 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource Heterogeneity-Aware and Utilization-Enhanced Scheduling for Deep Learning Clusters
Mar 13, 2025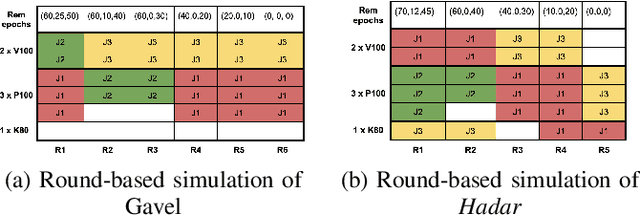
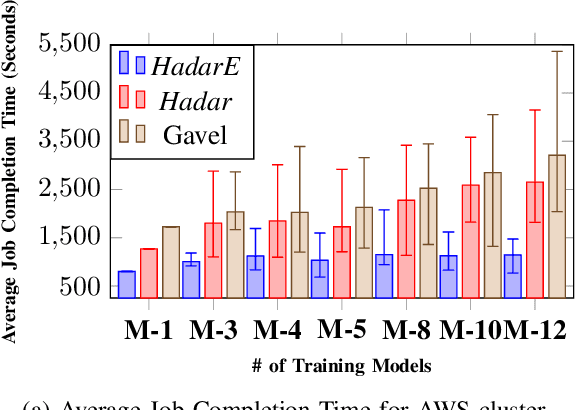
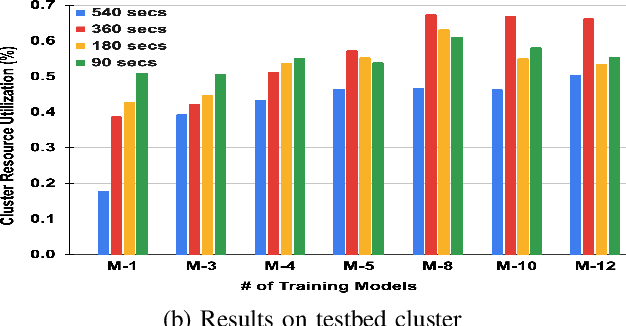
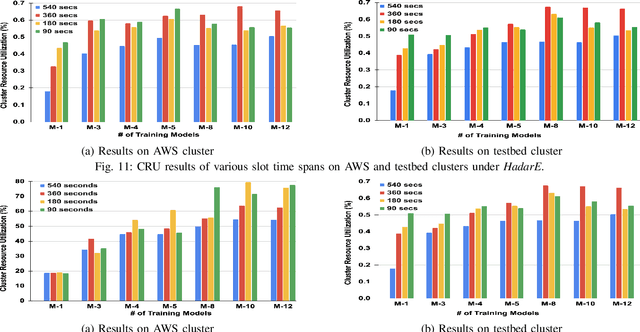
Scheduling deep learning (DL) models to train on powerful clusters with accelerators like GPUs and TPUs, presently falls short, either lacking fine-grained heterogeneity awareness or leaving resources substantially under-utilized. To fill this gap, we propose a novel design of a task-level heterogeneity-aware scheduler, {\em Hadar}, based on an optimization framework that can boost resource utilization. {\em Hadar} leverages the performance traits of DL jobs on a heterogeneous DL cluster, characterizes the task-level performance heterogeneity in the optimization problem, and makes scheduling decisions across both spatial and temporal dimensions. %with the objective to reduce the average job completion time of DL jobs. It involves the primal-dual framework employing a dual subroutine, to solve the optimization problem and guide the scheduling design. Our trace-driven simulation with representative DL model training workloads demonstrates that {\em Hadar} accelerates the total time duration by 1.20$\times$ when compared with its state-of-the-art heterogeneity-aware counterpart, Gavel. Further, our {\em Hadar} scheduler is enhanced to {\em HadarE} by forking each job into multiple copies to let a job train concurrently on heterogeneous GPUs resided on separate available nodes (i.e., machines or servers) for resource utilization enhancement. {\em HadarE} is evaluated extensively on physical DL clusters for comparison with {\em Hadar} and Gavel. With substantial enhancement in cluster resource utilization (by 1.45$\times$), {\em HadarE} exhibits considerable speed-ups in DL model training, reducing the total time duration by 50\% (or 80\%) on an Amazon's AWS (or our lab) cluster, while producing trained DL models with consistently better inference quality than those trained by \textit{Hadar}.
