 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUSE: Mamba is Efficient Multi-scale Learner for Text-video Retrieval
Paper and Code
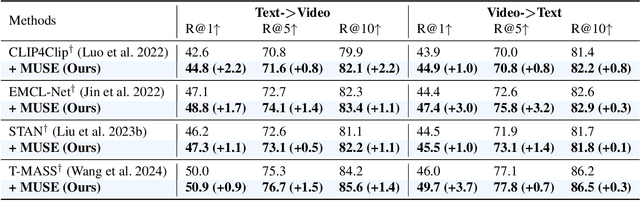
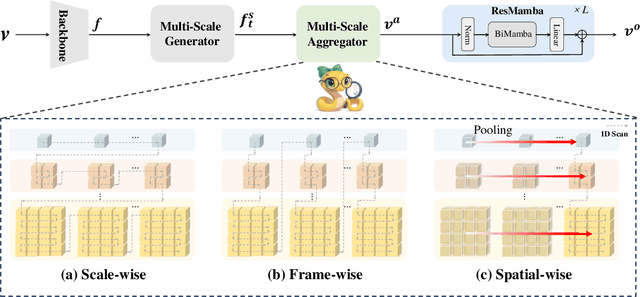
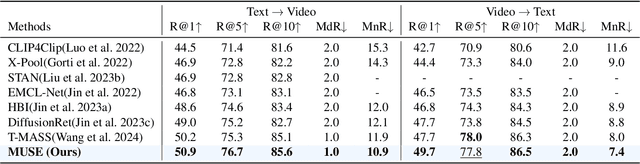
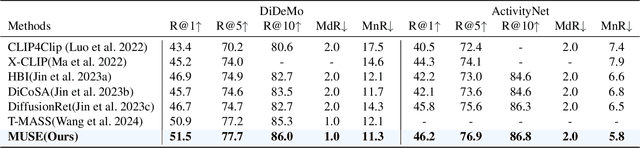
Text-Video Retrieval (TVR) aims to align and associate relevant video content with corresponding natural language queries. Most existing TVR methods are based on large-scale pre-trained vision-language models (e.g., CLIP). However, due to the inherent plain structure of CLIP, few TVR methods explore the multi-scale representations which offer richer contextual information for a more thorough understanding. To this end, we propose MUSE, a multi-scale mamba with linear computational complexity for efficient cross-resolution modeling. Specifically, the multi-scale representations are generated by applying a feature pyramid on the last single-scale feature map. Then, we employ the Mamba structure as an efficient multi-scale learner to jointly learn scale-wise representations. Furthermore, we conduct comprehensive studies to investigate different model structures and designs. Extensive results on three popular benchmarks have validated the superiority of MUSE.