 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding deep neural networks through the lens of their non-linearity
Oct 17, 2023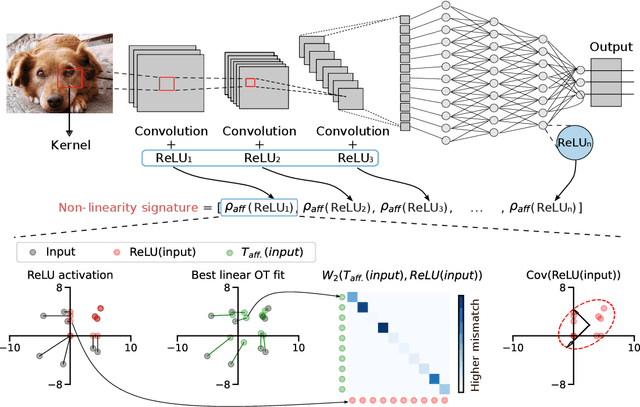
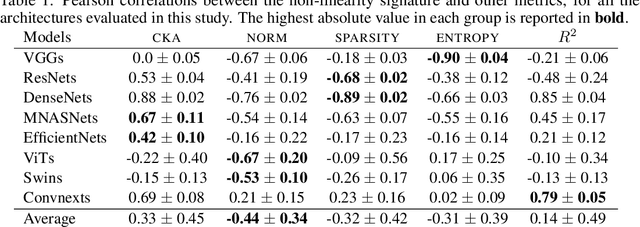
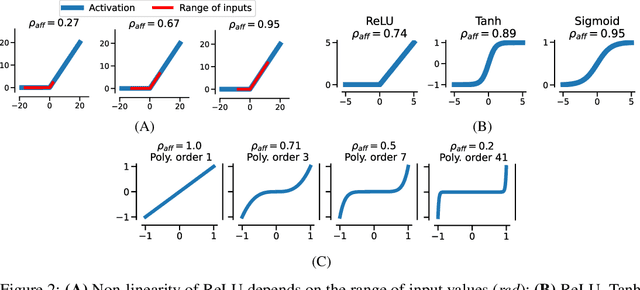
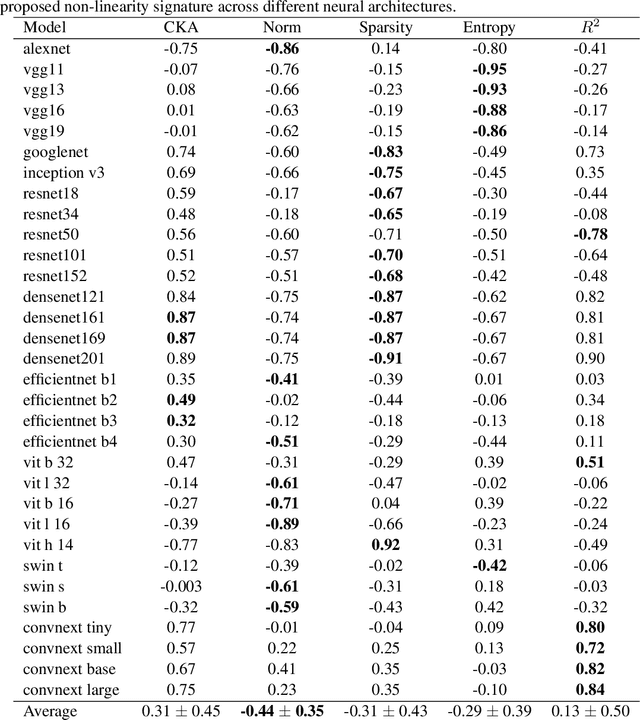
The remarkable success of deep neural networks (DNN) is often attributed to their high expressive power and their ability to approximate functions of arbitrary complexity. Indeed, DNNs are highly non-linear models, and activation functions introduced into them are largely responsible for this. While many works studied the expressive power of DNNs through the lens of their approximation capabilities, quantifying the non-linearity of DNNs or of individual activation functions remains an open problem. In this paper, we propose the first theoretically sound solution to track non-linearity propagation in deep neural networks with a specific focus on computer vision applications. Our proposed affinity score allows us to gain insights into the inner workings of a wide range of different architectures and learning paradigms. We provide extensive experimental results that highlight the practical utility of the proposed affinity score and its potential for long-reaching applications.
