 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeNet: Text-to-Network for Compact Policy Synthesis
Jan 22, 2026Robots that follow natural-language instructions often either plan at a high level using hand-designed interfaces or rely on large end-to-end models that are difficult to deploy for real-time control. We propose TeNet (Text-to-Network), a framework for instantiating compact, task-specific robot policies directly from natural language descriptions. TeNet conditions a hypernetwork on text embeddings produced by a pretrained large language model (LLM) to generate a fully executable policy, which then operates solely on low-dimensional state inputs at high control frequencies. By using the language only once at the policy instantiation time, TeNet inherits the general knowledge and paraphrasing robustness of pretrained LLMs while remaining lightweight and efficient at execution time. To improve generalization, we optionally ground language in behavior during training by aligning text embeddings with demonstrated actions, while requiring no demonstrations at inference time. Experiments on MuJoCo and Meta-World benchmarks show that TeNet produces policies that are orders of magnitude smaller than sequence-based baselines, while achieving strong performance in both multi-task and meta-learning settings and supporting high-frequency control. These results show that text-conditioned hypernetworks offer a practical way to build compact, language-driven controllers for ressource-constrained robot control tasks with real-time requirements.
MoDeSuite: Robot Learning Task Suite for Benchmarking Mobile Manipulation with Deformable Objects
Jul 29, 2025Mobile manipulation is a critical capability for robots operating in diverse, real-world environments. However, manipulating deformable objects and materials remains a major challenge for existing robot learning algorithms. While various benchmarks have been proposed to evaluate manipulation strategies with rigid objects, there is still a notable lack of standardized benchmarks that address mobile manipulation tasks involving deformable objects. To address this gap, we introduce MoDeSuite, the first Mobile Manipulation Deformable Object task suite, designed specifically for robot learning. MoDeSuite consists of eight distinct mobile manipulation tasks covering both elastic objects and deformable objects, each presenting a unique challenge inspired by real-world robot applications. Success in these tasks requires effective collaboration between the robot's base and manipulator, as well as the ability to exploit the deformability of the objects. To evaluate and demonstrate the use of the proposed benchmark, we train two state-of-the-art reinforcement learning algorithms and two imitation learning algorithms, highlighting the difficulties encountered and showing their performance in simulation. Furthermore, we demonstrate the practical relevance of the suite by deploying the trained policies directly into the real world with the Spot robot, showcasing the potential for sim-to-real transfer. We expect that MoDeSuite will open a novel research domain in mobile manipulation involving deformable objects. Find more details, code, and videos at https://sites.google.com/view/modesuite/home.
Learning Transparent Reward Models via Unsupervised Feature Selection
Oct 24, 2024In complex real-world tasks such as robotic manipulation and autonomous driving, collecting expert demonstrations is often more straightforward than specifying precise learning objectives and task descriptions. Learning from expert data can be achieved through behavioral cloning or by learning a reward function, i.e., inverse reinforcement learning. The latter allows for training with additional data outside the training distribution, guided by the inferred reward function. We propose a novel approach to construct compact and transparent reward models from automatically selected state features. These inferred rewards have an explicit form and enable the learning of policies that closely match expert behavior by training standard reinforcement learning algorithms from scratch. We validate our method's performance in various robotic environments with continuous and high-dimensional state spaces. Webpage: \url{https://sites.google.com/view/transparent-reward}.
Practical Equivariances via Relational Conditional Neural Processes
Jun 19, 2023



Conditional Neural Processes (CNPs) are a class of metalearning models popular for combining the runtime efficiency of amortized inference with reliable uncertainty quantification. Many relevant machine learning tasks, such as spatio-temporal modeling, Bayesian Optimization and continuous control, contain equivariances -- for example to translation -- which the model can exploit for maximal performance. However, prior attempts to include equivariances in CNPs do not scale effectively beyond two input dimensions. In this work, we propose Relational Conditional Neural Processes (RCNPs), an effective approach to incorporate equivariances into any neural process model. Our proposed method extends the applicability and impact of equivariant neural processes to higher dimensions. We empirically demonstrate the competitive performance of RCNPs on a large array of tasks naturally containing equivariances.
