 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncentive-Compatible Federated Learning with Stackelberg Game Modeling
Jan 05, 2025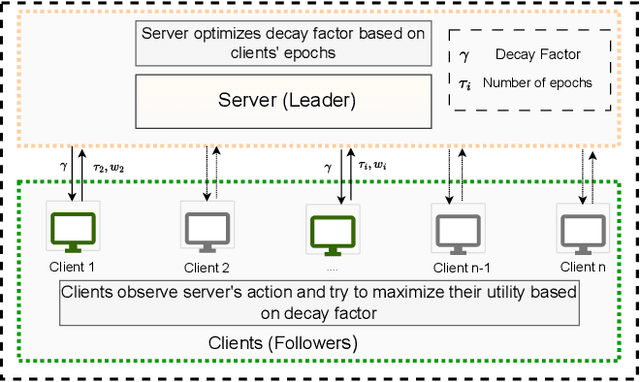

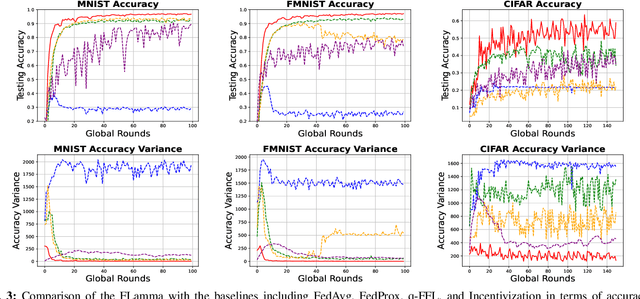
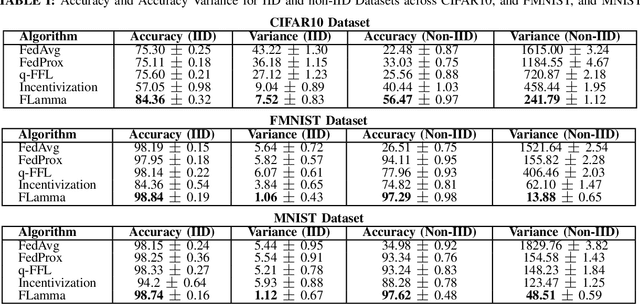
Federated Learning (FL) has gained prominence as a decentralized machine learning paradigm, allowing clients to collaboratively train a global model while preserving data privacy. Despite its potential, FL faces significant challenges in heterogeneous environments, where varying client resources and capabilities can undermine overall system performance. Existing approaches primarily focus on maximizing global model accuracy, often at the expense of unfairness among clients and suboptimal system efficiency, particularly in non-IID (non-Independent and Identically Distributed) settings. In this paper, we introduce FLamma, a novel Federated Learning framework based on adaptive gamma-based Stackelberg game, designed to address the aforementioned limitations and promote fairness. Our approach allows the server to act as the leader, dynamically adjusting a decay factor while clients, acting as followers, optimally select their number of local epochs to maximize their utility. Over time, the server incrementally balances client influence, initially rewarding higher-contributing clients and gradually leveling their impact, driving the system toward a Stackelberg Equilibrium. Extensive simulations on both IID and non-IID datasets show that our method significantly improves fairness in accuracy distribution without compromising overall model performance or convergence speed, outperforming traditional FL baselines.