Beyond invariant representation learning: linearly alignable latent spaces for efficient closed-form domain adaptation
May 12, 2023



Optimal transport (OT) is a powerful geometric tool used to compare and align probability measures following the least effort principle. Among many successful applications of OT in machine learning (ML), domain adaptation (DA) -- a field of study where the goal is to transfer a classifier from one labelled domain to another similar, yet different unlabelled or scarcely labelled domain -- has been historically among the most investigated ones. This success is due to the ability of OT to provide both a meaningful discrepancy measure to assess the similarity of two domains' distributions and a mapping that can project source domain data onto the target one. In this paper, we propose a principally new OT-based approach applied to DA that uses the closed-form solution of the OT problem given by an affine mapping and learns an embedding space for which this solution is optimal and computationally less complex. We show that our approach works in both homogeneous and heterogeneous DA settings and outperforms or is on par with other famous baselines based on both traditional OT and OT in incomparable spaces. Furthermore, we show that our proposed method vastly reduces computational complexity.
Co-Imitation: Learning Design and Behaviour by Imitation
Sep 02, 2022



The co-adaptation of robots has been a long-standing research endeavour with the goal of adapting both body and behaviour of a system for a given task, inspired by the natural evolution of animals. Co-adaptation has the potential to eliminate costly manual hardware engineering as well as improve the performance of systems. The standard approach to co-adaptation is to use a reward function for optimizing behaviour and morphology. However, defining and constructing such reward functions is notoriously difficult and often a significant engineering effort. This paper introduces a new viewpoint on the co-adaptation problem, which we call co-imitation: finding a morphology and a policy that allow an imitator to closely match the behaviour of a demonstrator. To this end we propose a co-imitation methodology for adapting behaviour and morphology by matching state distributions of the demonstrator. Specifically, we focus on the challenging scenario with mismatched state- and action-spaces between both agents. We find that co-imitation increases behaviour similarity across a variety of tasks and settings, and demonstrate co-imitation by transferring human walking, jogging and kicking skills onto a simulated humanoid.
Online vs. Offline Adaptive Domain Randomization Benchmark
Jun 29, 2022


Physics simulators have shown great promise for conveniently learning reinforcement learning policies in safe, unconstrained environments. However, transferring the acquired knowledge to the real world can be challenging due to the reality gap. To this end, several methods have been recently proposed to automatically tune simulator parameters with posterior distributions given real data, for use with domain randomization at training time. These approaches have been shown to work for various robotic tasks under different settings and assumptions. Nevertheless, existing literature lacks a thorough comparison of existing adaptive domain randomization methods with respect to transfer performance and real-data efficiency. In this work, we present an open benchmark for both offline and online methods (SimOpt, BayRn, DROID, DROPO), to shed light on which are most suitable for each setting and task at hand. We found that online methods are limited by the quality of the currently learned policy for the next iteration, while offline methods may sometimes fail when replaying trajectories in simulation with open-loop commands. The code used will be released at https://github.com/gabrieletiboni/adr-benchmark.
