 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpara: Exploiting Operator Parallelism for Expediting DNN Inference on GPUs
Dec 16, 2023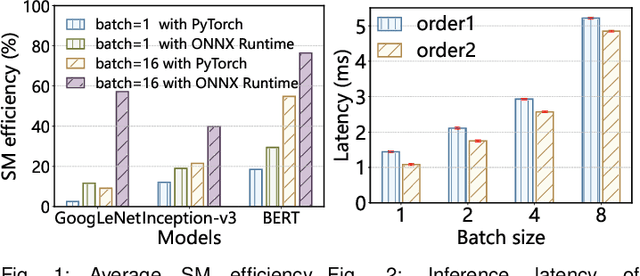


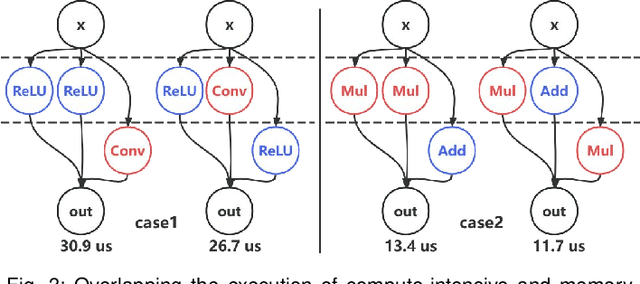
GPUs have become the defacto hardware devices to accelerate Deep Neural Network (DNN) inference in deep learning(DL) frameworks. However, the conventional sequential execution mode of DNN operators in mainstream DL frameworks cannot fully utilize GPU resources, due to the increasing complexity of DNN model structures and the progressively smaller computational sizes of DNN operators. Moreover, the inadequate operator launch order in parallelized execution scenarios can lead to GPU resource wastage and unexpected performance interference among operators. To address such performance issues above, we propose Opara, a resource- and interference-aware DNN Operator parallel scheduling framework to accelerate the execution of DNN inference on GPUs. Specifically, Opara first employs CUDA Streams and CUDA Graph to automatically parallelize the execution of multiple DNN operators. It further leverages the resource demands of DNN operators to judiciously adjust the operator launch order on GPUs by overlapping the execution of compute-intensive and memory-intensive operators, so as to expedite DNN inference. We implement and open source a prototype of Opara based on PyTorch in a non-intrusive manner. Extensive prototype experiments with representative DNN and Transformer-based models demonstrate that Opara outperforms the default sequential CUDA Graph in PyTorch and the state-of-the-art DNN operator parallelism systems by up to 1.68$\times$ and 1.29$\times$, respectively, yet with acceptable runtime overhead.