 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Bayesian Experimental Design via Online Planning
May 26, 2026Bayesian experimental design (BED) is a principled framework for data-efficient design of sequential experiments. However, existing BED methods are unable to adapt to dynamic constraints inherent in real-world tasks due to budget limitations, varying costs, or physical constraints that restrict how designs evolve over time. In this paper, we introduce a novel approach to BED that enables constrained optimization of experimental designs by combining offline pre-training of an amortized policy and a posterior network with online multi-step lookahead planning using scenario trees. We empirically demonstrate that our method yields substantially more informative design sequences than existing methods across a range of constrained BED tasks, while incurring only a modest additional computational overhead.
In-Context Multi-Objective Optimization
Dec 11, 2025Balancing competing objectives is omnipresent across disciplines, from drug design to autonomous systems. Multi-objective Bayesian optimization is a promising solution for such expensive, black-box problems: it fits probabilistic surrogates and selects new designs via an acquisition function that balances exploration and exploitation. In practice, it requires tailored choices of surrogate and acquisition that rarely transfer to the next problem, is myopic when multi-step planning is often required, and adds refitting overhead, particularly in parallel or time-sensitive loops. We present TAMO, a fully amortized, universal policy for multi-objective black-box optimization. TAMO uses a transformer architecture that operates across varying input and objective dimensions, enabling pretraining on diverse corpora and transfer to new problems without retraining: at test time, the pretrained model proposes the next design with a single forward pass. We pretrain the policy with reinforcement learning to maximize cumulative hypervolume improvement over full trajectories, conditioning on the entire query history to approximate the Pareto frontier. Across synthetic benchmarks and real tasks, TAMO produces fast proposals, reducing proposal time by 50-1000x versus alternatives while matching or improving Pareto quality under tight evaluation budgets. These results show that transformers can perform multi-objective optimization entirely in-context, eliminating per-task surrogate fitting and acquisition engineering, and open a path to foundation-style, plug-and-play optimizers for scientific discovery workflows.
Efficient Autoregressive Inference for Transformer Probabilistic Models
Oct 10, 2025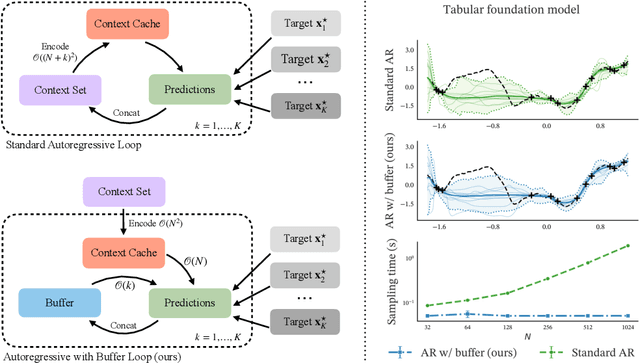

