 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingingBot: An Avatar-Driven System for Robotic Face Singing Performance
Jan 05, 2026Equipping robotic faces with singing capabilities is crucial for empathetic Human-Robot Interaction. However, existing robotic face driving research primarily focuses on conversations or mimicking static expressions, struggling to meet the high demands for continuous emotional expression and coherence in singing. To address this, we propose a novel avatar-driven framework for appealing robotic singing. We first leverage portrait video generation models embedded with extensive human priors to synthesize vivid singing avatars, providing reliable expression and emotion guidance. Subsequently, these facial features are transferred to the robot via semantic-oriented mapping functions that span a wide expression space. Furthermore, to quantitatively evaluate the emotional richness of robotic singing, we propose the Emotion Dynamic Range metric to measure the emotional breadth within the Valence-Arousal space, revealing that a broad emotional spectrum is crucial for appealing performances. Comprehensive experiments prove that our method achieves rich emotional expressions while maintaining lip-audio synchronization, significantly outperforming existing approaches.
Perceiving and Acting in First-Person: A Dataset and Benchmark for Egocentric Human-Object-Human Interactions
Aug 06, 2025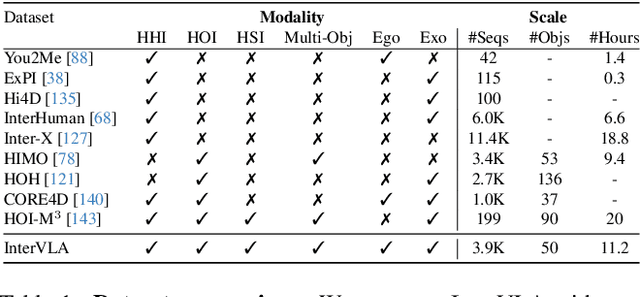

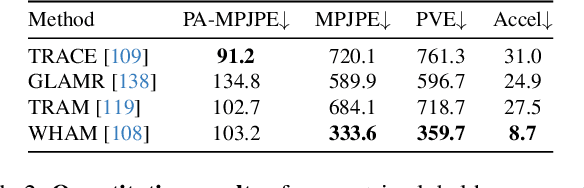

Learning action models from real-world human-centric interaction datasets is important towards building general-purpose intelligent assistants with efficiency. However, most existing datasets only offer specialist interaction category and ignore that AI assistants perceive and act based on first-person acquisition. We urge that both the generalist interaction knowledge and egocentric modality are indispensable. In this paper, we embed the manual-assisted task into a vision-language-action framework, where the assistant provides services to the instructor following egocentric vision and commands. With our hybrid RGB-MoCap system, pairs of assistants and instructors engage with multiple objects and the scene following GPT-generated scripts. Under this setting, we accomplish InterVLA, the first large-scale human-object-human interaction dataset with 11.4 hours and 1.2M frames of multimodal data, spanning 2 egocentric and 5 exocentric videos, accurate human/object motions and verbal commands. Furthermore, we establish novel benchmarks on egocentric human motion estimation, interaction synthesis, and interaction prediction with comprehensive analysis. We believe that our InterVLA testbed and the benchmarks will foster future works on building AI agents in the physical world.
