 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeST-LLM: Large Language Models Are Effective Temporal Learners
Paper and Code

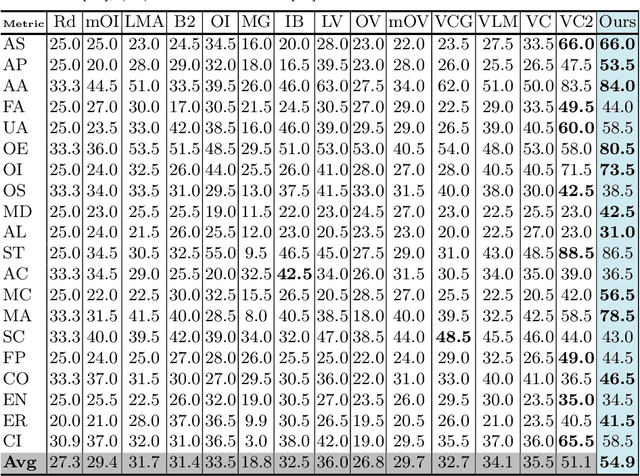
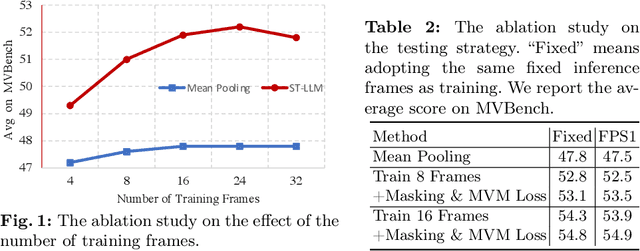

Large Language Models (LLMs) have showcased impressive capabilities in text comprehension and generation, prompting research efforts towards video LLMs to facilitate human-AI interaction at the video level. However, how to effectively encode and understand videos in video-based dialogue systems remains to be solved. In this paper, we investigate a straightforward yet unexplored question: Can we feed all spatial-temporal tokens into the LLM, thus delegating the task of video sequence modeling to the LLMs? Surprisingly, this simple approach yields significant improvements in video understanding. Based upon this, we propose ST-LLM, an effective video-LLM baseline with Spatial-Temporal sequence modeling inside LLM. Furthermore, to address the overhead and stability issues introduced by uncompressed video tokens within LLMs, we develop a dynamic masking strategy with tailor-made training objectives. For particularly long videos, we have also designed a global-local input module to balance efficiency and effectiveness. Consequently, we harness LLM for proficient spatial-temporal modeling, while upholding efficiency and stability. Extensive experimental results attest to the effectiveness of our method. Through a more concise model and training pipeline, ST-LLM establishes a new state-of-the-art result on VideoChatGPT-Bench and MVBench. Codes have been available at https://github.com/TencentARC/ST-LLM.