Conditional Mutual Information for Disentangled Representations in Reinforcement Learning
May 23, 2023



Reinforcement Learning (RL) environments can produce training data with spurious correlations between features due to the amount of training data or its limited feature coverage. This can lead to RL agents encoding these misleading correlations in their latent representation, preventing the agent from generalising if the correlation changes within the environment or when deployed in the real world. Disentangled representations can improve robustness, but existing disentanglement techniques that minimise mutual information between features require independent features, thus they cannot disentangle correlated features. We propose an auxiliary task for RL algorithms that learns a disentangled representation of high-dimensional observations with correlated features by minimising the conditional mutual information between features in the representation. We demonstrate experimentally, using continuous control tasks, that our approach improves generalisation under correlation shifts, as well as improving the training performance of RL algorithms in the presence of correlated features.
Co-Imitation: Learning Design and Behaviour by Imitation
Sep 02, 2022



The co-adaptation of robots has been a long-standing research endeavour with the goal of adapting both body and behaviour of a system for a given task, inspired by the natural evolution of animals. Co-adaptation has the potential to eliminate costly manual hardware engineering as well as improve the performance of systems. The standard approach to co-adaptation is to use a reward function for optimizing behaviour and morphology. However, defining and constructing such reward functions is notoriously difficult and often a significant engineering effort. This paper introduces a new viewpoint on the co-adaptation problem, which we call co-imitation: finding a morphology and a policy that allow an imitator to closely match the behaviour of a demonstrator. To this end we propose a co-imitation methodology for adapting behaviour and morphology by matching state distributions of the demonstrator. Specifically, we focus on the challenging scenario with mismatched state- and action-spaces between both agents. We find that co-imitation increases behaviour similarity across a variety of tasks and settings, and demonstrate co-imitation by transferring human walking, jogging and kicking skills onto a simulated humanoid.