Resource Heterogeneity-Aware and Utilization-Enhanced Scheduling for Deep Learning Clusters
Mar 13, 2025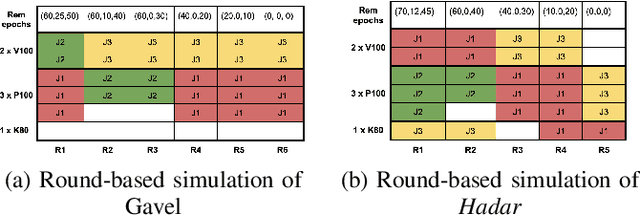
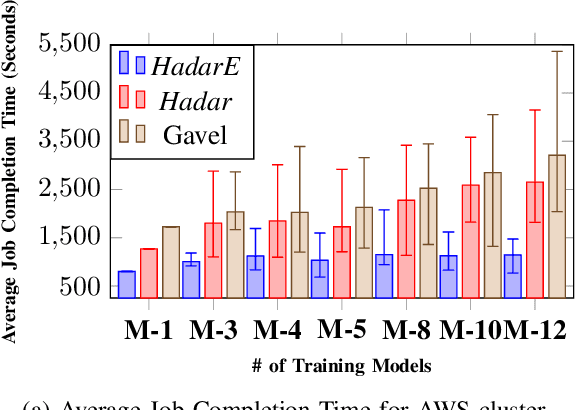
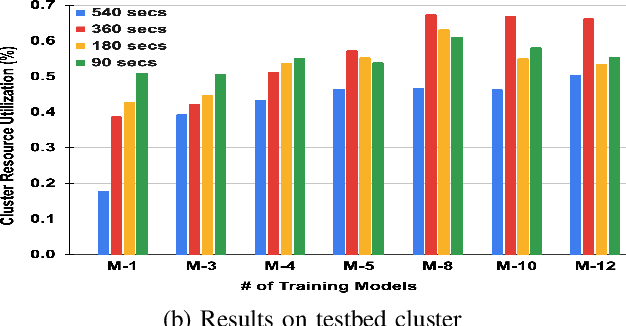
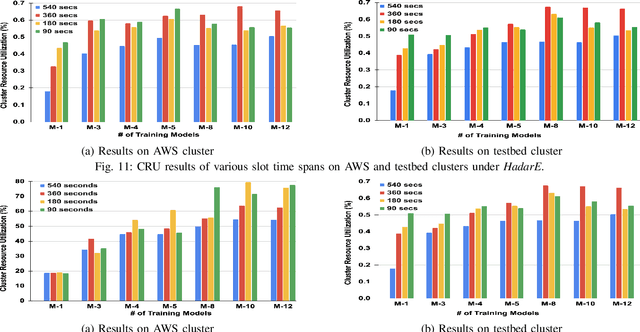
Scheduling deep learning (DL) models to train on powerful clusters with accelerators like GPUs and TPUs, presently falls short, either lacking fine-grained heterogeneity awareness or leaving resources substantially under-utilized. To fill this gap, we propose a novel design of a task-level heterogeneity-aware scheduler, {\em Hadar}, based on an optimization framework that can boost resource utilization. {\em Hadar} leverages the performance traits of DL jobs on a heterogeneous DL cluster, characterizes the task-level performance heterogeneity in the optimization problem, and makes scheduling decisions across both spatial and temporal dimensions. %with the objective to reduce the average job completion time of DL jobs. It involves the primal-dual framework employing a dual subroutine, to solve the optimization problem and guide the scheduling design. Our trace-driven simulation with representative DL model training workloads demonstrates that {\em Hadar} accelerates the total time duration by 1.20$\times$ when compared with its state-of-the-art heterogeneity-aware counterpart, Gavel. Further, our {\em Hadar} scheduler is enhanced to {\em HadarE} by forking each job into multiple copies to let a job train concurrently on heterogeneous GPUs resided on separate available nodes (i.e., machines or servers) for resource utilization enhancement. {\em HadarE} is evaluated extensively on physical DL clusters for comparison with {\em Hadar} and Gavel. With substantial enhancement in cluster resource utilization (by 1.45$\times$), {\em HadarE} exhibits considerable speed-ups in DL model training, reducing the total time duration by 50\% (or 80\%) on an Amazon's AWS (or our lab) cluster, while producing trained DL models with consistently better inference quality than those trained by \textit{Hadar}.
Guided and Variance-Corrected Fusion with One-shot Style Alignment for Large-Content Image Generation
Dec 17, 2024



Producing large images using small diffusion models is gaining increasing popularity, as the cost of training large models could be prohibitive. A common approach involves jointly generating a series of overlapped image patches and obtaining large images by merging adjacent patches. However, results from existing methods often exhibit obvious artifacts, e.g., seams and inconsistent objects and styles. To address the issues, we proposed Guided Fusion (GF), which mitigates the negative impact from distant image regions by applying a weighted average to the overlapping regions. Moreover, we proposed Variance-Corrected Fusion (VCF), which corrects data variance at post-averaging, generating more accurate fusion for the Denoising Diffusion Probabilistic Model. Furthermore, we proposed a one-shot Style Alignment (SA), which generates a coherent style for large images by adjusting the initial input noise without adding extra computational burden. Extensive experiments demonstrated that the proposed fusion methods improved the quality of the generated image significantly. As a plug-and-play module, the proposed method can be widely applied to enhance other fusion-based methods for large image generation.