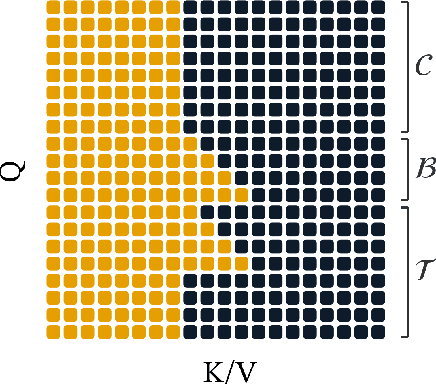

Transformer-based models for amortized probabilistic inference, such as neural processes, prior-fitted networks, and tabular foundation models, excel at single-pass marginal prediction. However, many real-world applications, from signal interpolation to multi-column tabular predictions, require coherent joint distributions that capture dependencies between predictions. While purely autoregressive architectures efficiently generate such distributions, they sacrifice the flexible set-conditioning that makes these models powerful for meta-learning. Conversely, the standard approach to obtain joint distributions from set-based models requires expensive re-encoding of the entire augmented conditioning set at each autoregressive step. We introduce a causal autoregressive buffer that preserves the advantages of both paradigms. Our approach decouples context encoding from updating the conditioning set. The model processes the context once and caches it. A dynamic buffer then captures target dependencies: as targets are incorporated, they enter the buffer and attend to both the cached context and previously buffered targets. This enables efficient batched autoregressive generation and one-pass joint log-likelihood evaluation. A unified training strategy allows seamless integration of set-based and autoregressive modes at minimal additional cost. Across synthetic functions, EEG signals, cognitive models, and tabular data, our method matches predictive accuracy of strong baselines while delivering up to 20 times faster joint sampling. Our approach combines the efficiency of autoregressive generative models with the representational power of set-based conditioning, making joint prediction practical for transformer-based probabilistic models.
ALINE: Joint Amortization for Bayesian Inference and Active Data Acquisition
Jun 08, 2025Many critical applications, from autonomous scientific discovery to personalized medicine, demand systems that can both strategically acquire the most informative data and instantaneously perform inference based upon it. While amortized methods for Bayesian inference and experimental design offer part of the solution, neither approach is optimal in the most general and challenging task, where new data needs to be collected for instant inference. To tackle this issue, we introduce the Amortized Active Learning and Inference Engine (ALINE), a unified framework for amortized Bayesian inference and active data acquisition. ALINE leverages a transformer architecture trained via reinforcement learning with a reward based on self-estimated information gain provided by its own integrated inference component. This allows it to strategically query informative data points while simultaneously refining its predictions. Moreover, ALINE can selectively direct its querying strategy towards specific subsets of model parameters or designated predictive tasks, optimizing for posterior estimation, data prediction, or a mixture thereof. Empirical results on regression-based active learning, classical Bayesian experimental design benchmarks, and a psychometric model with selectively targeted parameters demonstrate that ALINE delivers both instant and accurate inference along with efficient selection of informative points.
PABBO: Preferential Amortized Black-Box Optimization
Mar 02, 2025Preferential Bayesian Optimization (PBO) is a sample-efficient method to learn latent user utilities from preferential feedback over a pair of designs. It relies on a statistical surrogate model for the latent function, usually a Gaussian process, and an acquisition strategy to select the next candidate pair to get user feedback on. Due to the non-conjugacy of the associated likelihood, every PBO step requires a significant amount of computations with various approximate inference techniques. This computational overhead is incompatible with the way humans interact with computers, hindering the use of PBO in real-world cases. Building on the recent advances of amortized BO, we propose to circumvent this issue by fully amortizing PBO, meta-learning both the surrogate and the acquisition function. Our method comprises a novel transformer neural process architecture, trained using reinforcement learning and tailored auxiliary losses. On a benchmark composed of synthetic and real-world datasets, our method is several orders of magnitude faster than the usual Gaussian process-based strategies and often outperforms them in accuracy.
Amortized Bayesian Experimental Design for Decision-Making
Nov 04, 2024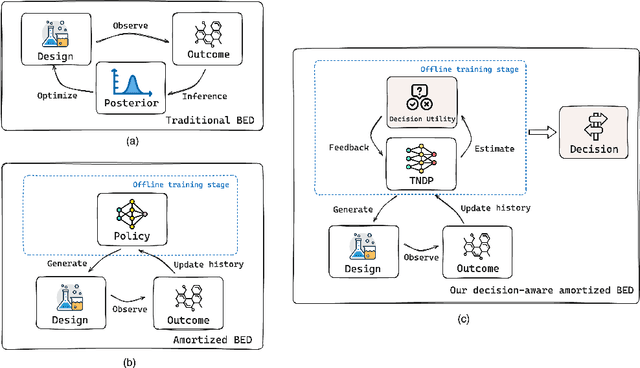
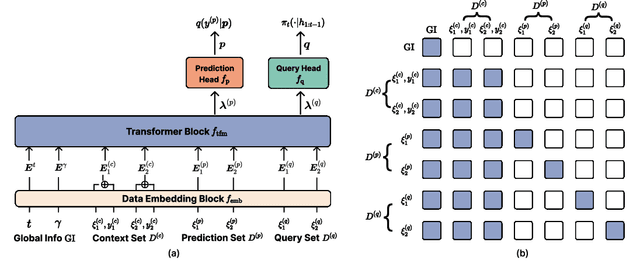
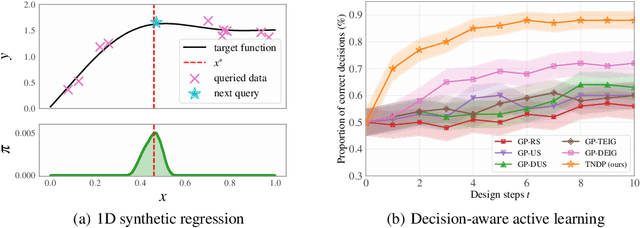

