 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEconomy of Minds: Emerging Multi-Agent Intelligence with Economic Interactions
Jun 01, 2026How can a population of agents self-orchestrate and self-adapt into stronger collective intelligence without centralized control? Inspired by Friedrich Hayek's economic theory of decentralized coordination in markets, we study this question through an agent economy in which agents compete via auctions for the right to act, exchange payments, and accumulate wealth from environmental rewards. These simple economic signals induce decentralized credit assignment, driving planning without global orchestration or explicit communication protocols. The population evolves through economic selection: effective agents accumulate wealth and are mutated via exploitation, while ineffective ones go bankrupt and are replaced via exploration. We show that, initialized with weak agents, the economy produces emergent multi-step reasoning strategies and outperforms stronger monolithic baselines across five agentic tasks, including mathematical reasoning, financial research, scientific research, accelerator design, and distributed-system optimization. We further provide theoretical insights into how economic dynamics shape agent behaviors, linking local incentives to long-term global performance. Our results suggest a new path to multi-agent intelligence: rather than engineering coordination, we can design decentralized incentive structures under which it automatically emerges.
Self-Improving Language Models with Bidirectional Evolutionary Search
May 27, 2026Search has been proposed as an effective method for self-improving language models and agentic systems, both for post-training sample generation and for inference. However, widely used methods such as best-of-N sampling and tree search face two fundamental limitations: they are guided by sparse verification signals, and they construct candidates primarily through autoregressive expansion, restricting exploration to regions with substantial model probability mass. To address these, we propose Bidirectional Evolutionary Search (BES), a search framework that couples forward candidate evolution with backward goal decomposition. In the forward search, BES augments standard expansion with evolution operators that recombine partial trajectories to generate candidates that are difficult to obtain from a single model rollout. In the backward search, BES recursively decomposes the original task into checkable subgoals, producing dense intermediate feedback that guides forward search. We provide theoretical motivation showing that candidates generated by expansion-only search are confined to a narrow entropy shell while evolutionary operators can escape it, and that backward search can exponentially reduce the number of required samples to find a correct answer. Experiments show that on challenging post-training tasks where mainstream post-training algorithms fail to improve, BES enables consistent gains, and on three open problem solving benchmarks at inference time, BES outperforms existing open-source frameworks in both average and best-case performance. Code and trained models are available at https://github.com/Embodied-Minds-Lab/BES.
Gloria: Consistent Character Video Generation via Content Anchors
Mar 31, 2026Digital characters are central to modern media, yet generating character videos with long-duration, consistent multi-view appearance and expressive identity remains challenging. Existing approaches either provide insufficient context to preserve identity or leverage non-character-centric information as the memory, leading to suboptimal consistency. Recognizing that character video generation inherently resembles an outside-looking-in scenario. In this work, we propose representing the character visual attributes through a compact set of anchor frames. This design provides stable references for consistency, while reference-based video generation inherently faces challenges of copy-pasting and multi-reference conflicts. To address these, we introduce two mechanisms: Superset Content Anchoring, providing intra- and extra-training clip cues to prevent duplication, and RoPE as Weak Condition, encoding positional offsets to distinguish multiple anchors. Furthermore, we construct a scalable pipeline to extract these anchors from massive videos. Experiments show our method generates high-quality character videos exceeding 10 minutes, and achieves expressive identity and appearance consistency across views, surpassing existing methods.
Sparse Reward Subsystem in Large Language Models
Feb 01, 2026In this paper, we identify a sparse reward subsystem within the hidden states of Large Language Models (LLMs), drawing an analogy to the biological reward subsystem in the human brain. We demonstrate that this subsystem contains value neurons that represent the model's internal expectation of state value, and through intervention experiments, we establish the importance of these neurons for reasoning. Our experiments reveal that these value neurons are robust across diverse datasets, model scales, and architectures; furthermore, they exhibit significant transferability across different datasets and models fine-tuned from the same base model. By examining cases where value predictions and actual rewards diverge, we identify dopamine neurons within the reward subsystem which encode reward prediction errors (RPE). These neurons exhibit high activation when the reward is higher than expected and low activation when the reward is lower than expected.