GRID: Protecting Training Graph from Link Stealing Attacks on GNN Models
Jan 19, 2025



Graph neural networks (GNNs) have exhibited superior performance in various classification tasks on graph-structured data. However, they encounter the potential vulnerability from the link stealing attacks, which can infer the presence of a link between two nodes via measuring the similarity of its incident nodes' prediction vectors produced by a GNN model. Such attacks pose severe security and privacy threats to the training graph used in GNN models. In this work, we propose a novel solution, called Graph Link Disguise (GRID), to defend against link stealing attacks with the formal guarantee of GNN model utility for retaining prediction accuracy. The key idea of GRID is to add carefully crafted noises to the nodes' prediction vectors for disguising adjacent nodes as n-hop indirect neighboring nodes. We take into account the graph topology and select only a subset of nodes (called core nodes) covering all links for adding noises, which can avert the noises offset and have the further advantages of reducing both the distortion loss and the computation cost. Our crafted noises can ensure 1) the noisy prediction vectors of any two adjacent nodes have their similarity level like that of two non-adjacent nodes and 2) the model prediction is unchanged to ensure zero utility loss. Extensive experiments on five datasets are conducted to show the effectiveness of our proposed GRID solution against different representative link-stealing attacks under transductive settings and inductive settings respectively, as well as two influence-based attacks. Meanwhile, it achieves a much better privacy-utility trade-off than existing methods when extended to GNNs.
Incentive-Compatible Federated Learning with Stackelberg Game Modeling
Jan 05, 2025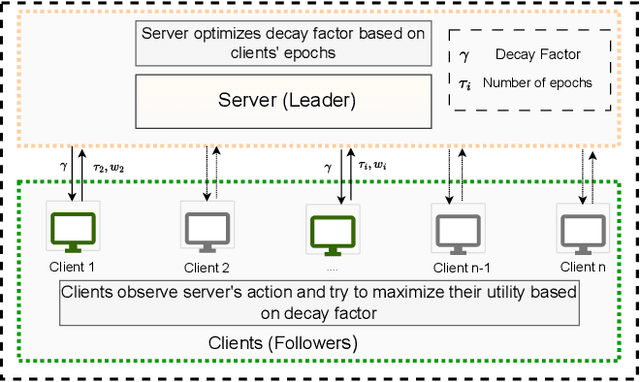

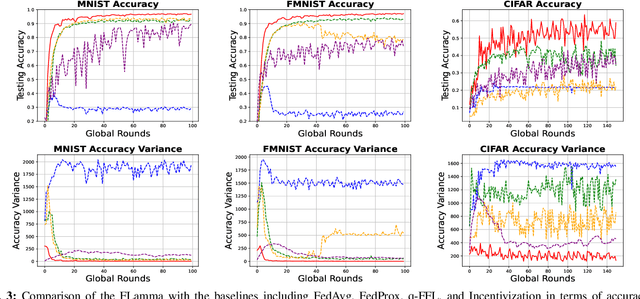
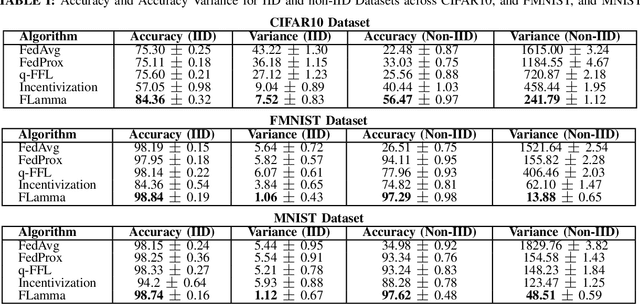
Federated Learning (FL) has gained prominence as a decentralized machine learning paradigm, allowing clients to collaboratively train a global model while preserving data privacy. Despite its potential, FL faces significant challenges in heterogeneous environments, where varying client resources and capabilities can undermine overall system performance. Existing approaches primarily focus on maximizing global model accuracy, often at the expense of unfairness among clients and suboptimal system efficiency, particularly in non-IID (non-Independent and Identically Distributed) settings. In this paper, we introduce FLamma, a novel Federated Learning framework based on adaptive gamma-based Stackelberg game, designed to address the aforementioned limitations and promote fairness. Our approach allows the server to act as the leader, dynamically adjusting a decay factor while clients, acting as followers, optimally select their number of local epochs to maximize their utility. Over time, the server incrementally balances client influence, initially rewarding higher-contributing clients and gradually leveling their impact, driving the system toward a Stackelberg Equilibrium. Extensive simulations on both IID and non-IID datasets show that our method significantly improves fairness in accuracy distribution without compromising overall model performance or convergence speed, outperforming traditional FL baselines.