Many critical decisions, such as personalized medical diagnoses and product pricing, are made based on insights gained from designing, observing, and analyzing a series of experiments. This highlights the crucial role of experimental design, which goes beyond merely collecting information on system parameters as in traditional Bayesian experimental design (BED), but also plays a key part in facilitating downstream decision-making. Most recent BED methods use an amortized policy network to rapidly design experiments. However, the information gathered through these methods is suboptimal for down-the-line decision-making, as the experiments are not inherently designed with downstream objectives in mind. In this paper, we present an amortized decision-aware BED framework that prioritizes maximizing downstream decision utility. We introduce a novel architecture, the Transformer Neural Decision Process (TNDP), capable of instantly proposing the next experimental design, whilst inferring the downstream decision, thus effectively amortizing both tasks within a unified workflow. We demonstrate the performance of our method across several tasks, showing that it can deliver informative designs and facilitate accurate decision-making.
Amortized Probabilistic Conditioning for Optimization, Simulation and Inference
Oct 20, 2024Amortized meta-learning methods based on pre-training have propelled fields like natural language processing and vision. Transformer-based neural processes and their variants are leading models for probabilistic meta-learning with a tractable objective. Often trained on synthetic data, these models implicitly capture essential latent information in the data-generation process. However, existing methods do not allow users to flexibly inject (condition on) and extract (predict) this probabilistic latent information at runtime, which is key to many tasks. We introduce the Amortized Conditioning Engine (ACE), a new transformer-based meta-learning model that explicitly represents latent variables of interest. ACE affords conditioning on both observed data and interpretable latent variables, the inclusion of priors at runtime, and outputs predictive distributions for discrete and continuous data and latents. We show ACE's modeling flexibility and performance in diverse tasks such as image completion and classification, Bayesian optimization, and simulation-based inference.
Cost-aware Simulation-based Inference
Oct 10, 2024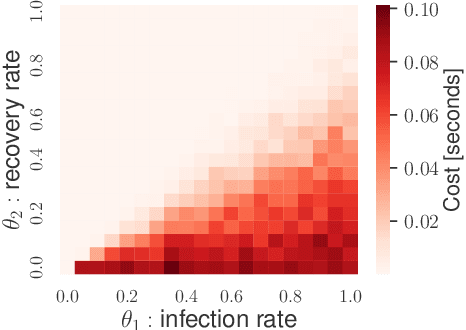
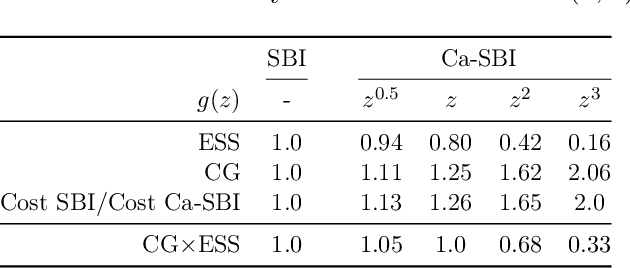
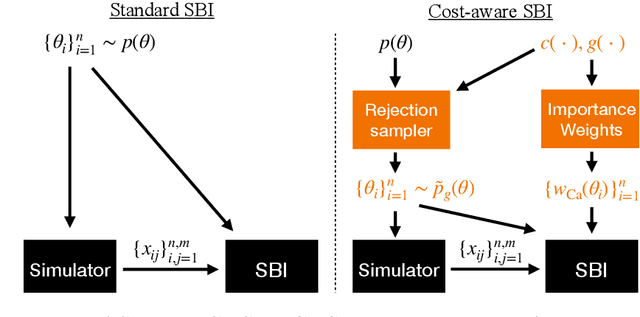

Simulation-based inference (SBI) is the preferred framework for estimating parameters of intractable models in science and engineering. A significant challenge in this context is the large computational cost of simulating data from complex models, and the fact that this cost often depends on parameter values. We therefore propose \textit{cost-aware SBI methods} which can significantly reduce the cost of existing sampling-based SBI methods, such as neural SBI and approximate Bayesian computation. This is achieved through a combination of rejection and self-normalised importance sampling, which significantly reduces the number of expensive simulations needed. Our approach is studied extensively on models from epidemiology to telecommunications engineering, where we obtain significant reductions in the overall cost of inference.
Practical Equivariances via Relational Conditional Neural Processes
Jun 19, 2023



Conditional Neural Processes (CNPs) are a class of metalearning models popular for combining the runtime efficiency of amortized inference with reliable uncertainty quantification. Many relevant machine learning tasks, such as spatio-temporal modeling, Bayesian Optimization and continuous control, contain equivariances -- for example to translation -- which the model can exploit for maximal performance. However, prior attempts to include equivariances in CNPs do not scale effectively beyond two input dimensions. In this work, we propose Relational Conditional Neural Processes (RCNPs), an effective approach to incorporate equivariances into any neural process model. Our proposed method extends the applicability and impact of equivariant neural processes to higher dimensions. We empirically demonstrate the competitive performance of RCNPs on a large array of tasks naturally containing equivariances.
Learning Robust Statistics for Simulation-based Inference under Model Misspecification
May 25, 2023



Simulation-based inference (SBI) methods such as approximate Bayesian computation (ABC), synthetic likelihood, and neural posterior estimation (NPE) rely on simulating statistics to infer parameters of intractable likelihood models. However, such methods are known to yield untrustworthy and misleading inference outcomes under model misspecification, thus hindering their widespread applicability. In this work, we propose the first general approach to handle model misspecification that works across different classes of SBI methods. Leveraging the fact that the choice of statistics determines the degree of misspecification in SBI, we introduce a regularized loss function that penalises those statistics that increase the mismatch between the data and the model. Taking NPE and ABC as use cases, we demonstrate the superior performance of our method on high-dimensional time-series models that are artificially misspecified. We also apply our method to real data from the field of radio propagation where the model is known to be misspecified. We show empirically that the method yields robust inference in misspecified scenarios, whilst still being accurate when the model is well-specified.