What Robot do I Need? Fast Co-Adaptation of Morphology and Control using Graph Neural Networks
Nov 03, 2021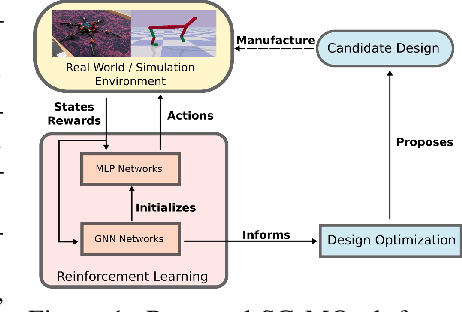
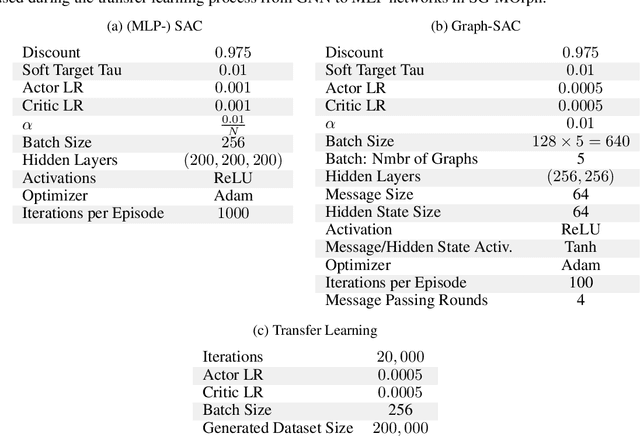
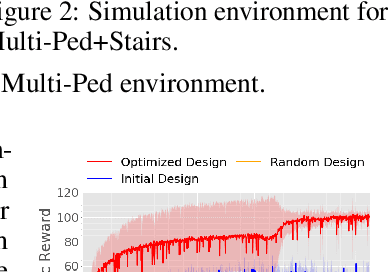
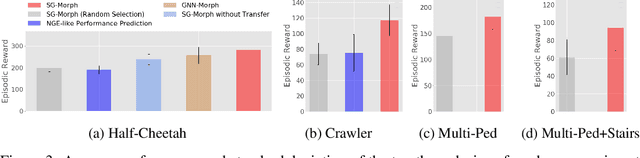
The co-adaptation of robot morphology and behaviour becomes increasingly important with the advent of fast 3D-manufacturing methods and efficient deep reinforcement learning algorithms. A major challenge for the application of co-adaptation methods to the real world is the simulation-to-reality-gap due to model and simulation inaccuracies. However, prior work focuses primarily on the study of evolutionary adaptation of morphologies exploiting analytical models and (differentiable) simulators with large population sizes, neglecting the existence of the simulation-to-reality-gap and the cost of manufacturing cycles in the real world. This paper presents a new approach combining classic high-frequency deep neural networks with computational expensive Graph Neural Networks for the data-efficient co-adaptation of agents with varying numbers of degrees-of-freedom. Evaluations in simulation show that the new method can co-adapt agents within such a limited number of production cycles by efficiently combining design optimization with offline reinforcement learning, that it allows for the direct application to real-world co-adaptation tasks in future work
Residual Learning from Demonstration
Aug 18, 2020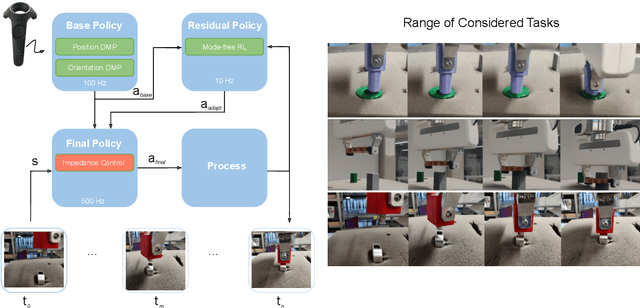
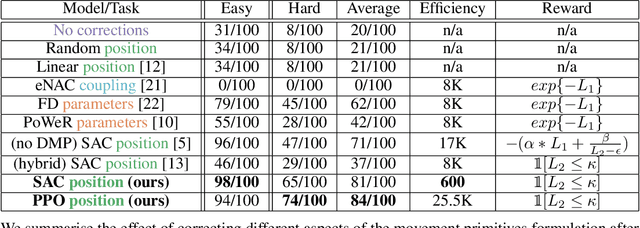
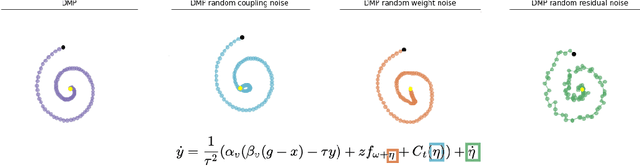
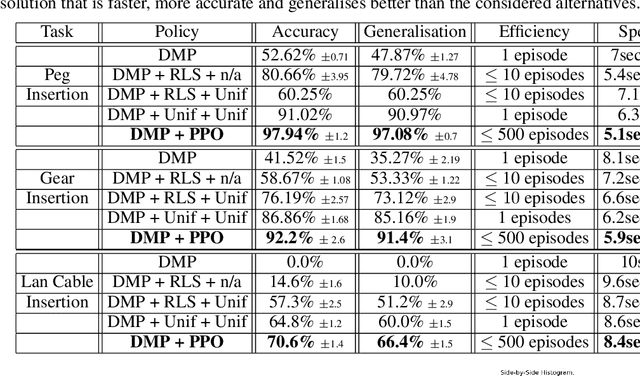
Contacts and friction are inherent to nearly all robotic manipulation tasks. Through the motor skill of insertion, we study how robots can learn to cope when these attributes play a salient role. In this work we propose residual learning from demonstration (rLfD), a framework that combines dynamic movement primitives (DMP) that rely on behavioural cloning with a reinforcement learning (RL) based residual correction policy. The proposed solution is applied directly in task space and operates on the full pose of the robot. We show that rLfD outperforms alternatives and improves the generalisation abilities of DMPs. We evaluate this approach by training an agent to successfully perform both simulated and real world insertions of pegs, gears and plugs into respective sockets.
