 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrder from Chaos: Physical World Understanding from Glitchy Gameplay Videos
Jan 23, 2026Understanding the physical world, including object dynamics, material properties, and causal interactions, remains a core challenge in artificial intelligence. Although recent multi-modal large language models (MLLMs) have demonstrated impressive general reasoning capabilities, they still fall short of achieving human-level understanding of physical principles. Existing datasets for physical reasoning either rely on real-world videos, which incur high annotation costs, or on synthetic simulations, which suffer from limited realism and diversity. In this paper, we propose a novel paradigm that leverages glitches in gameplay videos, referring to visual anomalies that violate predefined physical laws, as a rich and scalable supervision source for physical world understanding. We introduce PhysGame, an meta information guided instruction-tuning dataset containing 140,057 glitch-centric question-answer pairs across five physical domains and sixteen fine-grained categories. To ensure data accuracy, we design a prompting strategy that utilizes gameplay metadata such as titles and descriptions to guide high-quality QA generation. Complementing PhysGame, we construct GameBench, an expert-annotated benchmark with 880 glitch-identified gameplay videos designed to evaluate physical reasoning capabilities. Extensive experiments show that PhysGame significantly enhances both Game2Real transferability, improving the real world physical reasoning performance of Qwen2.5VL by 2.5% on PhysBench, and Game2General transferability, yielding a 1.9% gain on the MVBench benchmark. Moreover, PhysGame-tuned models achieve a 3.7% absolute improvement on GameBench, demonstrating enhanced robustness in detecting physical implausibilities. These results indicate that learning from gameplay anomalies offers a scalable and effective pathway toward advancing physical world understanding in multimodal intelligence.
Video Spatial Reasoning with Object-Centric 3D Rollout
Nov 17, 2025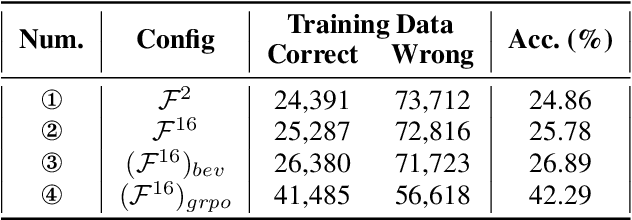
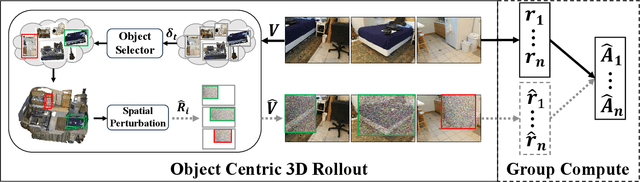
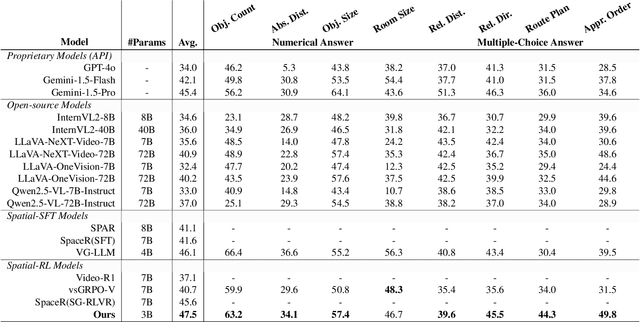
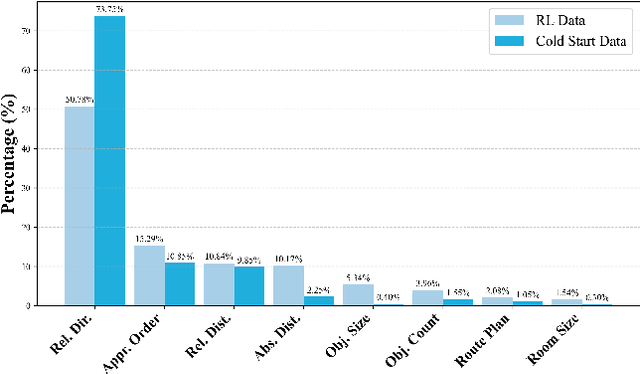
Recent advances in Multi-modal Large Language Models (MLLMs) have showcased remarkable capabilities in vision-language understanding. However, enabling robust video spatial reasoning-the ability to comprehend object locations, orientations, and inter-object relationships in dynamic 3D scenes-remains a key unsolved challenge. Existing approaches primarily rely on spatially grounded supervised fine-tuning or reinforcement learning, yet we observe that such models often exhibit query-locked reasoning, focusing narrowly on objects explicitly mentioned in the prompt while ignoring critical contextual cues. To address this limitation, we propose Object-Centric 3D Rollout (OCR), a novel strategy that introduces structured perturbations to the 3D geometry of selected objects during training. By degrading object-specific visual cues and projecting the altered geometry into 2D space, OCR compels the model to reason holistically across the entire scene. We further design a rollout-based training pipeline that jointly leverages vanilla and region-noisy videos to optimize spatial reasoning trajectories. Experiments demonstrate state-of-the-art performance: our 3B-parameter model achieves 47.5% accuracy on VSI-Bench, outperforming several 7B baselines. Ablations confirm OCR's superiority over prior rollout strategies (e.g., T-GRPO, NoisyRollout).
