integrated UAV management and control system based on deep learning, which integrates multimodal multi-sensor fusion perception, precise positioning, and collaborative countermeasures. By incorporating deep learning methods, the system combines radio frequency (RF) spectral feature analysis, radar detection, electro-optical identification, and other methods at the detection level to achieve the identification and classification of UAVs. At the localization level, the system relies on multi-sensor data fusion and the air-space-ground integrated communication network to conduct real-time tracking and prediction of UAV flight status, providing support for early warning and decision-making. At the countermeasure level, it adopts comprehensive measures that integrate ``soft kill'' and ``hard kill'', including technologies such as electromagnetic signal jamming, navigation spoofing, and physical interception, to form a closed-loop management and control process from early warning to final disposal, which significantly enhances the response efficiency and disposal accuracy of low-altitude UAV management.
Breaking the Static Assumption: A Dynamic-Aware LIO Framework Via Spatio-Temporal Normal Analysis
Oct 25, 2025This paper addresses the challenge of Lidar-Inertial Odometry (LIO) in dynamic environments, where conventional methods often fail due to their static-world assumptions. Traditional LIO algorithms perform poorly when dynamic objects dominate the scenes, particularly in geometrically sparse environments. Current approaches to dynamic LIO face a fundamental challenge: accurate localization requires a reliable identification of static features, yet distinguishing dynamic objects necessitates precise pose estimation. Our solution breaks this circular dependency by integrating dynamic awareness directly into the point cloud registration process. We introduce a novel dynamic-aware iterative closest point algorithm that leverages spatio-temporal normal analysis, complemented by an efficient spatial consistency verification method to enhance static map construction. Experimental evaluations demonstrate significant performance improvements over state-of-the-art LIO systems in challenging dynamic environments with limited geometric structure. The code and dataset are available at https://github.com/thisparticle/btsa.
Regional Weather Variable Predictions by Machine Learning with Near-Surface Observational and Atmospheric Numerical Data
Dec 11, 2024



Accurate and timely regional weather prediction is vital for sectors dependent on weather-related decisions. Traditional prediction methods, based on atmospheric equations, often struggle with coarse temporal resolutions and inaccuracies. This paper presents a novel machine learning (ML) model, called MiMa (short for Micro-Macro), that integrates both near-surface observational data from Kentucky Mesonet stations (collected every five minutes, known as Micro data) and hourly atmospheric numerical outputs (termed as Macro data) for fine-resolution weather forecasting. The MiMa model employs an encoder-decoder transformer structure, with two encoders for processing multivariate data from both datasets and a decoder for forecasting weather variables over short time horizons. Each instance of the MiMa model, called a modelet, predicts the values of a specific weather parameter at an individual Mesonet station. The approach is extended with Re-MiMa modelets, which are designed to predict weather variables at ungauged locations by training on multivariate data from a few representative stations in a region, tagged with their elevations. Re-MiMa (short for Regional-MiMa) can provide highly accurate predictions across an entire region, even in areas without observational stations. Experimental results show that MiMa significantly outperforms current models, with Re-MiMa offering precise short-term forecasts for ungauged locations, marking a significant advancement in weather forecasting accuracy and applicability.
Open Challenges and Opportunities in Federated Foundation Models Towards Biomedical Healthcare
May 10, 2024This survey explores the transformative impact of foundation models (FMs) in artificial intelligence, focusing on their integration with federated learning (FL) for advancing biomedical research. Foundation models such as ChatGPT, LLaMa, and CLIP, which are trained on vast datasets through methods including unsupervised pretraining, self-supervised learning, instructed fine-tuning, and reinforcement learning from human feedback, represent significant advancements in machine learning. These models, with their ability to generate coherent text and realistic images, are crucial for biomedical applications that require processing diverse data forms such as clinical reports, diagnostic images, and multimodal patient interactions. The incorporation of FL with these sophisticated models presents a promising strategy to harness their analytical power while safeguarding the privacy of sensitive medical data. This approach not only enhances the capabilities of FMs in medical diagnostics and personalized treatment but also addresses critical concerns about data privacy and security in healthcare. This survey reviews the current applications of FMs in federated settings, underscores the challenges, and identifies future research directions including scaling FMs, managing data diversity, and enhancing communication efficiency within FL frameworks. The objective is to encourage further research into the combined potential of FMs and FL, laying the groundwork for groundbreaking healthcare innovations.