Regional Weather Variable Predictions by Machine Learning with Near-Surface Observational and Atmospheric Numerical Data
Dec 11, 2024



Accurate and timely regional weather prediction is vital for sectors dependent on weather-related decisions. Traditional prediction methods, based on atmospheric equations, often struggle with coarse temporal resolutions and inaccuracies. This paper presents a novel machine learning (ML) model, called MiMa (short for Micro-Macro), that integrates both near-surface observational data from Kentucky Mesonet stations (collected every five minutes, known as Micro data) and hourly atmospheric numerical outputs (termed as Macro data) for fine-resolution weather forecasting. The MiMa model employs an encoder-decoder transformer structure, with two encoders for processing multivariate data from both datasets and a decoder for forecasting weather variables over short time horizons. Each instance of the MiMa model, called a modelet, predicts the values of a specific weather parameter at an individual Mesonet station. The approach is extended with Re-MiMa modelets, which are designed to predict weather variables at ungauged locations by training on multivariate data from a few representative stations in a region, tagged with their elevations. Re-MiMa (short for Regional-MiMa) can provide highly accurate predictions across an entire region, even in areas without observational stations. Experimental results show that MiMa significantly outperforms current models, with Re-MiMa offering precise short-term forecasts for ungauged locations, marking a significant advancement in weather forecasting accuracy and applicability.
Knowledge Bases in Support of Large Language Models for Processing Web News
Nov 14, 2024

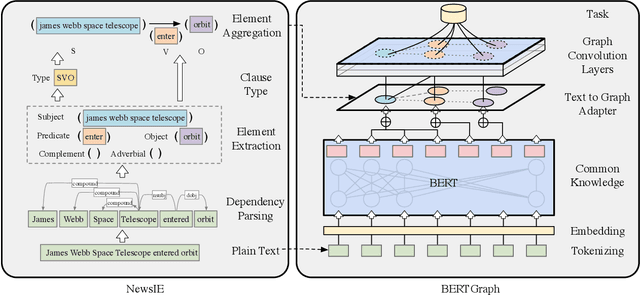
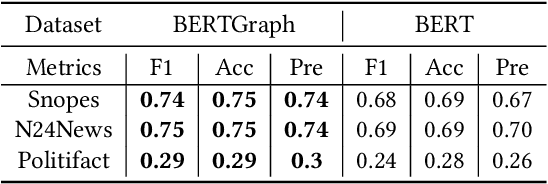
Large Language Models (LLMs) have received considerable interest in wide applications lately. During pre-training via massive datasets, such a model implicitly memorizes the factual knowledge of trained datasets in its hidden parameters. However, knowledge held implicitly in parameters often makes its use by downstream applications ineffective due to the lack of common-sense reasoning. In this article, we introduce a general framework that permits to build knowledge bases with an aid of LLMs, tailored for processing Web news. The framework applies a rule-based News Information Extractor (NewsIE) to news items for extracting their relational tuples, referred to as knowledge bases, which are then graph-convoluted with the implicit knowledge facts of news items obtained by LLMs, for their classification. It involves two lightweight components: 1) NewsIE: for extracting the structural information of every news item, in the form of relational tuples; 2) BERTGraph: for graph convoluting the implicit knowledge facts with relational tuples extracted by NewsIE. We have evaluated our framework under different news-related datasets for news category classification, with promising experimental results.