Cross-Attention Based Influence Model for Manual and Nonmanual Sign Language Analysis
Sep 12, 2024Both manual (relating to the use of hands) and non-manual markers (NMM), such as facial expressions or mouthing cues, are important for providing the complete meaning of phrases in American Sign Language (ASL). Efforts have been made in advancing sign language to spoken/written language understanding, but most of these have primarily focused on manual features only. In this work, using advanced neural machine translation methods, we examine and report on the extent to which facial expressions contribute to understanding sign language phrases. We present a sign language translation architecture consisting of two-stream encoders, with one encoder handling the face and the other handling the upper body (with hands). We propose a new parallel cross-attention decoding mechanism that is useful for quantifying the influence of each input modality on the output. The two streams from the encoder are directed simultaneously to different attention stacks in the decoder. Examining the properties of the parallel cross-attention weights allows us to analyze the importance of facial markers compared to body and hand features during a translating task.
FedClust: Tackling Data Heterogeneity in Federated Learning through Weight-Driven Client Clustering
Jul 09, 2024Federated learning (FL) is an emerging distributed machine learning paradigm that enables collaborative training of machine learning models over decentralized devices without exposing their local data. One of the major challenges in FL is the presence of uneven data distributions across client devices, violating the well-known assumption of independent-and-identically-distributed (IID) training samples in conventional machine learning. To address the performance degradation issue incurred by such data heterogeneity, clustered federated learning (CFL) shows its promise by grouping clients into separate learning clusters based on the similarity of their local data distributions. However, state-of-the-art CFL approaches require a large number of communication rounds to learn the distribution similarities during training until the formation of clusters is stabilized. Moreover, some of these algorithms heavily rely on a predefined number of clusters, thus limiting their flexibility and adaptability. In this paper, we propose {\em FedClust}, a novel approach for CFL that leverages the correlation between local model weights and the data distribution of clients. {\em FedClust} groups clients into clusters in a one-shot manner by measuring the similarity degrees among clients based on the strategically selected partial weights of locally trained models. We conduct extensive experiments on four benchmark datasets with different non-IID data settings. Experimental results demonstrate that {\em FedClust} achieves higher model accuracy up to $\sim$45\% as well as faster convergence with a significantly reduced communication cost up to 2.7$\times$ compared to its state-of-the-art counterparts.
SignAvatar: Sign Language 3D Motion Reconstruction and Generation
May 13, 2024Achieving expressive 3D motion reconstruction and automatic generation for isolated sign words can be challenging, due to the lack of real-world 3D sign-word data, the complex nuances of signing motions, and the cross-modal understanding of sign language semantics. To address these challenges, we introduce SignAvatar, a framework capable of both word-level sign language reconstruction and generation. SignAvatar employs a transformer-based conditional variational autoencoder architecture, effectively establishing relationships across different semantic modalities. Additionally, this approach incorporates a curriculum learning strategy to enhance the model's robustness and generalization, resulting in more realistic motions. Furthermore, we contribute the ASL3DWord dataset, composed of 3D joint rotation data for the body, hands, and face, for unique sign words. We demonstrate the effectiveness of SignAvatar through extensive experiments, showcasing its superior reconstruction and automatic generation capabilities. The code and dataset are available on the project page.
