 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Data Diagnosis and Debiasing with Concept Graphs
Sep 26, 2024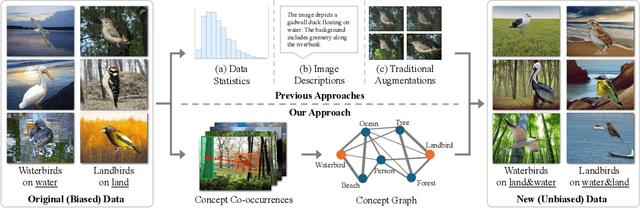
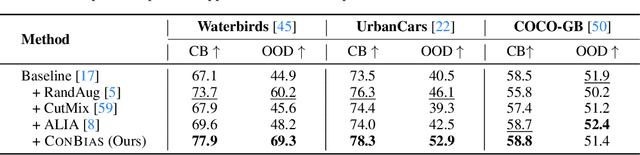
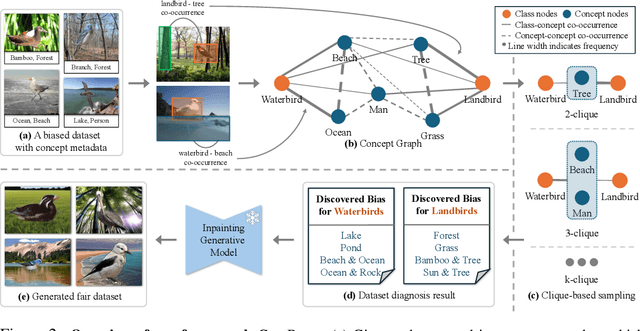

The widespread success of deep learning models today is owed to the curation of extensive datasets significant in size and complexity. However, such models frequently pick up inherent biases in the data during the training process, leading to unreliable predictions. Diagnosing and debiasing datasets is thus a necessity to ensure reliable model performance. In this paper, we present CONBIAS, a novel framework for diagnosing and mitigating Concept co-occurrence Biases in visual datasets. CONBIAS represents visual datasets as knowledge graphs of concepts, enabling meticulous analysis of spurious concept co-occurrences to uncover concept imbalances across the whole dataset. Moreover, we show that by employing a novel clique-based concept balancing strategy, we can mitigate these imbalances, leading to enhanced performance on downstream tasks. Extensive experiments show that data augmentation based on a balanced concept distribution augmented by CONBIAS improves generalization performance across multiple datasets compared to state-of-the-art methods. We will make our code and data publicly available.
On the Robustness of ChatGPT: An Adversarial and Out-of-distribution Perspective
Mar 02, 2023



ChatGPT is a recent chatbot service released by OpenAI and is receiving increasing attention over the past few months. While evaluations of various aspects of ChatGPT have been done, its robustness, i.e., the performance to unexpected inputs, is still unclear to the public. Robustness is of particular concern in responsible AI, especially for safety-critical applications. In this paper, we conduct a thorough evaluation of the robustness of ChatGPT from the adversarial and out-of-distribution (OOD) perspective. To do so, we employ the AdvGLUE and ANLI benchmarks to assess adversarial robustness and the Flipkart review and DDXPlus medical diagnosis datasets for OOD evaluation. We select several popular foundation models as baselines. Results show that ChatGPT shows consistent advantages on most adversarial and OOD classification and translation tasks. However, the absolute performance is far from perfection, which suggests that adversarial and OOD robustness remains a significant threat to foundation models. Moreover, ChatGPT shows astounding performance in understanding dialogue-related texts and we find that it tends to provide informal suggestions for medical tasks instead of definitive answers. Finally, we present in-depth discussions of possible research directions.