Towards Robust Vision Transformer via Masked Adaptive Ensemble
Jul 22, 2024
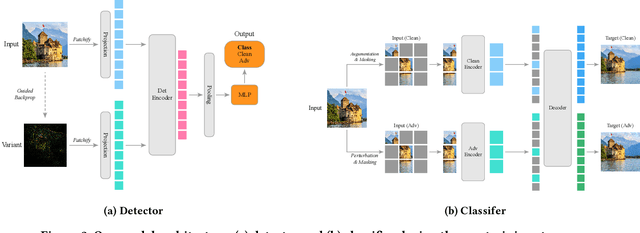
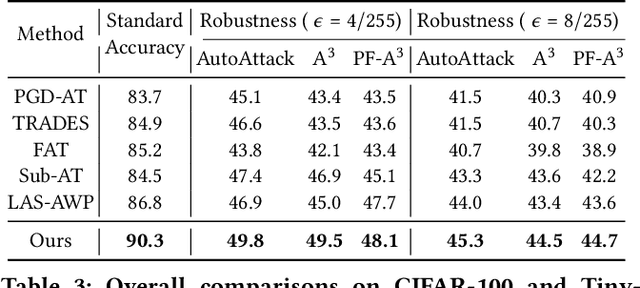
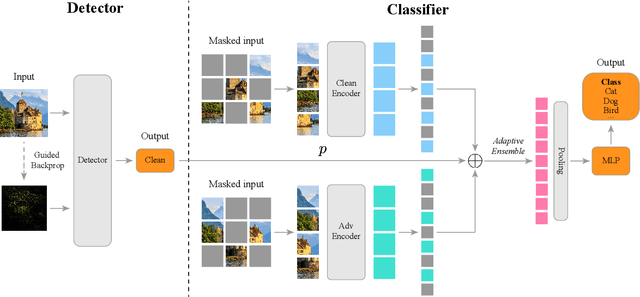
Adversarial training (AT) can help improve the robustness of Vision Transformers (ViT) against adversarial attacks by intentionally injecting adversarial examples into the training data. However, this way of adversarial injection inevitably incurs standard accuracy degradation to some extent, thereby calling for a trade-off between standard accuracy and robustness. Besides, the prominent AT solutions are still vulnerable to adaptive attacks. To tackle such shortcomings, this paper proposes a novel ViT architecture, including a detector and a classifier bridged by our newly developed adaptive ensemble. Specifically, we empirically discover that detecting adversarial examples can benefit from the Guided Backpropagation technique. Driven by this discovery, a novel Multi-head Self-Attention (MSA) mechanism is introduced to enhance our detector to sniff adversarial examples. Then, a classifier with two encoders is employed for extracting visual representations respectively from clean images and adversarial examples, with our adaptive ensemble to adaptively adjust the proportion of visual representations from the two encoders for accurate classification. This design enables our ViT architecture to achieve a better trade-off between standard accuracy and robustness. Besides, our adaptive ensemble technique allows us to mask off a random subset of image patches within input data, boosting our ViT's robustness against adaptive attacks, while maintaining high standard accuracy. Experimental results exhibit that our ViT architecture, on CIFAR-10, achieves the best standard accuracy and adversarial robustness of 90.3% and 49.8%, respectively.
* 9 pages
FedClust: Tackling Data Heterogeneity in Federated Learning through Weight-Driven Client Clustering
Jul 09, 2024Federated learning (FL) is an emerging distributed machine learning paradigm that enables collaborative training of machine learning models over decentralized devices without exposing their local data. One of the major challenges in FL is the presence of uneven data distributions across client devices, violating the well-known assumption of independent-and-identically-distributed (IID) training samples in conventional machine learning. To address the performance degradation issue incurred by such data heterogeneity, clustered federated learning (CFL) shows its promise by grouping clients into separate learning clusters based on the similarity of their local data distributions. However, state-of-the-art CFL approaches require a large number of communication rounds to learn the distribution similarities during training until the formation of clusters is stabilized. Moreover, some of these algorithms heavily rely on a predefined number of clusters, thus limiting their flexibility and adaptability. In this paper, we propose {\em FedClust}, a novel approach for CFL that leverages the correlation between local model weights and the data distribution of clients. {\em FedClust} groups clients into clusters in a one-shot manner by measuring the similarity degrees among clients based on the strategically selected partial weights of locally trained models. We conduct extensive experiments on four benchmark datasets with different non-IID data settings. Experimental results demonstrate that {\em FedClust} achieves higher model accuracy up to $\sim$45\% as well as faster convergence with a significantly reduced communication cost up to 2.7$\times$ compared to its state-of-the-art counterparts.
An Open and Large-Scale Dataset for Multi-Modal Climate Change-aware Crop Yield Predictions
Jun 10, 2024



Precise crop yield predictions are of national importance for ensuring food security and sustainable agricultural practices. While AI-for-science approaches have exhibited promising achievements in solving many scientific problems such as drug discovery, precipitation nowcasting, etc., the development of deep learning models for predicting crop yields is constantly hindered by the lack of an open and large-scale deep learning-ready dataset with multiple modalities to accommodate sufficient information. To remedy this, we introduce the CropNet dataset, the first terabyte-sized, publicly available, and multi-modal dataset specifically targeting climate change-aware crop yield predictions for the contiguous United States (U.S.) continent at the county level. Our CropNet dataset is composed of three modalities of data, i.e., Sentinel-2 Imagery, WRF-HRRR Computed Dataset, and USDA Crop Dataset, for over 2200 U.S. counties spanning 6 years (2017-2022), expected to facilitate researchers in developing versatile deep learning models for timely and precisely predicting crop yields at the county-level, by accounting for the effects of both short-term growing season weather variations and long-term climate change on crop yields. Besides, we develop the CropNet package, offering three types of APIs, for facilitating researchers in downloading the CropNet data on the fly over the time and region of interest, and flexibly building their deep learning models for accurate crop yield predictions. Extensive experiments have been conducted on our CropNet dataset via employing various types of deep learning solutions, with the results validating the general applicability and the efficacy of the CropNet dataset in climate change-aware crop yield predictions.
