 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified View of Attention and Residual Sinks: Outlier-Driven Rescaling is Essential for Transformer Training
Jan 30, 2026We investigate the functional role of emergent outliers in large language models, specifically attention sinks (a few tokens that consistently receive large attention logits) and residual sinks (a few fixed dimensions with persistently large activations across most tokens). We hypothesize that these outliers, in conjunction with the corresponding normalizations (\textit{e.g.}, softmax attention and RMSNorm), effectively rescale other non-outlier components. We term this phenomenon \textit{outlier-driven rescaling} and validate this hypothesis across different model architectures and training token counts. This view unifies the origin and mitigation of both sink types. Our main conclusions and observations include: (1) Outliers function jointly with normalization: removing normalization eliminates the corresponding outliers but degrades training stability and performance; directly clipping outliers while retaining normalization leads to degradation, indicating that outlier-driven rescaling contributes to training stability. (2) Outliers serve more as rescale factors rather than contributors, as the final contributions of attention and residual sinks are significantly smaller than those of non-outliers. (3) Outliers can be absorbed into learnable parameters or mitigated via explicit gated rescaling, leading to improved training performance (average gain of 2 points) and enhanced quantization robustness (1.2 points degradation under W4A4 quantization).
Dual-view Spatio-Temporal Feature Fusion with CNN-Transformer Hybrid Network for Chinese Isolated Sign Language Recognition
Jun 08, 2025Due to the emergence of many sign language datasets, isolated sign language recognition (ISLR) has made significant progress in recent years. In addition, the development of various advanced deep neural networks is another reason for this breakthrough. However, challenges remain in applying the technique in the real world. First, existing sign language datasets do not cover the whole sign vocabulary. Second, most of the sign language datasets provide only single view RGB videos, which makes it difficult to handle hand occlusions when performing ISLR. To fill this gap, this paper presents a dual-view sign language dataset for ISLR named NationalCSL-DP, which fully covers the Chinese national sign language vocabulary. The dataset consists of 134140 sign videos recorded by ten signers with respect to two vertical views, namely, the front side and the left side. Furthermore, a CNN transformer network is also proposed as a strong baseline and an extremely simple but effective fusion strategy for prediction. Extensive experiments were conducted to prove the effectiveness of the datasets as well as the baseline. The results show that the proposed fusion strategy can significantly increase the performance of the ISLR, but it is not easy for the sequence-to-sequence model, regardless of whether the early-fusion or late-fusion strategy is applied, to learn the complementary features from the sign videos of two vertical views.
OpenPros: A Large-Scale Dataset for Limited View Prostate Ultrasound Computed Tomography
May 18, 2025Prostate cancer is one of the most common and lethal cancers among men, making its early detection critically important. Although ultrasound imaging offers greater accessibility and cost-effectiveness compared to MRI, traditional transrectal ultrasound methods suffer from low sensitivity, especially in detecting anteriorly located tumors. Ultrasound computed tomography provides quantitative tissue characterization, but its clinical implementation faces significant challenges, particularly under anatomically constrained limited-angle acquisition conditions specific to prostate imaging. To address these unmet needs, we introduce OpenPros, the first large-scale benchmark dataset explicitly developed for limited-view prostate USCT. Our dataset includes over 280,000 paired samples of realistic 2D speed-of-sound (SOS) phantoms and corresponding ultrasound full-waveform data, generated from anatomically accurate 3D digital prostate models derived from real clinical MRI/CT scans and ex vivo ultrasound measurements, annotated by medical experts. Simulations are conducted under clinically realistic configurations using advanced finite-difference time-domain and Runge-Kutta acoustic wave solvers, both provided as open-source components. Through comprehensive baseline experiments, we demonstrate that state-of-the-art deep learning methods surpass traditional physics-based approaches in both inference efficiency and reconstruction accuracy. Nevertheless, current deep learning models still fall short of delivering clinically acceptable high-resolution images with sufficient accuracy. By publicly releasing OpenPros, we aim to encourage the development of advanced machine learning algorithms capable of bridging this performance gap and producing clinically usable, high-resolution, and highly accurate prostate ultrasound images. The dataset is publicly accessible at https://open-pros.github.io/.
Uni-AIMS: AI-Powered Microscopy Image Analysis
May 11, 2025This paper presents a systematic solution for the intelligent recognition and automatic analysis of microscopy images. We developed a data engine that generates high-quality annotated datasets through a combination of the collection of diverse microscopy images from experiments, synthetic data generation and a human-in-the-loop annotation process. To address the unique challenges of microscopy images, we propose a segmentation model capable of robustly detecting both small and large objects. The model effectively identifies and separates thousands of closely situated targets, even in cluttered visual environments. Furthermore, our solution supports the precise automatic recognition of image scale bars, an essential feature in quantitative microscopic analysis. Building upon these components, we have constructed a comprehensive intelligent analysis platform and validated its effectiveness and practicality in real-world applications. This study not only advances automatic recognition in microscopy imaging but also ensures scalability and generalizability across multiple application domains, offering a powerful tool for automated microscopic analysis in interdisciplinary research.