FedClust: Tackling Data Heterogeneity in Federated Learning through Weight-Driven Client Clustering
Jul 09, 2024Federated learning (FL) is an emerging distributed machine learning paradigm that enables collaborative training of machine learning models over decentralized devices without exposing their local data. One of the major challenges in FL is the presence of uneven data distributions across client devices, violating the well-known assumption of independent-and-identically-distributed (IID) training samples in conventional machine learning. To address the performance degradation issue incurred by such data heterogeneity, clustered federated learning (CFL) shows its promise by grouping clients into separate learning clusters based on the similarity of their local data distributions. However, state-of-the-art CFL approaches require a large number of communication rounds to learn the distribution similarities during training until the formation of clusters is stabilized. Moreover, some of these algorithms heavily rely on a predefined number of clusters, thus limiting their flexibility and adaptability. In this paper, we propose {\em FedClust}, a novel approach for CFL that leverages the correlation between local model weights and the data distribution of clients. {\em FedClust} groups clients into clusters in a one-shot manner by measuring the similarity degrees among clients based on the strategically selected partial weights of locally trained models. We conduct extensive experiments on four benchmark datasets with different non-IID data settings. Experimental results demonstrate that {\em FedClust} achieves higher model accuracy up to $\sim$45\% as well as faster convergence with a significantly reduced communication cost up to 2.7$\times$ compared to its state-of-the-art counterparts.
FedClust: Optimizing Federated Learning on Non-IID Data through Weight-Driven Client Clustering
Mar 07, 2024
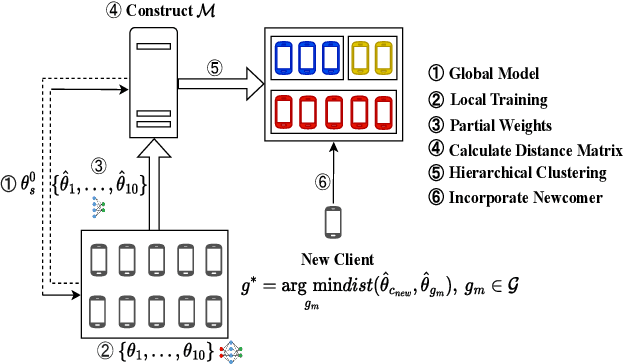
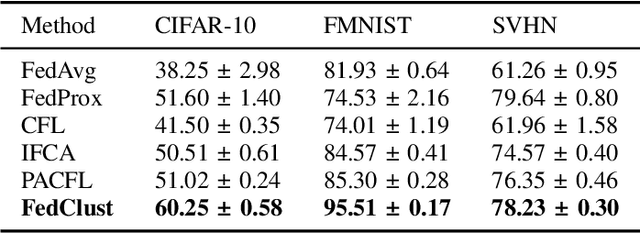
Federated learning (FL) is an emerging distributed machine learning paradigm enabling collaborative model training on decentralized devices without exposing their local data. A key challenge in FL is the uneven data distribution across client devices, violating the well-known assumption of independent-and-identically-distributed (IID) training samples in conventional machine learning. Clustered federated learning (CFL) addresses this challenge by grouping clients based on the similarity of their data distributions. However, existing CFL approaches require a large number of communication rounds for stable cluster formation and rely on a predefined number of clusters, thus limiting their flexibility and adaptability. This paper proposes FedClust, a novel CFL approach leveraging correlations between local model weights and client data distributions. FedClust groups clients into clusters in a one-shot manner using strategically selected partial model weights and dynamically accommodates newcomers in real-time. Experimental results demonstrate FedClust outperforms baseline approaches in terms of accuracy and communication costs.
FedFair^3: Unlocking Threefold Fairness in Federated Learning
Jan 29, 2024



Federated Learning (FL) is an emerging paradigm in machine learning without exposing clients' raw data. In practical scenarios with numerous clients, encouraging fair and efficient client participation in federated learning is of utmost importance, which is also challenging given the heterogeneity in data distribution and device properties. Existing works have proposed different client-selection methods that consider fairness; however, they fail to select clients with high utilities while simultaneously achieving fair accuracy levels. In this paper, we propose a fair client-selection approach that unlocks threefold fairness in federated learning. In addition to having a fair client-selection strategy, we enforce an equitable number of rounds for client participation and ensure a fair accuracy distribution over the clients. The experimental results demonstrate that FedFair^3, in comparison to the state-of-the-art baselines, achieves 18.15% less accuracy variance on the IID data and 54.78% on the non-IID data, without decreasing the global accuracy. Furthermore, it shows 24.36% less wall-clock training time on average.