* 13 pages
FedClust: Optimizing Federated Learning on Non-IID Data through Weight-Driven Client Clustering
Mar 07, 2024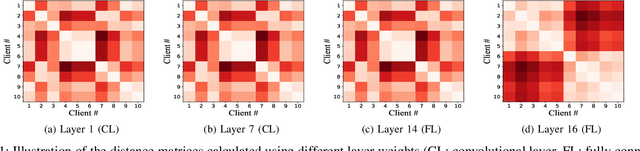
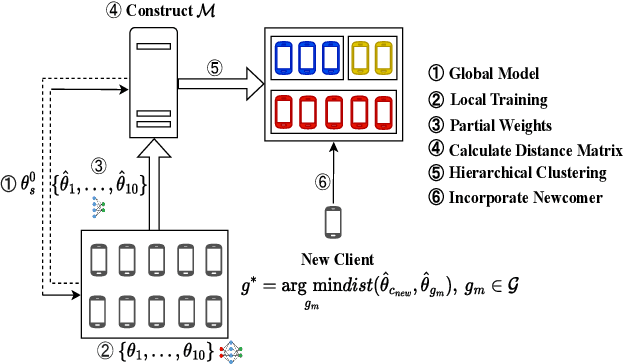
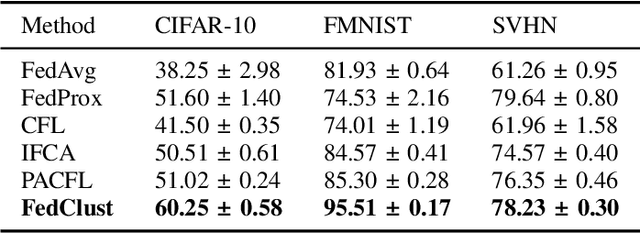
Federated learning (FL) is an emerging distributed machine learning paradigm enabling collaborative model training on decentralized devices without exposing their local data. A key challenge in FL is the uneven data distribution across client devices, violating the well-known assumption of independent-and-identically-distributed (IID) training samples in conventional machine learning. Clustered federated learning (CFL) addresses this challenge by grouping clients based on the similarity of their data distributions. However, existing CFL approaches require a large number of communication rounds for stable cluster formation and rely on a predefined number of clusters, thus limiting their flexibility and adaptability. This paper proposes FedClust, a novel CFL approach leveraging correlations between local model weights and client data distributions. FedClust groups clients into clusters in a one-shot manner using strategically selected partial model weights and dynamically accommodates newcomers in real-time. Experimental results demonstrate FedClust outperforms baseline approaches in terms of accuracy and communication costs.
MMST-ViT: Climate Change-aware Crop Yield Prediction via Multi-Modal Spatial-Temporal Vision Transformer
Sep 19, 2023



Precise crop yield prediction provides valuable information for agricultural planning and decision-making processes. However, timely predicting crop yields remains challenging as crop growth is sensitive to growing season weather variation and climate change. In this work, we develop a deep learning-based solution, namely Multi-Modal Spatial-Temporal Vision Transformer (MMST-ViT), for predicting crop yields at the county level across the United States, by considering the effects of short-term meteorological variations during the growing season and the long-term climate change on crops. Specifically, our MMST-ViT consists of a Multi-Modal Transformer, a Spatial Transformer, and a Temporal Transformer. The Multi-Modal Transformer leverages both visual remote sensing data and short-term meteorological data for modeling the effect of growing season weather variations on crop growth. The Spatial Transformer learns the high-resolution spatial dependency among counties for accurate agricultural tracking. The Temporal Transformer captures the long-range temporal dependency for learning the impact of long-term climate change on crops. Meanwhile, we also devise a novel multi-modal contrastive learning technique to pre-train our model without extensive human supervision. Hence, our MMST-ViT captures the impacts of both short-term weather variations and long-term climate change on crops by leveraging both satellite images and meteorological data. We have conducted extensive experiments on over 200 counties in the United States, with the experimental results exhibiting that our MMST-ViT outperforms its counterparts under three performance metrics of interest.