MagicComp: Training-free Dual-Phase Refinement for Compositional Video Generation
Mar 18, 2025Text-to-video (T2V) generation has made significant strides with diffusion models. However, existing methods still struggle with accurately binding attributes, determining spatial relationships, and capturing complex action interactions between multiple subjects. To address these limitations, we propose MagicComp, a training-free method that enhances compositional T2V generation through dual-phase refinement. Specifically, (1) During the Conditioning Stage: We introduce the Semantic Anchor Disambiguation to reinforces subject-specific semantics and resolve inter-subject ambiguity by progressively injecting the directional vectors of semantic anchors into original text embedding; (2) During the Denoising Stage: We propose Dynamic Layout Fusion Attention, which integrates grounding priors and model-adaptive spatial perception to flexibly bind subjects to their spatiotemporal regions through masked attention modulation. Furthermore, MagicComp is a model-agnostic and versatile approach, which can be seamlessly integrated into existing T2V architectures. Extensive experiments on T2V-CompBench and VBench demonstrate that MagicComp outperforms state-of-the-art methods, highlighting its potential for applications such as complex prompt-based and trajectory-controllable video generation. Project page: https://hong-yu-zhang.github.io/MagicComp-Page/.
WISE: A World Knowledge-Informed Semantic Evaluation for Text-to-Image Generation
Mar 10, 2025Text-to-Image (T2I) models are capable of generating high-quality artistic creations and visual content. However, existing research and evaluation standards predominantly focus on image realism and shallow text-image alignment, lacking a comprehensive assessment of complex semantic understanding and world knowledge integration in text to image generation. To address this challenge, we propose $\textbf{WISE}$, the first benchmark specifically designed for $\textbf{W}$orld Knowledge-$\textbf{I}$nformed $\textbf{S}$emantic $\textbf{E}$valuation. WISE moves beyond simple word-pixel mapping by challenging models with 1000 meticulously crafted prompts across 25 sub-domains in cultural common sense, spatio-temporal reasoning, and natural science. To overcome the limitations of traditional CLIP metric, we introduce $\textbf{WiScore}$, a novel quantitative metric for assessing knowledge-image alignment. Through comprehensive testing of 20 models (10 dedicated T2I models and 10 unified multimodal models) using 1,000 structured prompts spanning 25 subdomains, our findings reveal significant limitations in their ability to effectively integrate and apply world knowledge during image generation, highlighting critical pathways for enhancing knowledge incorporation and application in next-generation T2I models. Code and data are available at https://github.com/PKU-YuanGroup/WISE.
Hierarchical Banzhaf Interaction for General Video-Language Representation Learning
Dec 30, 2024



Multimodal representation learning, with contrastive learning, plays an important role in the artificial intelligence domain. As an important subfield, video-language representation learning focuses on learning representations using global semantic interactions between pre-defined video-text pairs. However, to enhance and refine such coarse-grained global interactions, more detailed interactions are necessary for fine-grained multimodal learning. In this study, we introduce a new approach that models video-text as game players using multivariate cooperative game theory to handle uncertainty during fine-grained semantic interactions with diverse granularity, flexible combination, and vague intensity. Specifically, we design the Hierarchical Banzhaf Interaction to simulate the fine-grained correspondence between video clips and textual words from hierarchical perspectives. Furthermore, to mitigate the bias in calculations within Banzhaf Interaction, we propose reconstructing the representation through a fusion of single-modal and cross-modal components. This reconstructed representation ensures fine granularity comparable to that of the single-modal representation, while also preserving the adaptive encoding characteristics of cross-modal representation. Additionally, we extend our original structure into a flexible encoder-decoder framework, enabling the model to adapt to various downstream tasks. Extensive experiments on commonly used text-video retrieval, video-question answering, and video captioning benchmarks, with superior performance, validate the effectiveness and generalization of our method.
Next Patch Prediction for Autoregressive Visual Generation
Dec 19, 2024Autoregressive models, built based on the Next Token Prediction (NTP) paradigm, show great potential in developing a unified framework that integrates both language and vision tasks. In this work, we rethink the NTP for autoregressive image generation and propose a novel Next Patch Prediction (NPP) paradigm. Our key idea is to group and aggregate image tokens into patch tokens containing high information density. With patch tokens as a shorter input sequence, the autoregressive model is trained to predict the next patch, thereby significantly reducing the computational cost. We further propose a multi-scale coarse-to-fine patch grouping strategy that exploits the natural hierarchical property of image data. Experiments on a diverse range of models (100M-1.4B parameters) demonstrate that the next patch prediction paradigm could reduce the training cost to around 0.6 times while improving image generation quality by up to 1.0 FID score on the ImageNet benchmark. We highlight that our method retains the original autoregressive model architecture without introducing additional trainable parameters or specifically designing a custom image tokenizer, thus ensuring flexibility and seamless adaptation to various autoregressive models for visual generation.