CoT-Vid: Dynamic Chain-of-Thought Routing with Self Verification for Training-Free Video Reasoning
May 17, 2025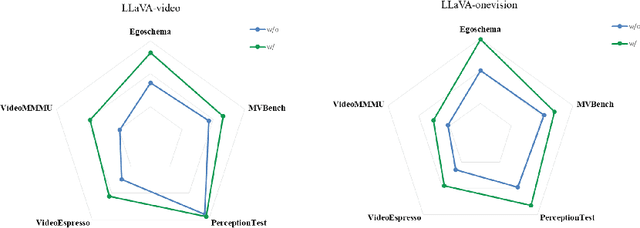
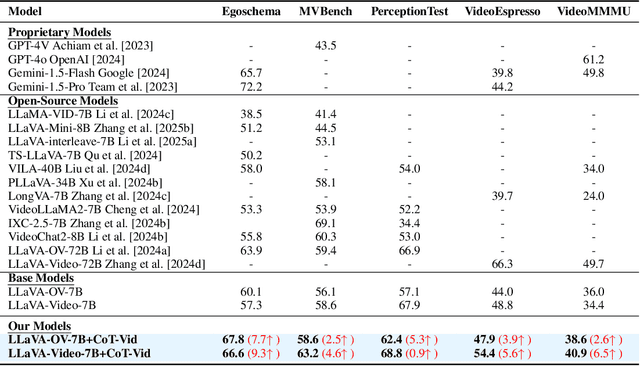
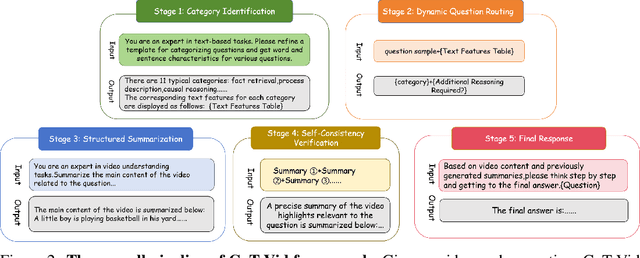

System2 reasoning is developing rapidly these days with the emergence of Deep- Thinking Models and chain-of-thought technology, which has become a centralized discussion point in the AI community. However, there is a relative gap in the research on complex video reasoning at present. In this work, we propose CoT-Vid, a novel training-free paradigm for the video domain with a multistage complex reasoning design. Distinguishing from existing video LLMs, which rely heavily on perceptual abilities, it achieved surprising performance gain with explicit reasoning mechanism. The paradigm consists of three main components: dynamic inference path routing, problem decoupling strategy, and video self-consistency verification. In addition, we propose a new standard for categorization of video questions. CoT- Vid showed outstanding results on a wide range of benchmarks, and outperforms its base model by 9.3% on Egochema and 5.6% on VideoEspresso, rivalling or even surpassing larger and proprietary models, such as GPT-4V, GPT-4o and Gemini-1.5-flash. Our codebase will be publicly available soon.
PhysGame: Uncovering Physical Commonsense Violations in Gameplay Videos
Dec 02, 2024



Recent advancements in video-based large language models (Video LLMs) have witnessed the emergence of diverse capabilities to reason and interpret dynamic visual content. Among them, gameplay videos stand out as a distinctive data source, often containing glitches that defy physics commonsense. This characteristic renders them an effective benchmark for assessing the under-explored capability of physical commonsense understanding in video LLMs. In this paper, we propose PhysGame as a pioneering benchmark to evaluate physical commonsense violations in gameplay videos. PhysGame comprises 880 videos associated with glitches spanning four fundamental domains (i.e., mechanics, kinematics, optics, and material properties) and across 12 distinct physical commonsense. Through extensively evaluating various state-ofthe-art video LLMs, our findings reveal that the performance of current open-source video LLMs significantly lags behind that of proprietary counterparts. To bridge this gap, we curate an instruction tuning dataset PhysInstruct with 140,057 question-answering pairs to facilitate physical commonsense learning. In addition, we also propose a preference optimization dataset PhysDPO with 34,358 training pairs, where the dis-preferred responses are generated conditioned on misleading titles (i.e., meta information hacking), fewer frames (i.e., temporal hacking) and lower spatial resolutions (i.e., spatial hacking). Based on the suite of datasets, we propose PhysVLM as a physical knowledge-enhanced video LLM. Extensive experiments on both physical-oriented benchmark PhysGame and general video understanding benchmarks demonstrate the state-ofthe-art performance of PhysVLM.