metaTextGrad: Automatically optimizing language model optimizers
May 24, 2025Large language models (LLMs) are increasingly used in learning algorithms, evaluations, and optimization tasks. Recent studies have shown that using LLM-based optimizers to automatically optimize model prompts, demonstrations, predictions themselves, or other components can significantly enhance the performance of AI systems, as demonstrated by frameworks such as DSPy and TextGrad. However, optimizers built on language models themselves are usually designed by humans with manual design choices; optimizers themselves are not optimized. Moreover, these optimizers are general purpose by design, to be useful to a broad audience, and are not tailored for specific tasks. To address these challenges, we propose metaTextGrad, which focuses on designing a meta-optimizer to further enhance existing optimizers and align them to be good optimizers for a given task. Our approach consists of two key components: a meta prompt optimizer and a meta structure optimizer. The combination of these two significantly improves performance across multiple benchmarks, achieving an average absolute performance improvement of up to 6% compared to the best baseline.
S-INF: Towards Realistic Indoor Scene Synthesis via Scene Implicit Neural Field
Dec 23, 2024Learning-based methods have become increasingly popular in 3D indoor scene synthesis (ISS), showing superior performance over traditional optimization-based approaches. These learning-based methods typically model distributions on simple yet explicit scene representations using generative models. However, due to the oversimplified explicit representations that overlook detailed information and the lack of guidance from multimodal relationships within the scene, most learning-based methods struggle to generate indoor scenes with realistic object arrangements and styles. In this paper, we introduce a new method, Scene Implicit Neural Field (S-INF), for indoor scene synthesis, aiming to learn meaningful representations of multimodal relationships, to enhance the realism of indoor scene synthesis. S-INF assumes that the scene layout is often related to the object-detailed information. It disentangles the multimodal relationships into scene layout relationships and detailed object relationships, fusing them later through implicit neural fields (INFs). By learning specialized scene layout relationships and projecting them into S-INF, we achieve a realistic generation of scene layout. Additionally, S-INF captures dense and detailed object relationships through differentiable rendering, ensuring stylistic consistency across objects. Through extensive experiments on the benchmark 3D-FRONT dataset, we demonstrate that our method consistently achieves state-of-the-art performance under different types of ISS.
LLaVA-CoT: Let Vision Language Models Reason Step-by-Step
Nov 25, 2024



Large language models have demonstrated substantial advancements in reasoning capabilities, particularly through inference-time scaling, as illustrated by models such as OpenAI's o1. However, current Vision-Language Models (VLMs) often struggle to perform systematic and structured reasoning, especially when handling complex visual question-answering tasks. In this work, we introduce LLaVA-CoT, a novel VLM designed to conduct autonomous multistage reasoning. Unlike chain-of-thought prompting, LLaVA-CoT independently engages in sequential stages of summarization, visual interpretation, logical reasoning, and conclusion generation. This structured approach enables LLaVA-CoT to achieve marked improvements in precision on reasoning-intensive tasks. To accomplish this, we compile the LLaVA-CoT-100k dataset, integrating samples from various visual question answering sources and providing structured reasoning annotations. Besides, we propose an inference-time stage-level beam search method, which enables effective inference-time scaling. Remarkably, with only 100k training samples and a simple yet effective inference time scaling method, LLaVA-CoT not only outperforms its base model by 8.9% on a wide range of multimodal reasoning benchmarks, but also surpasses the performance of larger and even closed-source models, such as Gemini-1.5-pro, GPT-4o-mini, and Llama-3.2-90B-Vision-Instruct.