Improved Exploration through Latent Trajectory Optimization in Deep Deterministic Policy Gradient
Nov 15, 2019

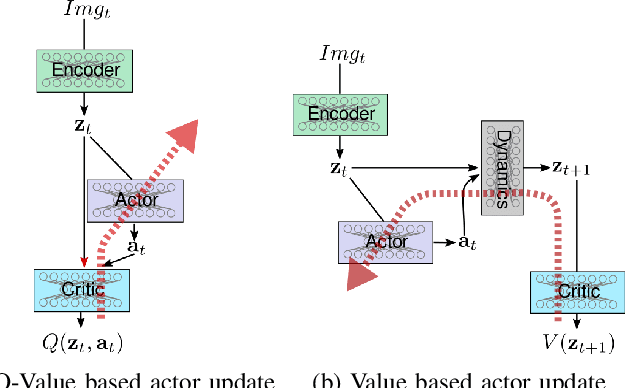
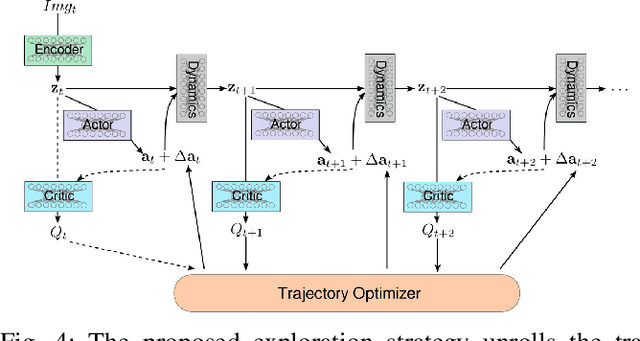
Model-free reinforcement learning algorithms such as Deep Deterministic Policy Gradient (DDPG) often require additional exploration strategies, especially if the actor is of deterministic nature. This work evaluates the use of model-based trajectory optimization methods used for exploration in Deep Deterministic Policy Gradient when trained on a latent image embedding. In addition, an extension of DDPG is derived using a value function as critic, making use of a learned deep dynamics model to compute the policy gradient. This approach leads to a symbiotic relationship between the deep reinforcement learning algorithm and the latent trajectory optimizer. The trajectory optimizer benefits from the critic learned by the RL algorithm and the latter from the enhanced exploration generated by the planner. The developed methods are evaluated on two continuous control tasks, one in simulation and one in the real world. In particular, a Baxter robot is trained to perform an insertion task, while only receiving sparse rewards and images as observations from the environment.
Data-efficient Co-Adaptation of Morphology and Behaviour with Deep Reinforcement Learning
Nov 15, 2019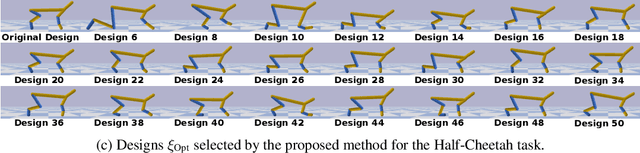

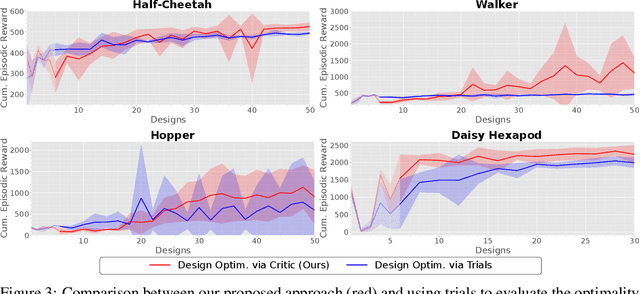

Humans and animals are capable of quickly learning new behaviours to solve new tasks. Yet, we often forget that they also rely on a highly specialized morphology that co-adapted with motor control throughout thousands of years. Although compelling, the idea of co-adapting morphology and behaviours in robots is often unfeasible because of the long manufacturing times, and the need to re-design an appropriate controller for each morphology. In this paper, we propose a novel approach to automatically and efficiently co-adapt a robot morphology and its controller. Our approach is based on recent advances in deep reinforcement learning, and specifically the soft actor critic algorithm. Key to our approach is the possibility of leveraging previously tested morphologies and behaviors to estimate the performance of new candidate morphologies. As such, we can make full use of the information available for making more informed decisions, with the ultimate goal of achieving a more data-efficient co-adaptation (i.e., reducing the number of morphologies and behaviors tested). Simulated experiments show that our approach requires drastically less design prototypes to find good morphology-behaviour combinations, making this method particularly suitable for future co-adaptation of robot designs in the real world.