 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkill-aware Mutual Information Optimisation for Generalisation in Reinforcement Learning
Jun 07, 2024



Meta-Reinforcement Learning (Meta-RL) agents can struggle to operate across tasks with varying environmental features that require different optimal skills (i.e., different modes of behaviours). Using context encoders based on contrastive learning to enhance the generalisability of Meta-RL agents is now widely studied but faces challenges such as the requirement for a large sample size, also referred to as the $\log$-$K$ curse. To improve RL generalisation to different tasks, we first introduce Skill-aware Mutual Information (SaMI), an optimisation objective that aids in distinguishing context embeddings according to skills, thereby equipping RL agents with the ability to identify and execute different skills across tasks. We then propose Skill-aware Noise Contrastive Estimation (SaNCE), a $K$-sample estimator used to optimise the SaMI objective. We provide a framework for equipping an RL agent with SaNCE in practice and conduct experimental validation on modified MuJoCo and Panda-gym benchmarks. We empirically find that RL agents that learn by maximising SaMI achieve substantially improved zero-shot generalisation to unseen tasks. Additionally, the context encoder equipped with SaNCE demonstrates greater robustness to reductions in the number of available samples, thus possessing the potential to overcome the $\log$-$K$ curse.
Multi-view Disentanglement for Reinforcement Learning with Multiple Cameras
Apr 22, 2024The performance of image-based Reinforcement Learning (RL) agents can vary depending on the position of the camera used to capture the images. Training on multiple cameras simultaneously, including a first-person egocentric camera, can leverage information from different camera perspectives to improve the performance of RL. However, hardware constraints may limit the availability of multiple cameras in real-world deployment. Additionally, cameras may become damaged in the real-world preventing access to all cameras that were used during training. To overcome these hardware constraints, we propose Multi-View Disentanglement (MVD), which uses multiple cameras to learn a policy that achieves zero-shot generalisation to any single camera from the training set. Our approach is a self-supervised auxiliary task for RL that learns a disentangled representation from multiple cameras, with a shared representation that is aligned across all cameras to allow generalisation to a single camera, and a private representation that is camera-specific. We show experimentally that an RL agent trained on a single third-person camera is unable to learn an optimal policy in many control tasks; but, our approach, benefiting from multiple cameras during training, is able to solve the task using only the same single third-person camera.
Conditional Mutual Information for Disentangled Representations in Reinforcement Learning
May 23, 2023



Reinforcement Learning (RL) environments can produce training data with spurious correlations between features due to the amount of training data or its limited feature coverage. This can lead to RL agents encoding these misleading correlations in their latent representation, preventing the agent from generalising if the correlation changes within the environment or when deployed in the real world. Disentangled representations can improve robustness, but existing disentanglement techniques that minimise mutual information between features require independent features, thus they cannot disentangle correlated features. We propose an auxiliary task for RL algorithms that learns a disentangled representation of high-dimensional observations with correlated features by minimising the conditional mutual information between features in the representation. We demonstrate experimentally, using continuous control tasks, that our approach improves generalisation under correlation shifts, as well as improving the training performance of RL algorithms in the presence of correlated features.
Deep Reinforcement Learning for Multi-Agent Interaction
Aug 02, 2022The development of autonomous agents which can interact with other agents to accomplish a given task is a core area of research in artificial intelligence and machine learning. Towards this goal, the Autonomous Agents Research Group develops novel machine learning algorithms for autonomous systems control, with a specific focus on deep reinforcement learning and multi-agent reinforcement learning. Research problems include scalable learning of coordinated agent policies and inter-agent communication; reasoning about the behaviours, goals, and composition of other agents from limited observations; and sample-efficient learning based on intrinsic motivation, curriculum learning, causal inference, and representation learning. This article provides a broad overview of the ongoing research portfolio of the group and discusses open problems for future directions.
Temporal Disentanglement of Representations for Improved Generalisation in Reinforcement Learning
Jul 12, 2022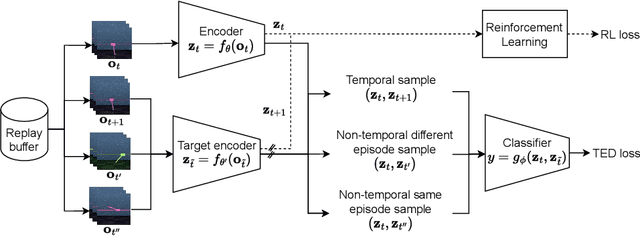

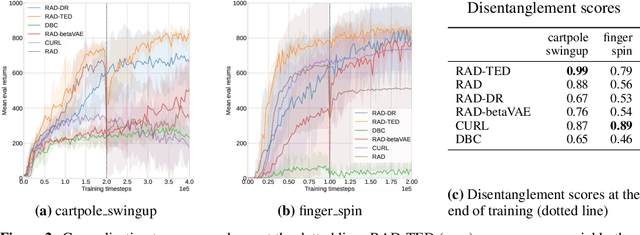
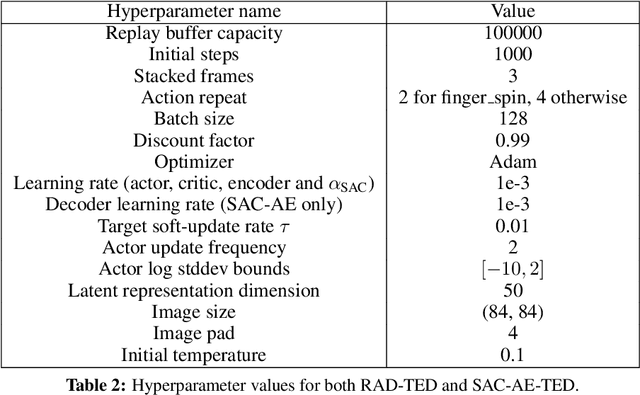
In real-world robotics applications, Reinforcement Learning (RL) agents are often unable to generalise to environment variations that were not observed during training. This issue is intensified for image-based RL where a change in one variable, such as the background colour, can change many pixels in the image, and in turn can change all values in the agent's internal representation of the image. To learn more robust representations, we introduce TEmporal Disentanglement (TED), a self-supervised auxiliary task that leads to disentangled representations using the sequential nature of RL observations. We find empirically that RL algorithms with TED as an auxiliary task adapt more quickly to changes in environment variables with continued training compared to state-of-the-art representation learning methods. Due to the disentangled structure of the representation, we also find that policies trained with TED generalise better to unseen values of variables irrelevant to the task (e.g. background colour) as well as unseen values of variables that affect the optimal policy (e.g. goal positions).