PPLLaVA: Varied Video Sequence Understanding With Prompt Guidance
Nov 05, 2024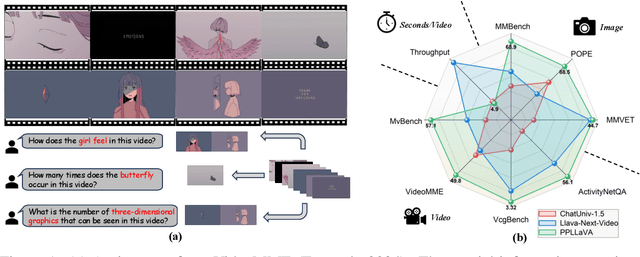
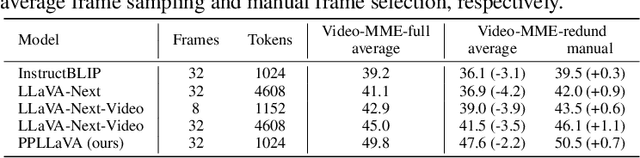
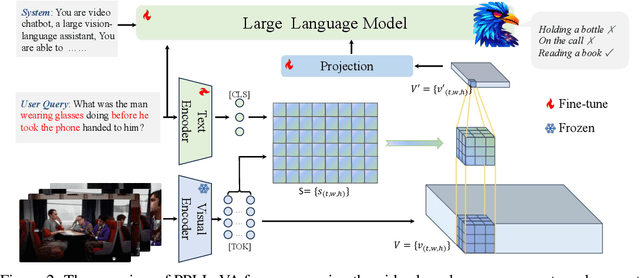
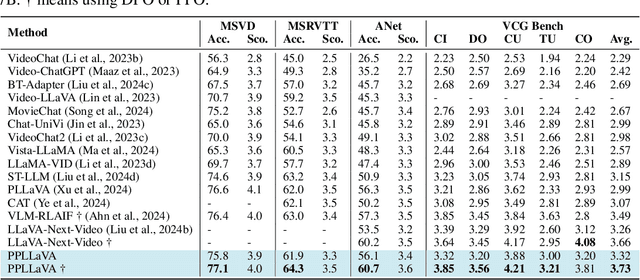
The past year has witnessed the significant advancement of video-based large language models. However, the challenge of developing a unified model for both short and long video understanding remains unresolved. Most existing video LLMs cannot handle hour-long videos, while methods custom for long videos tend to be ineffective for shorter videos and images. In this paper, we identify the key issue as the redundant content in videos. To address this, we propose a novel pooling strategy that simultaneously achieves token compression and instruction-aware visual feature aggregation. Our model is termed Prompt-guided Pooling LLaVA, or PPLLaVA for short. Specifically, PPLLaVA consists of three core components: the CLIP-based visual-prompt alignment that extracts visual information relevant to the user's instructions, the prompt-guided pooling that compresses the visual sequence to arbitrary scales using convolution-style pooling, and the clip context extension designed for lengthy prompt common in visual dialogue. Moreover, our codebase also integrates the most advanced video Direct Preference Optimization (DPO) and visual interleave training. Extensive experiments have validated the performance of our model. With superior throughput and only 1024 visual context, PPLLaVA achieves better results on image benchmarks as a video LLM, while achieving state-of-the-art performance across various video benchmarks, excelling in tasks ranging from caption generation to multiple-choice questions, and handling video lengths from seconds to hours. Codes have been available at https://github.com/farewellthree/PPLLaVA.
