 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Object Advertisement Creative Generation
Mar 14, 2026Lifestyle images are photographs that capture environments and objects in everyday settings. In furniture product marketing, advertisers often create lifestyle images containing products to resonate with potential buyers, allowing buyers to visualize how the products fit into their daily lives. While recent advances in Generative Artificial Intelligence (GenAI) have given rise to realistic image content creation, their application in e-commerce advertising is challenging because high-quality ads must authentically representing the products in realistic scearios. Therefore, manual intervention is usually required for individual generations, making it difficult to scale to larger product catalogs. To understand the challenges faced by advertisers using GenAI to create lifestyle images at scale, we conducted evaluations on ad images generated using state-of-the-art image generation models and identified the major challenges. Based on our findings, we present CreativeAds, a multi-product ad creation system that supports scalable automated generation with customized parameter adjustment for individual generation. To ensure automated high-quality ad generation, CreativeAds innovates a pipeline that consists of three modules to address challenges in product pairing, layout generation, and background generation separately. Furthermore, CreativeAds contains an intuitive user interface to allow users to oversee generation at scale, and it also supports detailed controls on individual generation for user customized adjustments. We performed a user study on CreativeAds and extensive evaluations of the generated images, demonstrating CreativeAds's ability to create large number of high-quality images at scale for advertisers without requiring expertise in GenAI tools.
Visual Data Diagnosis and Debiasing with Concept Graphs
Sep 26, 2024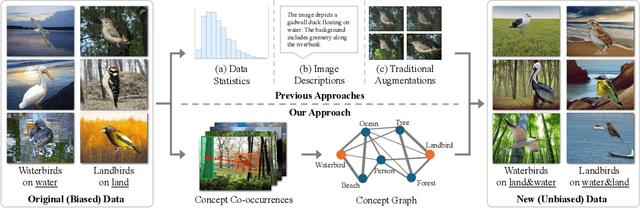
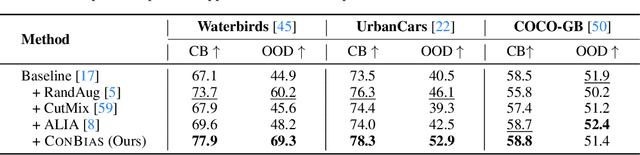
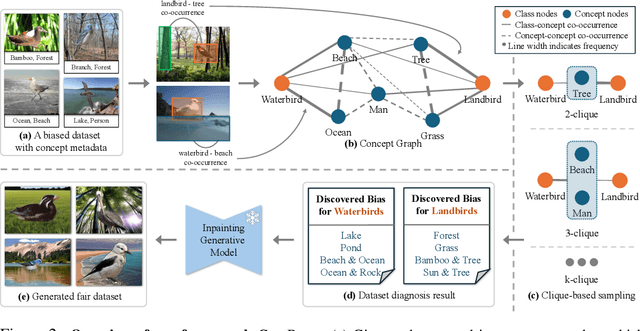

The widespread success of deep learning models today is owed to the curation of extensive datasets significant in size and complexity. However, such models frequently pick up inherent biases in the data during the training process, leading to unreliable predictions. Diagnosing and debiasing datasets is thus a necessity to ensure reliable model performance. In this paper, we present CONBIAS, a novel framework for diagnosing and mitigating Concept co-occurrence Biases in visual datasets. CONBIAS represents visual datasets as knowledge graphs of concepts, enabling meticulous analysis of spurious concept co-occurrences to uncover concept imbalances across the whole dataset. Moreover, we show that by employing a novel clique-based concept balancing strategy, we can mitigate these imbalances, leading to enhanced performance on downstream tasks. Extensive experiments show that data augmentation based on a balanced concept distribution augmented by CONBIAS improves generalization performance across multiple datasets compared to state-of-the-art methods. We will make our code and data publicly available.
Can Pre-Trained Text-to-Image Models Generate Visual Goals for Reinforcement Learning?
Jul 15, 2023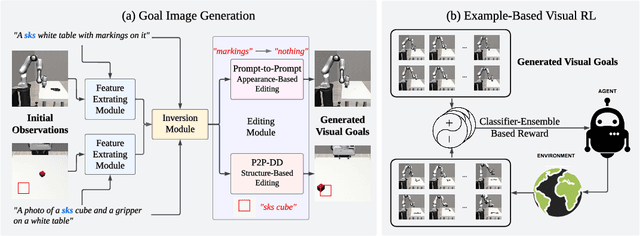



Pre-trained text-to-image generative models can produce diverse, semantically rich, and realistic images from natural language descriptions. Compared with language, images usually convey information with more details and less ambiguity. In this study, we propose Learning from the Void (LfVoid), a method that leverages the power of pre-trained text-to-image models and advanced image editing techniques to guide robot learning. Given natural language instructions, LfVoid can edit the original observations to obtain goal images, such as "wiping" a stain off a table. Subsequently, LfVoid trains an ensembled goal discriminator on the generated image to provide reward signals for a reinforcement learning agent, guiding it to achieve the goal. The ability of LfVoid to learn with zero in-domain training on expert demonstrations or true goal observations (the void) is attributed to the utilization of knowledge from web-scale generative models. We evaluate LfVoid across three simulated tasks and validate its feasibility in the corresponding real-world scenarios. In addition, we offer insights into the key considerations for the effective integration of visual generative models into robot learning workflows. We posit that our work represents an initial step towards the broader application of pre-trained visual generative models in the robotics field. Our project page: https://lfvoid-rl.github.io/.