LLaVA-o1: Let Vision Language Models Reason Step-by-Step
Nov 15, 2024Large language models have demonstrated substantial advancements in reasoning capabilities, particularly through inference-time scaling, as illustrated by models such as OpenAI's o1. However, current Vision-Language Models (VLMs) often struggle to perform systematic and structured reasoning, especially when handling complex visual question-answering tasks. In this work, we introduce LLaVA-o1, a novel VLM designed to conduct autonomous multistage reasoning. Unlike chain-of-thought prompting, LLaVA-o1 independently engages in sequential stages of summarization, visual interpretation, logical reasoning, and conclusion generation. This structured approach enables LLaVA-o1 to achieve marked improvements in precision on reasoning-intensive tasks. To accomplish this, we compile the LLaVA-o1-100k dataset, integrating samples from various visual question answering sources and providing structured reasoning annotations. Besides, we propose an inference-time stage-level beam search method, which enables effective inference-time scaling. Remarkably, with only 100k training samples and a simple yet effective inference time scaling method, LLaVA-o1 not only outperforms its base model by 8.9% on a wide range of multimodal reasoning benchmarks, but also surpasses the performance of larger and even closed-source models, such as Gemini-1.5-pro, GPT-4o-mini, and Llama-3.2-90B-Vision-Instruct.
MENTOR: Mixture-of-Experts Network with Task-Oriented Perturbation for Visual Reinforcement Learning
Oct 19, 2024
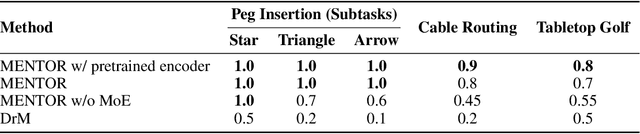
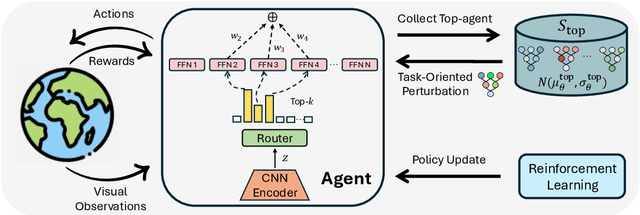
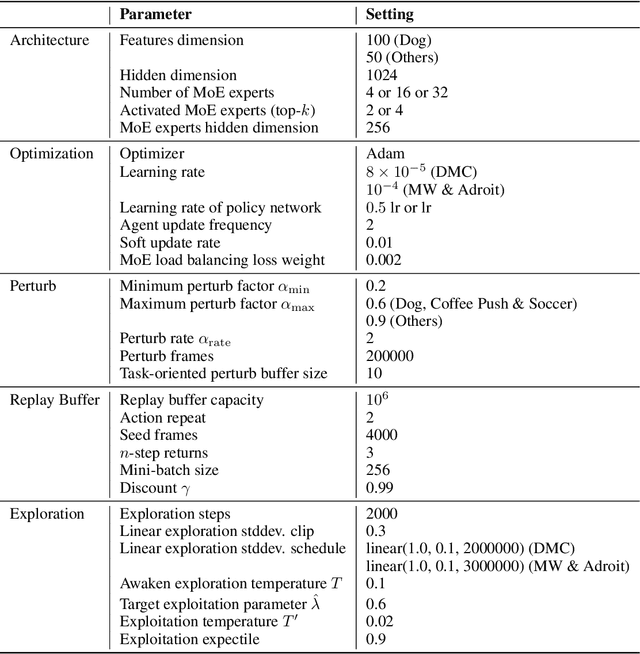
Visual deep reinforcement learning (RL) enables robots to acquire skills from visual input for unstructured tasks. However, current algorithms suffer from low sample efficiency, limiting their practical applicability. In this work, we present MENTOR, a method that improves both the architecture and optimization of RL agents. Specifically, MENTOR replaces the standard multi-layer perceptron (MLP) with a mixture-of-experts (MoE) backbone, enhancing the agent's ability to handle complex tasks by leveraging modular expert learning to avoid gradient conflicts. Furthermore, MENTOR introduces a task-oriented perturbation mechanism, which heuristically samples perturbation candidates containing task-relevant information, leading to more targeted and effective optimization. MENTOR outperforms state-of-the-art methods across three simulation domains -- DeepMind Control Suite, Meta-World, and Adroit. Additionally, MENTOR achieves an average of 83% success rate on three challenging real-world robotic manipulation tasks including peg insertion, cable routing, and tabletop golf, which significantly surpasses the success rate of 32% from the current strongest model-free visual RL algorithm. These results underscore the importance of sample efficiency in advancing visual RL for real-world robotics. Experimental videos are available at https://suninghuang19.github.io/mentor_page.