Training and Evaluation of Deep Policies using Reinforcement Learning and Generative Models
Apr 18, 2022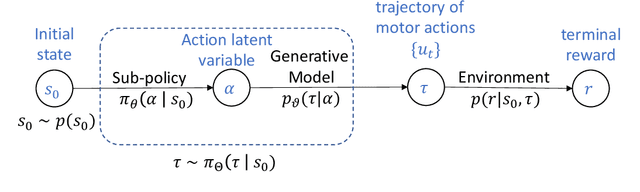
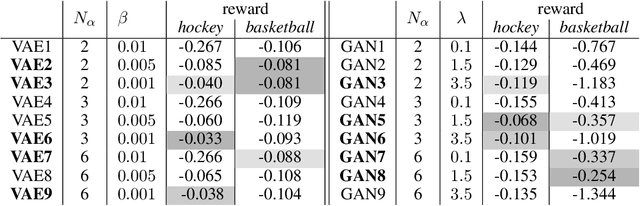
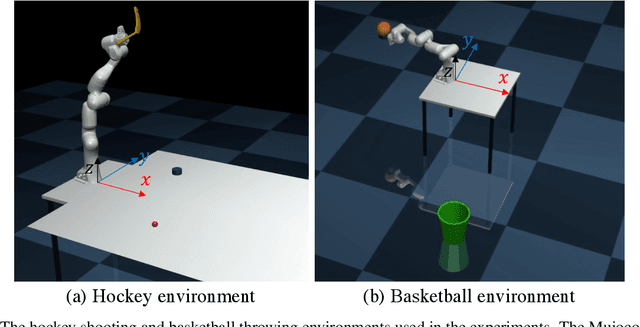
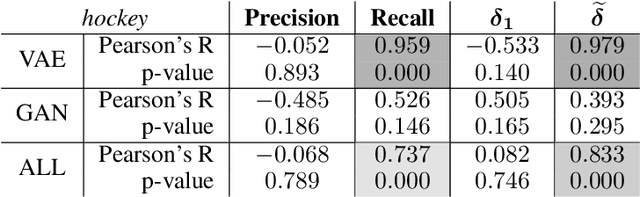
We present a data-efficient framework for solving sequential decision-making problems which exploits the combination of reinforcement learning (RL) and latent variable generative models. The framework, called GenRL, trains deep policies by introducing an action latent variable such that the feed-forward policy search can be divided into two parts: (i) training a sub-policy that outputs a distribution over the action latent variable given a state of the system, and (ii) unsupervised training of a generative model that outputs a sequence of motor actions conditioned on the latent action variable. GenRL enables safe exploration and alleviates the data-inefficiency problem as it exploits prior knowledge about valid sequences of motor actions. Moreover, we provide a set of measures for evaluation of generative models such that we are able to predict the performance of the RL policy training prior to the actual training on a physical robot. We experimentally determine the characteristics of generative models that have most influence on the performance of the final policy training on two robotics tasks: shooting a hockey puck and throwing a basketball. Furthermore, we empirically demonstrate that GenRL is the only method which can safely and efficiently solve the robotics tasks compared to two state-of-the-art RL methods.
SafeAPT: Safe Simulation-to-Real Robot Learning using Diverse Policies Learned in Simulation
Jan 27, 2022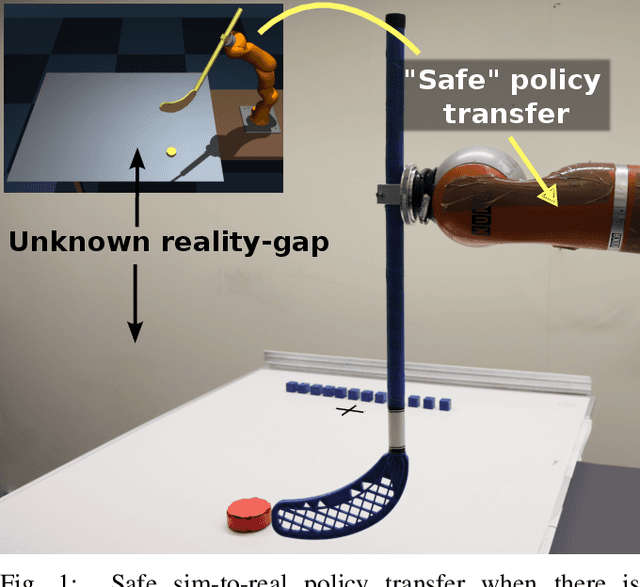

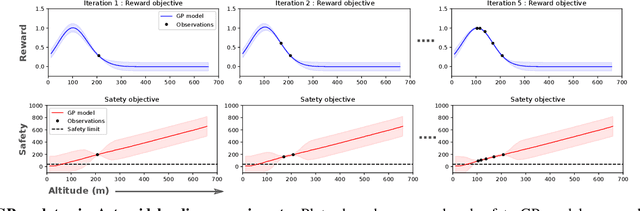

The framework of Simulation-to-real learning, i.e, learning policies in simulation and transferring those policies to the real world is one of the most promising approaches towards data-efficient learning in robotics. However, due to the inevitable reality gap between the simulation and the real world, a policy learned in the simulation may not always generate a safe behaviour on the real robot. As a result, during adaptation of the policy in the real world, the robot may damage itself or cause harm to its surroundings. In this work, we introduce a novel learning algorithm called SafeAPT that leverages a diverse repertoire of policies evolved in the simulation and transfers the most promising safe policy to the real robot through episodic interaction. To achieve this, SafeAPT iteratively learns a probabilistic reward model as well as a safety model using real-world observations combined with simulated experiences as priors. Then, it performs Bayesian optimization on the repertoire with the reward model while maintaining the specified safety constraint using the safety model. SafeAPT allows a robot to adapt to a wide range of goals safely with the same repertoire of policies evolved in the simulation. We compare SafeAPT with several baselines, both in simulated and real robotic experiments and show that SafeAPT finds high-performance policies within a few minutes in the real world while minimizing safety violations during the interactions.
