 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
Opara: Exploiting Operator Parallelism for Expediting DNN Inference on GPUs
Dec 16, 2023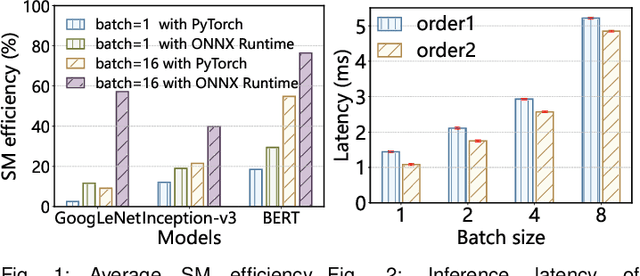


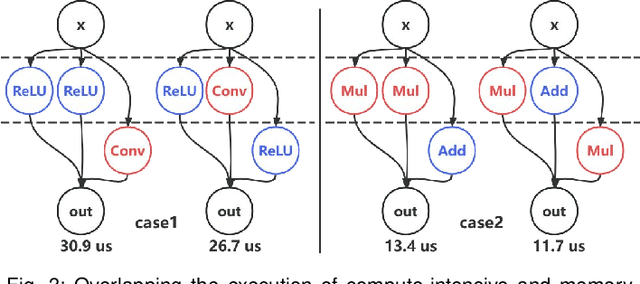
GPUs have become the defacto hardware devices to accelerate Deep Neural Network (DNN) inference in deep learning(DL) frameworks. However, the conventional sequential execution mode of DNN operators in mainstream DL frameworks cannot fully utilize GPU resources, due to the increasing complexity of DNN model structures and the progressively smaller computational sizes of DNN operators. Moreover, the inadequate operator launch order in parallelized execution scenarios can lead to GPU resource wastage and unexpected performance interference among operators. To address such performance issues above, we propose Opara, a resource- and interference-aware DNN Operator parallel scheduling framework to accelerate the execution of DNN inference on GPUs. Specifically, Opara first employs CUDA Streams and CUDA Graph to automatically parallelize the execution of multiple DNN operators. It further leverages the resource demands of DNN operators to judiciously adjust the operator launch order on GPUs by overlapping the execution of compute-intensive and memory-intensive operators, so as to expedite DNN inference. We implement and open source a prototype of Opara based on PyTorch in a non-intrusive manner. Extensive prototype experiments with representative DNN and Transformer-based models demonstrate that Opara outperforms the default sequential CUDA Graph in PyTorch and the state-of-the-art DNN operator parallelism systems by up to 1.68$\times$ and 1.29$\times$, respectively, yet with acceptable runtime overhead.
Learning on Abstract Domains: A New Approach for Verifiable Guarantee in Reinforcement Learning
Jun 13, 2021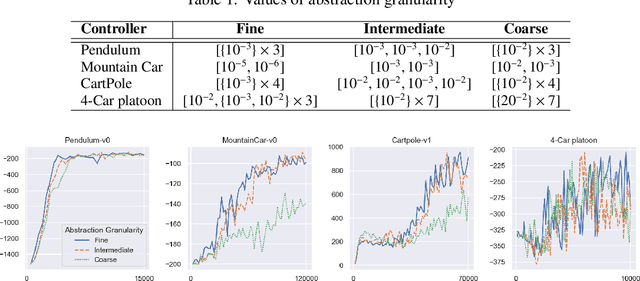
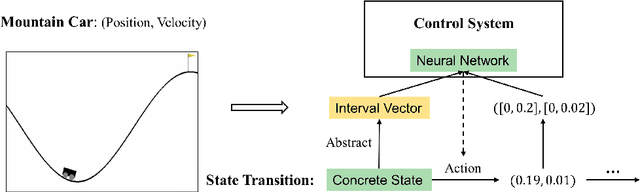
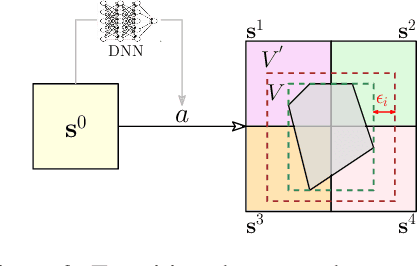
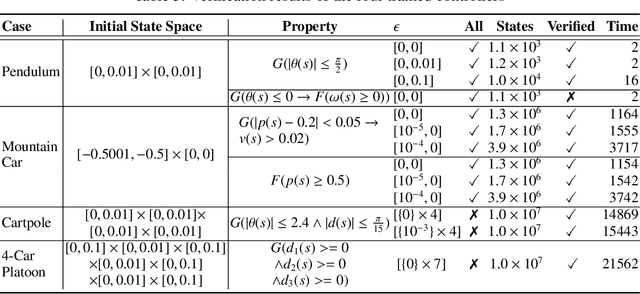
Formally verifying Deep Reinforcement Learning (DRL) systems is a challenging task due to the dynamic continuity of system behaviors and the black-box feature of embedded neural networks. In this paper, we propose a novel abstraction-based approach to train DRL systems on finite abstract domains instead of concrete system states. It yields neural networks whose input states are finite, making hosting DRL systems directly verifiable using model checking techniques. Our approach is orthogonal to existing DRL algorithms and off-the-shelf model checkers. We implement a resulting prototype training and verification framework and conduct extensive experiments on the state-of-the-art benchmark. The results show that the systems trained in our approach can be verified more efficiently while they retain comparable performance against those that are trained without abstraction.