LLaVA-CoT: Let Vision Language Models Reason Step-by-Step
Nov 25, 2024



Large language models have demonstrated substantial advancements in reasoning capabilities, particularly through inference-time scaling, as illustrated by models such as OpenAI's o1. However, current Vision-Language Models (VLMs) often struggle to perform systematic and structured reasoning, especially when handling complex visual question-answering tasks. In this work, we introduce LLaVA-CoT, a novel VLM designed to conduct autonomous multistage reasoning. Unlike chain-of-thought prompting, LLaVA-CoT independently engages in sequential stages of summarization, visual interpretation, logical reasoning, and conclusion generation. This structured approach enables LLaVA-CoT to achieve marked improvements in precision on reasoning-intensive tasks. To accomplish this, we compile the LLaVA-CoT-100k dataset, integrating samples from various visual question answering sources and providing structured reasoning annotations. Besides, we propose an inference-time stage-level beam search method, which enables effective inference-time scaling. Remarkably, with only 100k training samples and a simple yet effective inference time scaling method, LLaVA-CoT not only outperforms its base model by 8.9% on a wide range of multimodal reasoning benchmarks, but also surpasses the performance of larger and even closed-source models, such as Gemini-1.5-pro, GPT-4o-mini, and Llama-3.2-90B-Vision-Instruct.
Effort: Efficient Orthogonal Modeling for Generalizable AI-Generated Image Detection
Nov 23, 2024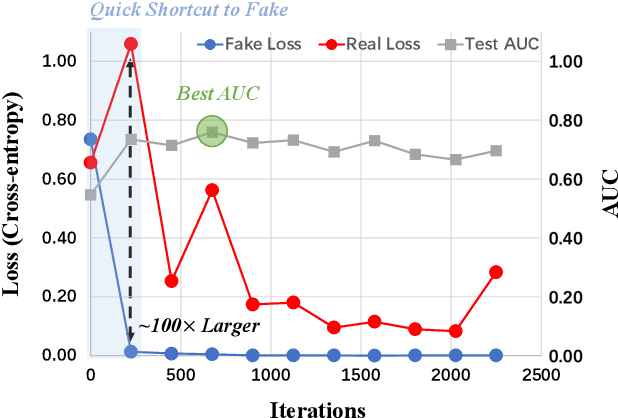
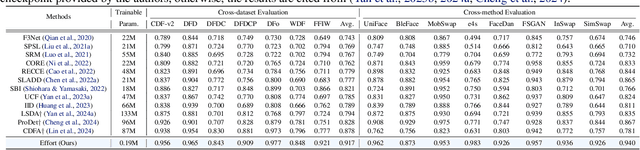
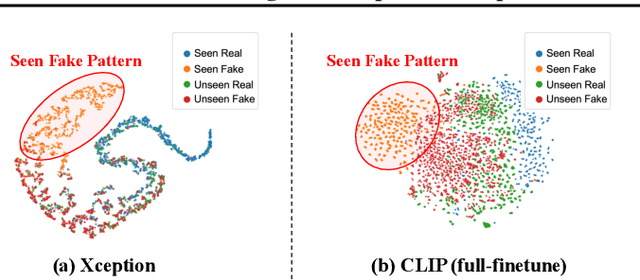
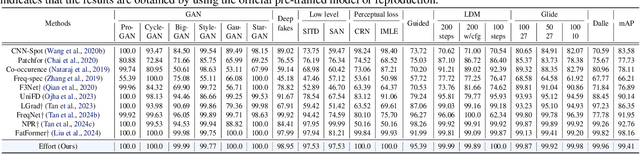
Existing AI-generated image (AIGI) detection methods often suffer from limited generalization performance. In this paper, we identify a crucial yet previously overlooked asymmetry phenomenon in AIGI detection: during training, models tend to quickly overfit to specific fake patterns in the training set, while other information is not adequately captured, leading to poor generalization when faced with new fake methods. A key insight is to incorporate the rich semantic knowledge embedded within large-scale vision foundation models (VFMs) to expand the previous discriminative space (based on forgery patterns only), such that the discrimination is decided by both forgery and semantic cues, thereby reducing the overfitting to specific forgery patterns. A straightforward solution is to fully fine-tune VFMs, but it risks distorting the well-learned semantic knowledge, pushing the model back toward overfitting. To this end, we design a novel approach called Effort: Efficient orthogonal modeling for generalizable AIGI detection. Specifically, we employ Singular Value Decomposition (SVD) to construct the orthogonal semantic and forgery subspaces. By freezing the principal components and adapting the residual components ($\sim$0.19M parameters), we preserve the original semantic subspace and use its orthogonal subspace for learning forgeries. Extensive experiments on AIGI detection benchmarks demonstrate the superior effectiveness of our approach.