Bayesian Optimization Augmented with Actively Elicited Expert Knowledge
Aug 18, 2022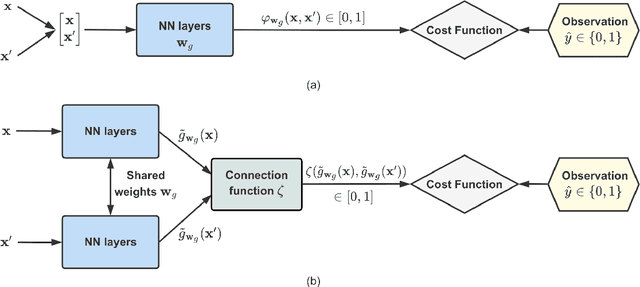
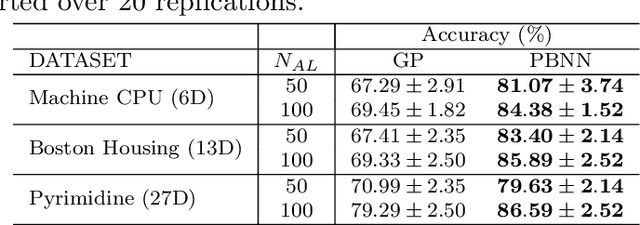
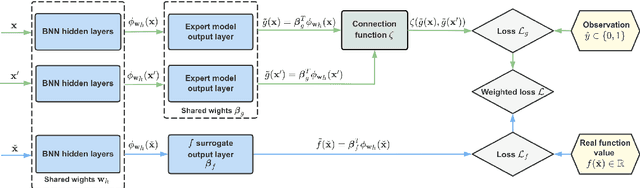
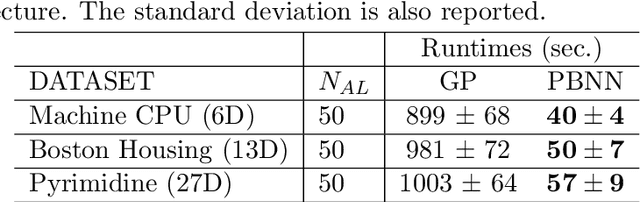
Bayesian optimization (BO) is a well-established method to optimize black-box functions whose direct evaluations are costly. In this paper, we tackle the problem of incorporating expert knowledge into BO, with the goal of further accelerating the optimization, which has received very little attention so far. We design a multi-task learning architecture for this task, with the goal of jointly eliciting the expert knowledge and minimizing the objective function. In particular, this allows for the expert knowledge to be transferred into the BO task. We introduce a specific architecture based on Siamese neural networks to handle the knowledge elicitation from pairwise queries. Experiments on various benchmark functions with both simulated and actual human experts show that the proposed method significantly speeds up BO even when the expert knowledge is biased compared to the objective function.
Data-free Backdoor Removal based on Channel Lipschitzness
Aug 05, 2022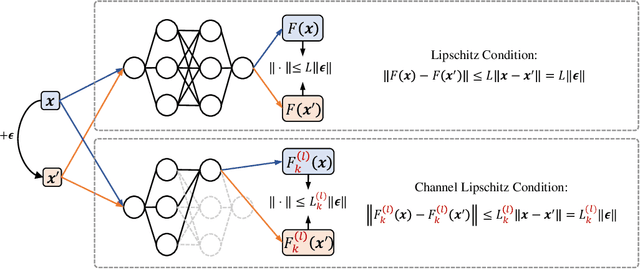
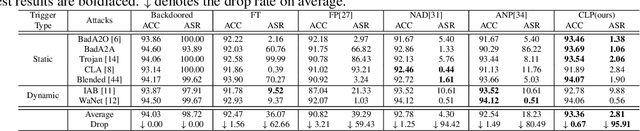
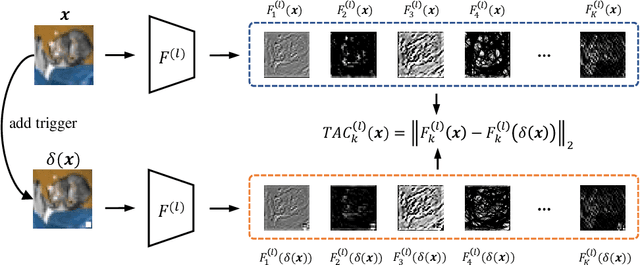
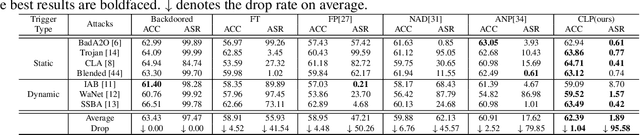
Recent studies have shown that Deep Neural Networks (DNNs) are vulnerable to the backdoor attacks, which leads to malicious behaviors of DNNs when specific triggers are attached to the input images. It was further demonstrated that the infected DNNs possess a collection of channels, which are more sensitive to the backdoor triggers compared with normal channels. Pruning these channels was then shown to be effective in mitigating the backdoor behaviors. To locate those channels, it is natural to consider their Lipschitzness, which measures their sensitivity against worst-case perturbations on the inputs. In this work, we introduce a novel concept called Channel Lipschitz Constant (CLC), which is defined as the Lipschitz constant of the mapping from the input images to the output of each channel. Then we provide empirical evidences to show the strong correlation between an Upper