DROPO: Sim-to-Real Transfer with Offline Domain Randomization
Jan 20, 2022In recent years, domain randomization has gained a lot of traction as a method for sim-to-real transfer of reinforcement learning policies in robotic manipulation; however, finding optimal randomization distributions can be difficult. In this paper, we introduce DROPO, a novel method for estimating domain randomization distributions for safe sim-to-real transfer. Unlike prior work, DROPO only requires a limited, precollected offline dataset of trajectories, and explicitly models parameter uncertainty to match real data. We demonstrate that DROPO is capable of recovering dynamic parameter distributions in simulation and finding a distribution capable of compensating for an unmodelled phenomenon. We also evaluate the method in two zero-shot sim-to-real transfer scenarios, showing successful domain transfer and improved performance over prior methods.
Affine Transport for Sim-to-Real Domain Adaptation
May 25, 2021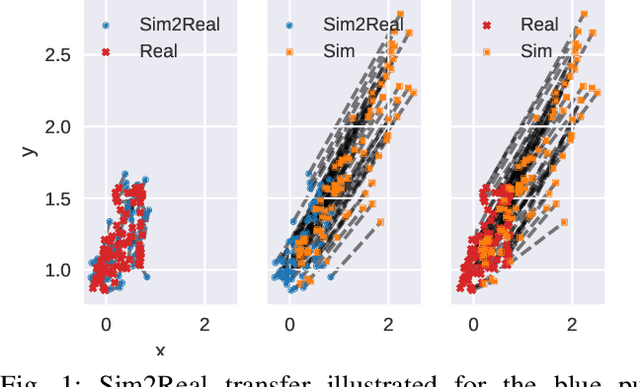

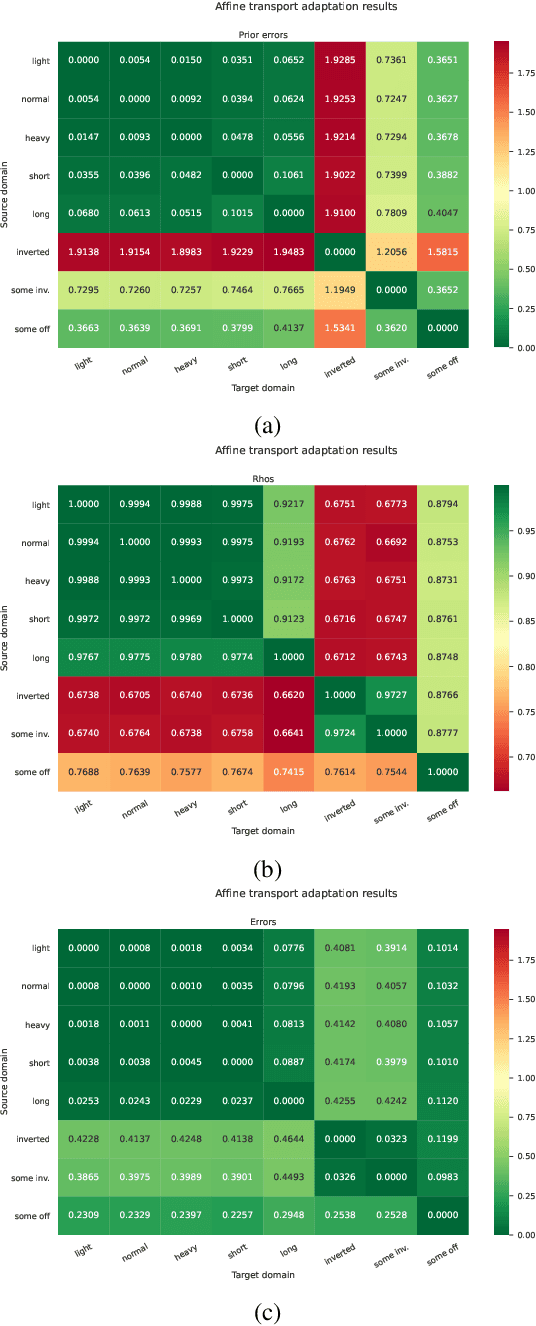
