 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Protein Transformers Have Biological Intelligence?
Jun 07, 2025Deep neural networks, particularly Transformers, have been widely adopted for predicting the functional properties of proteins. In this work, we focus on exploring whether Protein Transformers can capture biological intelligence among protein sequences. To achieve our goal, we first introduce a protein function dataset, namely Protein-FN, providing over 9000 protein data with meaningful labels. Second, we devise a new Transformer architecture, namely Sequence Protein Transformers (SPT), for computationally efficient protein function predictions. Third, we develop a novel Explainable Artificial Intelligence (XAI) technique called Sequence Score, which can efficiently interpret the decision-making processes of protein models, thereby overcoming the difficulty of deciphering biological intelligence bided in Protein Transformers. Remarkably, even our smallest SPT-Tiny model, which contains only 5.4M parameters, demonstrates impressive predictive accuracy, achieving 94.3% on the Antibiotic Resistance (AR) dataset and 99.6% on the Protein-FN dataset, all accomplished by training from scratch. Besides, our Sequence Score technique helps reveal that our SPT models can discover several meaningful patterns underlying the sequence structures of protein data, with these patterns aligning closely with the domain knowledge in the biology community. We have officially released our Protein-FN dataset on Hugging Face Datasets https://huggingface.co/datasets/Protein-FN/Protein-FN. Our code is available at https://github.com/fudong03/BioIntelligence.
ECGN: A Cluster-Aware Approach to Graph Neural Networks for Imbalanced Classification
Oct 15, 2024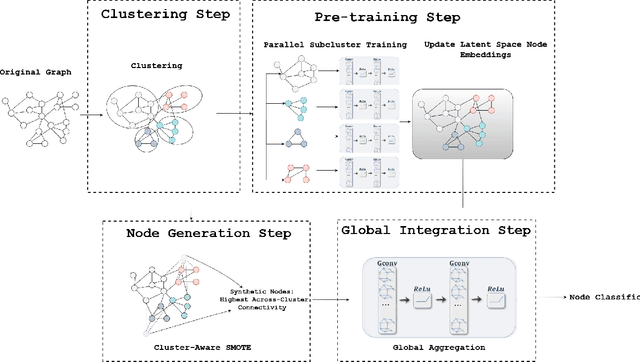



Classifying nodes in a graph is a common problem. The ideal classifier must adapt to any imbalances in the class distribution. It must also use information in the clustering structure of real-world graphs. Existing Graph Neural Networks (GNNs) have not addressed both problems together. We propose the Enhanced Cluster-aware Graph Network (ECGN), a novel method that addresses these issues by integrating cluster-specific training with synthetic node generation. Unlike traditional GNNs that apply the same node update process for all nodes, ECGN learns different aggregations for different clusters. We also use the clusters to generate new minority-class nodes in a way that helps clarify the inter-class decision boundary. By combining cluster-aware embeddings with a global integration step, ECGN enhances the quality of the resulting node embeddings. Our method works with any underlying GNN and any cluster generation technique. Experimental results show that ECGN consistently outperforms its closest competitors by up to 11% on some widely studied benchmark datasets.
Towards Robust Vision Transformer via Masked Adaptive Ensemble
Jul 22, 2024
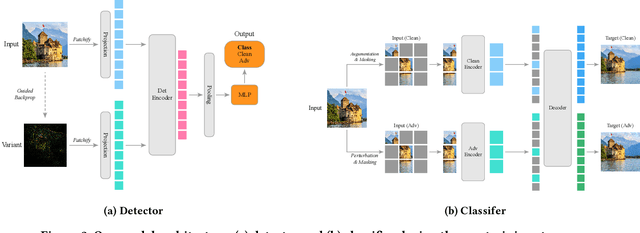
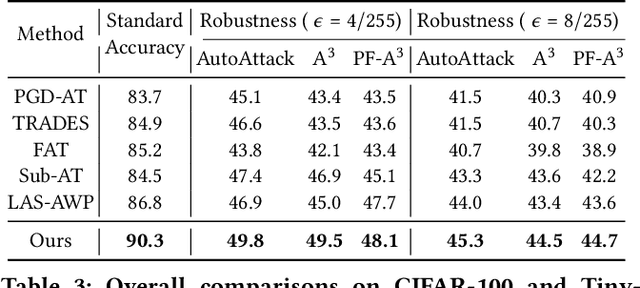
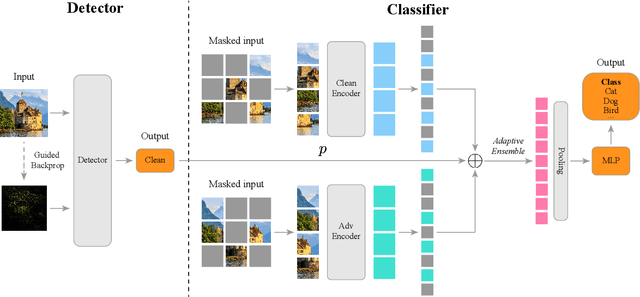
Adversarial training (AT) can help improve the robustness of Vision Transformers (ViT) against adversarial attacks by intentionally injecting adversarial examples into the training data. However, this way of adversarial injection inevitably incurs standard accuracy degradation to some extent, thereby calling for a trade-off between standard accuracy and robustness. Besides, the prominent AT solutions are still vulnerable to adaptive attacks. To tackle such shortcomings, this paper proposes a novel ViT architecture, including a detector and a classifier bridged by our newly developed adaptive ensemble. Specifically, we empirically discover that detecting adversarial examples can benefit from the Guided Backpropagation technique. Driven by this discovery, a novel Multi-head Self-Attention (MSA) mechanism is introduced to enhance our detector to sniff adversarial examples. Then, a classifier with two encoders is employed for extracting visual representations respectively from clean images and adversarial examples, with our adaptive ensemble to adaptively adjust the proportion of visual representations from the two encoders for accurate classification. This design enables our ViT architecture to achieve a better trade-off between standard accuracy and robustness. Besides, our adaptive ensemble technique allows us to mask off a random subset of image patches within input data, boosting our ViT's robustness against adaptive attacks, while maintaining high standard accuracy. Experimental results exhibit that our ViT architecture, on CIFAR-10, achieves the best standard accuracy and adversarial robustness of 90.3% and 49.8%, respectively.
* 9 pages
An Open and Large-Scale Dataset for Multi-Modal Climate Change-aware Crop Yield Predictions
Jun 10, 2024