Causality Extraction from Nuclear Licensee Event Reports Using a Hybrid Framework
Apr 08, 2024Industry-wide nuclear power plant operating experience is a critical source of raw data for performing parameter estimations in reliability and risk models. Much operating experience information pertains to failure events and is stored as reports containing unstructured data, such as narratives. Event reports are essential for understanding how failures are initiated and propagated, including the numerous causal relations involved. Causal relation extraction using deep learning represents a significant frontier in the field of natural language processing (NLP), and is crucial since it enables the interpretation of intricate narratives and connections contained within vast amounts of written information. This paper proposed a hybrid framework for causality detection and extraction from nuclear licensee event reports. The main contributions include: (1) we compiled an LER corpus with 20,129 text samples for causality analysis, (2) developed an interactive tool for labeling cause effect pairs, (3) built a deep-learning-based approach for causal relation detection, and (4) developed a knowledge based cause-effect extraction approach.
iSeg: Interactive 3D Segmentation via Interactive Attention
Apr 04, 2024We present iSeg, a new interactive technique for segmenting 3D shapes. Previous works have focused mainly on leveraging pre-trained 2D foundation models for 3D segmentation based on text. However, text may be insufficient for accurately describing fine-grained spatial segmentations. Moreover, achieving a consistent 3D segmentation using a 2D model is challenging since occluded areas of the same semantic region may not be visible together from any 2D view. Thus, we design a segmentation method conditioned on fine user clicks, which operates entirely in 3D. Our system accepts user clicks directly on the shape's surface, indicating the inclusion or exclusion of regions from the desired shape partition. To accommodate various click settings, we propose a novel interactive attention module capable of processing different numbers and types of clicks, enabling the training of a single unified interactive segmentation model. We apply iSeg to a myriad of shapes from different domains, demonstrating its versatility and faithfulness to the user's specifications. Our project page is at https://threedle.github.io/iSeg/.
FedClust: Optimizing Federated Learning on Non-IID Data through Weight-Driven Client Clustering
Mar 07, 2024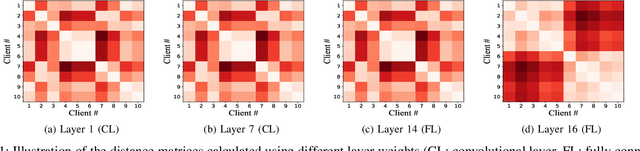
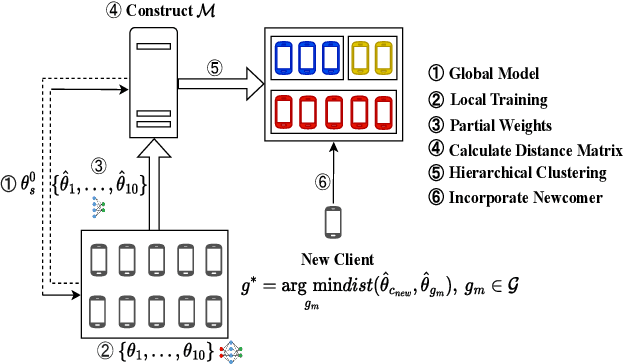
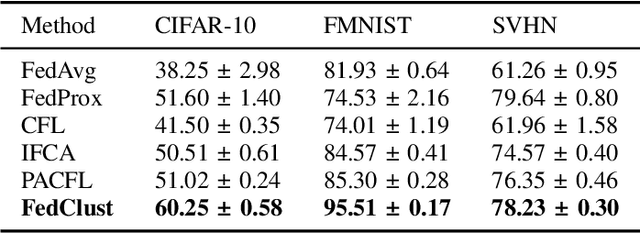
Federated learning (FL) is an emerging distributed machine learning paradigm enabling collaborative model training on decentralized devices without exposing their local data. A key challenge in FL is the uneven data distribution across client devices, violating the well-known assumption of independent-and-identically-distributed (IID) training samples in conventional machine learning. Clustered federated learning (CFL) addresses this challenge by grouping clients based on the similarity of their data distributions. However, existing CFL approaches require a large number of communication rounds for stable cluster formation and rely on a predefined number of clusters, thus limiting their flexibility and adaptability. This paper proposes FedClust, a novel CFL approach leveraging correlations between local model weights and client data distributions. FedClust groups clients into clusters in a one-shot manner using strategically selected partial model weights and dynamically accommodates newcomers in real-time. Experimental results demonstrate FedClust outperforms baseline approaches in terms of accuracy and communication costs.