Text-driven Prompt Generation for Vision-Language Models in Federated Learning
Oct 09, 2023



Prompt learning for vision-language models, e.g., CoOp, has shown great success in adapting CLIP to different downstream tasks, making it a promising solution for federated learning due to computational reasons. Existing prompt learning techniques replace hand-crafted text prompts with learned vectors that offer improvements on seen classes, but struggle to generalize to unseen classes. Our work addresses this challenge by proposing Federated Text-driven Prompt Generation (FedTPG), which learns a unified prompt generation network across multiple remote clients in a scalable manner. The prompt generation network is conditioned on task-related text input, thus is context-aware, making it suitable to generalize for both seen and unseen classes. Our comprehensive empirical evaluations on nine diverse image classification datasets show that our method is superior to existing federated prompt learning methods, that achieve overall better generalization on both seen and unseen classes and is also generalizable to unseen datasets.
MMST-ViT: Climate Change-aware Crop Yield Prediction via Multi-Modal Spatial-Temporal Vision Transformer
Sep 19, 2023



Precise crop yield prediction provides valuable information for agricultural planning and decision-making processes. However, timely predicting crop yields remains challenging as crop growth is sensitive to growing season weather variation and climate change. In this work, we develop a deep learning-based solution, namely Multi-Modal Spatial-Temporal Vision Transformer (MMST-ViT), for predicting crop yields at the county level across the United States, by considering the effects of short-term meteorological variations during the growing season and the long-term climate change on crops. Specifically, our MMST-ViT consists of a Multi-Modal Transformer, a Spatial Transformer, and a Temporal Transformer. The Multi-Modal Transformer leverages both visual remote sensing data and short-term meteorological data for modeling the effect of growing season weather variations on crop growth. The Spatial Transformer learns the high-resolution spatial dependency among counties for accurate agricultural tracking. The Temporal Transformer captures the long-range temporal dependency for learning the impact of long-term climate change on crops. Meanwhile, we also devise a novel multi-modal contrastive learning technique to pre-train our model without extensive human supervision. Hence, our MMST-ViT captures the impacts of both short-term weather variations and long-term climate change on crops by leveraging both satellite images and meteorological data. We have conducted extensive experiments on over 200 counties in the United States, with the experimental results exhibiting that our MMST-ViT outperforms its counterparts under three performance metrics of interest.
Transformer-based Joint Source Channel Coding for Textual Semantic Communication
Jul 23, 2023
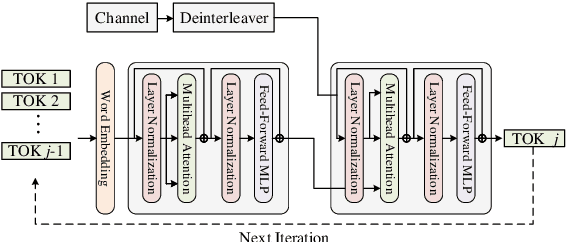
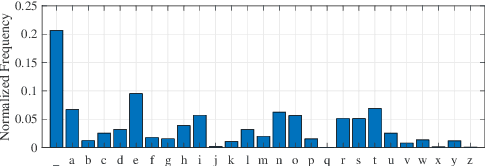
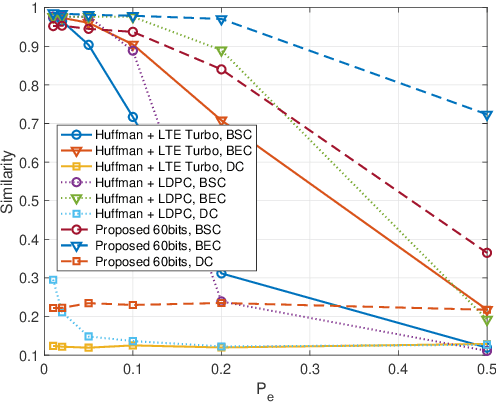
The Space-Air-Ground-Sea integrated network calls for more robust and secure transmission techniques against jamming. In this paper, we propose a textual semantic transmission framework for robust transmission, which utilizes the advanced natural language processing techniques to model and encode sentences. Specifically, the textual sentences are firstly split into tokens using wordpiece algorithm, and are embedded to token vectors for semantic extraction by Transformer-based encoder. The encoded data are quantized to a fixed length binary sequence for transmission, where binary erasure, symmetric, and deletion channels are considered for transmission. The received binary sequences are further decoded by the transformer decoders into tokens used for sentence reconstruction. Our proposed approach leverages the power of neural networks and attention mechanism to provide reliable and efficient communication of textual data in challenging wireless environments, and simulation results on semantic similarity and bilingual evaluation understudy prove the superiority of the proposed model in semantic transmission.