bound of the CLC (UCLC) and the trigger-activated change on the channel activation. Since UCLC can be directly calculated from the weight matrices, we can detect the potential backdoor channels in a data-free manner, and do simple pruning on the infected DNN to repair the model. The proposed Channel Lipschitzness based Pruning (CLP) method is super fast, simple, data-free and robust to the choice of the pruning threshold. Extensive experiments are conducted to evaluate the efficiency and effectiveness of CLP, which achieves state-of-the-art results among the mainstream defense methods even without any data. Source codes are available at https://github.com/rkteddy/channel-Lipschitzness-based-pruning.
Towards Class-Specific Unit
Nov 22, 2020
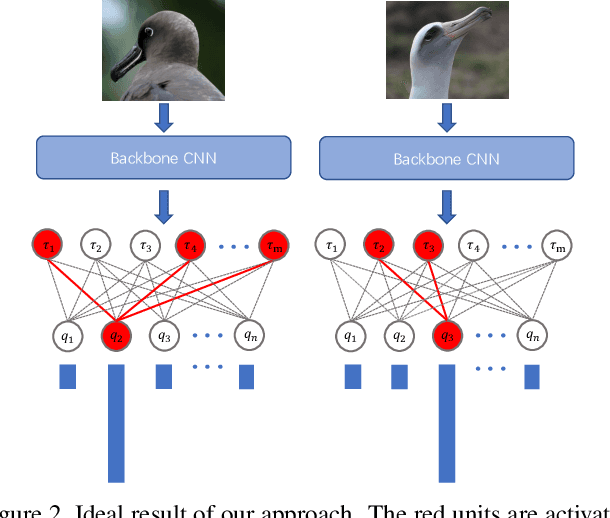

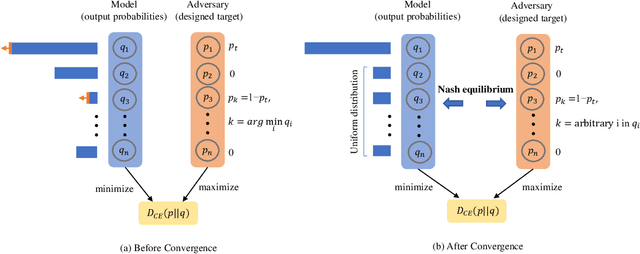
Class selectivity is an attribute of a unit in deep neural networks, which characterizes the discriminative ability of units to a specific class. Intuitively, decisions made by several highly selective units are more interpretable since it is easier to be traced back to the origin while that made by complex combinations of lowly selective units are more difficult to interpret. In this work, we develop a novel way to directly train highly selective units, through which we are able to examine the performance of a network that only rely on highly selective units. Specifically, we train the network such that all the units in the penultimate layer only response to one specific class, which we named as class-specific unit. By innovatively formulating the problem using mutual information, we find that in such a case, the output of the model has a special form that all the probabilities over non-target classes are uniformly distributed. We then propose a minimax loss based on a game theoretic framework to achieve the goal. Nash equilibria are proved to exist and the outcome is consistent with our regularization objective. Experimental results show that the model trained with the proposed objective outperforms models trained with baseline objective among all the tasks we test. Our results shed light on the role of class-specific units by indicating that they can be directly used for decisions without relying on low selective units.