MUSE: Mamba is Efficient Multi-scale Learner for Text-video Retrieval
Aug 20, 2024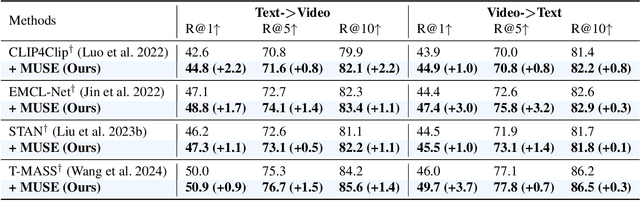
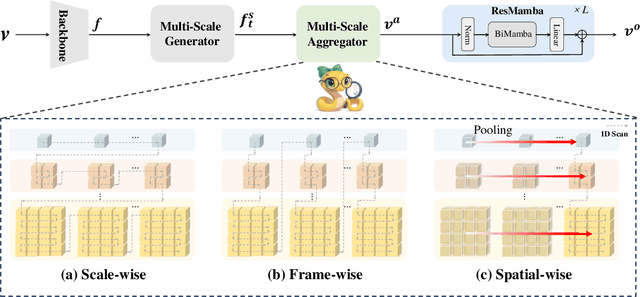
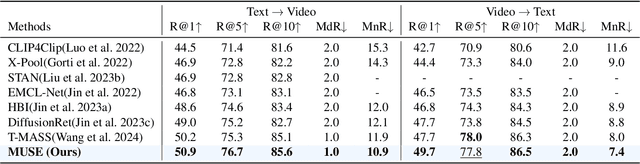
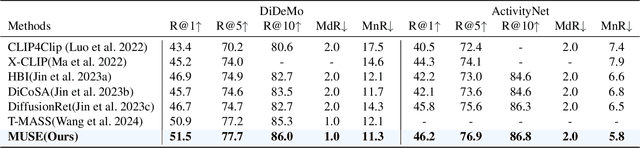
Text-Video Retrieval (TVR) aims to align and associate relevant video content with corresponding natural language queries. Most existing TVR methods are based on large-scale pre-trained vision-language models (e.g., CLIP). However, due to the inherent plain structure of CLIP, few TVR methods explore the multi-scale representations which offer richer contextual information for a more thorough understanding. To this end, we propose MUSE, a multi-scale mamba with linear computational complexity for efficient cross-resolution modeling. Specifically, the multi-scale representations are generated by applying a feature pyramid on the last single-scale feature map. Then, we employ the Mamba structure as an efficient multi-scale learner to jointly learn scale-wise representations. Furthermore, we conduct comprehensive studies to investigate different model structures and designs. Extensive results on three popular benchmarks have validated the superiority of MUSE.
RAP: Efficient Text-Video Retrieval with Sparse-and-Correlated Adapter
May 29, 2024Text-Video Retrieval (TVR) aims to align relevant video content with natural language queries. To date, most state-of-the-art TVR methods learn image-to-video transfer learning based on large-scale pre-trained visionlanguage models (e.g., CLIP). However, fully fine-tuning these pre-trained models for TVR incurs prohibitively expensive computation costs. To this end, we propose to conduct efficient text-video Retrieval with a sparse-andcorrelated AdaPter (RAP), i.e., fine-tuning the pre-trained model with a few parameterized layers. To accommodate the text-video scenario, we equip our RAP with two indispensable characteristics: temporal sparsity and correlation. Specifically, we propose a low-rank modulation module to refine the per-image features from the frozen CLIP backbone, which accentuates salient frames within the video features while alleviating temporal redundancy. Besides, we introduce an asynchronous self-attention mechanism that first selects the top responsive visual patches and augments the correlation modeling between them with learnable temporal and patch offsets. Extensive experiments on four TVR datasets demonstrate that RAP achieves superior or comparable performance compared to the fully fine-tuned counterpart and other parameter-efficient fine-tuning methods.