Hardware Accelerator for Adversarial Attacks on Deep Learning Neural Networks
Aug 03, 2020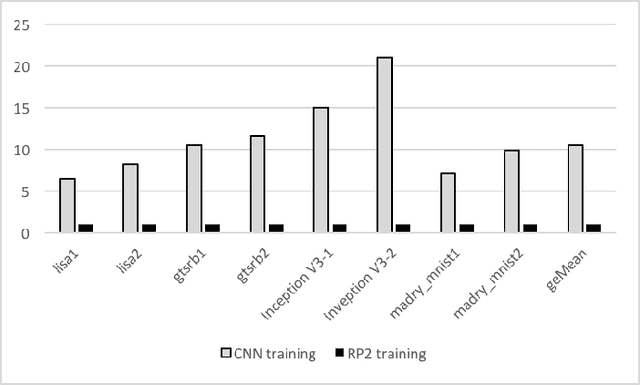
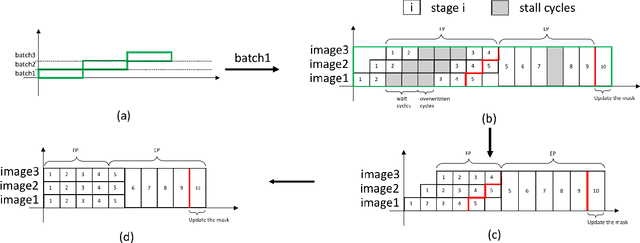
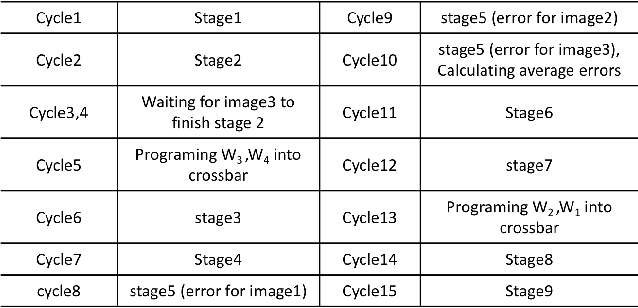
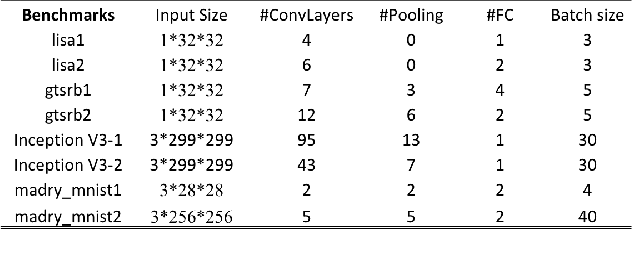
Recent studies identify that Deep learning Neural Networks (DNNs) are vulnerable to subtle perturbations, which are not perceptible to human visual system but can fool the DNN models and lead to wrong outputs. A class of adversarial attack network algorithms has been proposed to generate robust physical perturbations under different circumstances. These algorithms are the first efforts to move forward secure deep learning by providing an avenue to train future defense networks, however, the intrinsic complexity of them prevents their broader usage. In this paper, we propose the first hardware accelerator for adversarial attacks based on memristor crossbar arrays. Our design significantly improves the throughput of a visual adversarial perturbation system, which can further improve the robustness and security of future deep learning systems. Based on the algorithm uniqueness, we propose four implementations for the adversarial attack accelerator ($A^3$) to improve the throughput, energy efficiency, and computational efficiency.
* IGSC'2019 (https://shirazi21.wixsite.com/igsc2019archive) Best paper award