Precise crop yield predictions are of national importance for ensuring food security and sustainable agricultural practices. While AI-for-science approaches have exhibited promising achievements in solving many scientific problems such as drug discovery, precipitation nowcasting, etc., the development of deep learning models for predicting crop yields is constantly hindered by the lack of an open and large-scale deep learning-ready dataset with multiple modalities to accommodate sufficient information. To remedy this, we introduce the CropNet dataset, the first terabyte-sized, publicly available, and multi-modal dataset specifically targeting climate change-aware crop yield predictions for the contiguous United States (U.S.) continent at the county level. Our CropNet dataset is composed of three modalities of data, i.e., Sentinel-2 Imagery, WRF-HRRR Computed Dataset, and USDA Crop Dataset, for over 2200 U.S. counties spanning 6 years (2017-2022), expected to facilitate researchers in developing versatile deep learning models for timely and precisely predicting crop yields at the county-level, by accounting for the effects of both short-term growing season weather variations and long-term climate change on crop yields. Besides, we develop the CropNet package, offering three types of APIs, for facilitating researchers in downloading the CropNet data on the fly over the time and region of interest, and flexibly building their deep learning models for accurate crop yield predictions. Extensive experiments have been conducted on our CropNet dataset via employing various types of deep learning solutions, with the results validating the general applicability and the efficacy of the CropNet dataset in climate change-aware crop yield predictions.
* 13 pages
MMST-ViT: Climate Change-aware Crop Yield Prediction via Multi-Modal Spatial-Temporal Vision Transformer
Sep 19, 2023



Precise crop yield prediction provides valuable information for agricultural planning and decision-making processes. However, timely predicting crop yields remains challenging as crop growth is sensitive to growing season weather variation and climate change. In this work, we develop a deep learning-based solution, namely Multi-Modal Spatial-Temporal Vision Transformer (MMST-ViT), for predicting crop yields at the county level across the United States, by considering the effects of short-term meteorological variations during the growing season and the long-term climate change on crops. Specifically, our MMST-ViT consists of a Multi-Modal Transformer, a Spatial Transformer, and a Temporal Transformer. The Multi-Modal Transformer leverages both visual remote sensing data and short-term meteorological data for modeling the effect of growing season weather variations on crop growth. The Spatial Transformer learns the high-resolution spatial dependency among counties for accurate agricultural tracking. The Temporal Transformer captures the long-range temporal dependency for learning the impact of long-term climate change on crops. Meanwhile, we also devise a novel multi-modal contrastive learning technique to pre-train our model without extensive human supervision. Hence, our MMST-ViT captures the impacts of both short-term weather variations and long-term climate change on crops by leveraging both satellite images and meteorological data. We have conducted extensive experiments on over 200 counties in the United States, with the experimental results exhibiting that our MMST-ViT outperforms its counterparts under three performance metrics of interest.