Learning Semantic Latent Directions for Accurate and Controllable Human Motion Prediction
Jul 16, 2024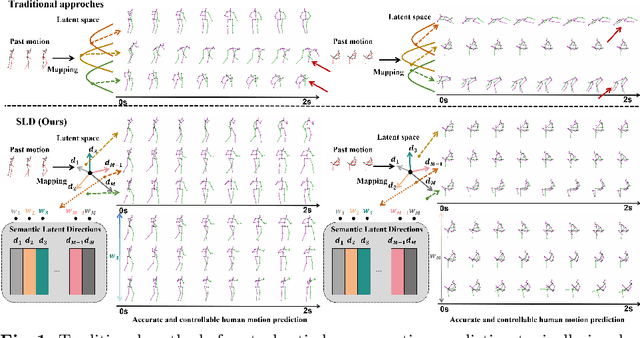
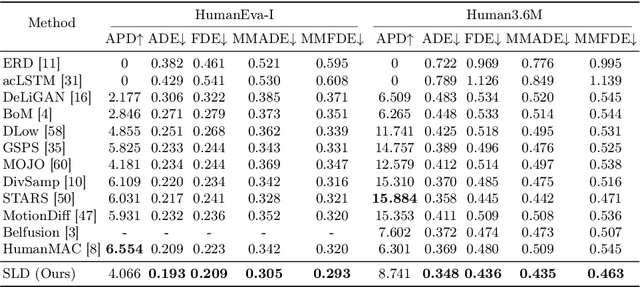
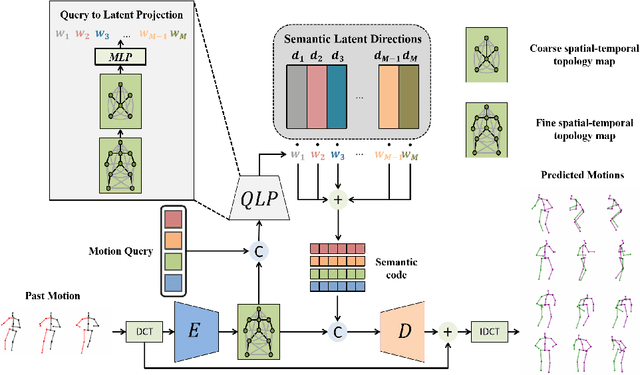

In the realm of stochastic human motion prediction (SHMP), researchers have often turned to generative models like GANS, VAEs and diffusion models. However, most previous approaches have struggled to accurately predict motions that are both realistic and coherent with past motion due to a lack of guidance on the latent distribution. In this paper, we introduce Semantic Latent Directions (SLD) as a solution to this challenge, aiming to constrain the latent space to learn meaningful motion semantics and enhance the accuracy of SHMP. SLD defines a series of orthogonal latent directions and represents the hypothesis of future motion as a linear combination of these directions. By creating such an information bottleneck, SLD excels in capturing meaningful motion semantics, thereby improving the precision of motion predictions. Moreover, SLD offers controllable prediction capabilities by adjusting the coefficients of the latent directions during the inference phase. Expanding on SLD, we introduce a set of motion queries to enhance the diversity of predictions. By aligning these motion queries with the SLD space, SLD is further promoted to more accurate and coherent motion predictions. Through extensive experiments conducted on widely used benchmarks, we showcase the superiority of our method in accurately predicting motions while maintaining a balance of realism and diversity. Our code and pretrained models are available at https://github.com/GuoweiXu368/SLD-HMP.