ST-LLM: Large Language Models Are Effective Temporal Learners
Mar 30, 2024
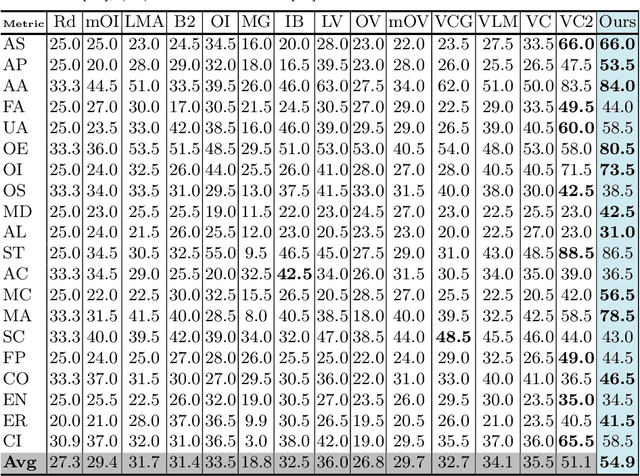
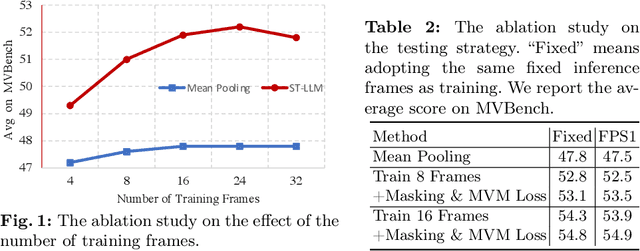

Large Language Models (LLMs) have showcased impressive capabilities in text comprehension and generation, prompting research efforts towards video LLMs to facilitate human-AI interaction at the video level. However, how to effectively encode and understand videos in video-based dialogue systems remains to be solved. In this paper, we investigate a straightforward yet unexplored question: Can we feed all spatial-temporal tokens into the LLM, thus delegating the task of video sequence modeling to the LLMs? Surprisingly, this simple approach yields significant improvements in video understanding. Based upon this, we propose ST-LLM, an effective video-LLM baseline with Spatial-Temporal sequence modeling inside LLM. Furthermore, to address the overhead and stability issues introduced by uncompressed video tokens within LLMs, we develop a dynamic masking strategy with tailor-made training objectives. For particularly long videos, we have also designed a global-local input module to balance efficiency and effectiveness. Consequently, we harness LLM for proficient spatial-temporal modeling, while upholding efficiency and stability. Extensive experimental results attest to the effectiveness of our method. Through a more concise model and training pipeline, ST-LLM establishes a new state-of-the-art result on VideoChatGPT-Bench and MVBench. Codes have been available at https://github.com/TencentARC/ST-LLM.
Mug-STAN: Adapting Image-Language Pretrained Models for General Video Understanding
Nov 25, 2023Large-scale image-language pretrained models, e.g., CLIP, have demonstrated remarkable proficiency in acquiring general multi-modal knowledge through web-scale image-text data. Despite the impressive performance of image-language models on various image tasks, how to effectively expand them on general video understanding remains an area of ongoing exploration. In this paper, we investigate the image-to-video transferring from the perspective of the model and the data, unveiling two key obstacles impeding the adaptation of image-language models: non-generalizable temporal modeling and partially misaligned video-text data. To address these challenges, we propose Spatial-Temporal Auxiliary Network with Mutual-guided alignment module (Mug-STAN), a simple yet effective framework extending image-text model to diverse video tasks and video-text data.Specifically, STAN adopts a branch structure with decomposed spatial-temporal modules to enable generalizable temporal modeling, while Mug suppresses misalignment by introducing token-wise feature aggregation of either modality from the other. Extensive experimental results verify Mug-STAN significantly improves adaptation of language-image pretrained models such as CLIP and CoCa at both video-text post-pretraining and finetuning stages. With our solution, state-of-the-art zero-shot and finetuning results on various downstream datasets, including MSR-VTT, DiDeMo, LSMDC, Kinetics-400, Something-Something-2, HMDB-51, UCF- 101, and AVA, are achieved. Moreover, by integrating pretrained Mug-STAN with the emerging multimodal dialogue model, we can realize zero-shot video chatting. Codes are available at https://github.com/farewellthree/STAN
One For All: Video Conversation is Feasible Without Video Instruction Tuning
Sep 27, 2023



The recent progress in Large Language Models (LLM) has spurred various advancements in image-language conversation agents, while how to build a proficient video-based dialogue system is still under exploration. Considering the extensive scale of LLM and visual backbone, minimal GPU memory is left for facilitating effective temporal modeling, which is crucial for comprehending and providing feedback on videos. To this end, we propose Branching Temporal Adapter (BT-Adapter), a novel method for extending image-language pretrained models into the video domain. Specifically, BT-Adapter serves as a plug-and-use temporal modeling branch alongside the pretrained visual encoder, which is tuned while keeping the backbone frozen. Just pretrained once, BT-Adapter can be seamlessly integrated into all image conversation models using this version of CLIP, enabling video conversations without the need for video instructions. Besides, we develop a unique asymmetric token masking strategy inside the branch with tailor-made training tasks for BT-Adapter, facilitating faster convergence and better results. Thanks to BT-Adapter, we are able to empower existing multimodal dialogue models with strong video understanding capabilities without incurring excessive GPU costs. Without bells and whistles, BT-Adapter achieves (1) state-of-the-art zero-shot results on various video tasks using thousands of fewer GPU hours. (2) better performance than current video chatbots without any video instruction tuning. (3) state-of-the-art results of video chatting using video instruction tuning, outperforming previous SOTAs by a large margin.