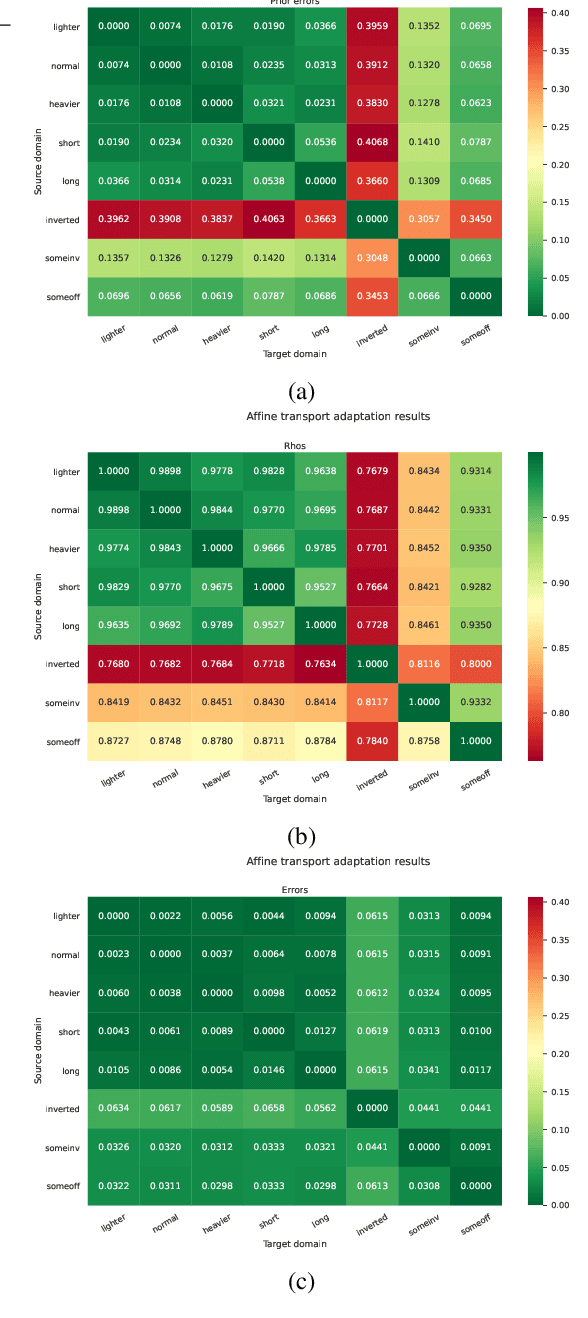
Sample-efficient domain adaptation is an open problem in robotics. In this paper, we present affine transport -- a variant of optimal transport, which models the mapping between state transition distributions between the source and target domains with an affine transformation. First, we derive the affine transport framework; then, we extend the basic framework with Procrustes alignment to model arbitrary affine transformations. We evaluate the method in a number of OpenAI Gym sim-to-sim experiments with simulation environments, as well as on a sim-to-real domain adaptation task of a robot hitting a hockeypuck such that it slides and stops at a target position. In each experiment, we evaluate the results when transferring between each pair of dynamics domains. The results show that affine transport can significantly reduce the model adaptation error in comparison to using the original, non-adapted dynamics model.
Domain Curiosity: Learning Efficient Data Collection Strategies for Domain Adaptation
Mar 12, 2021
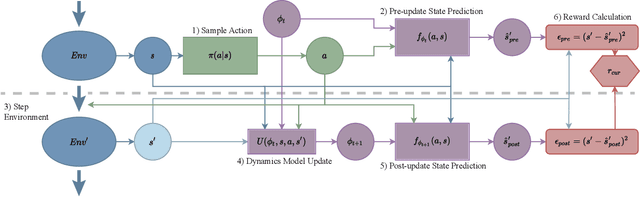
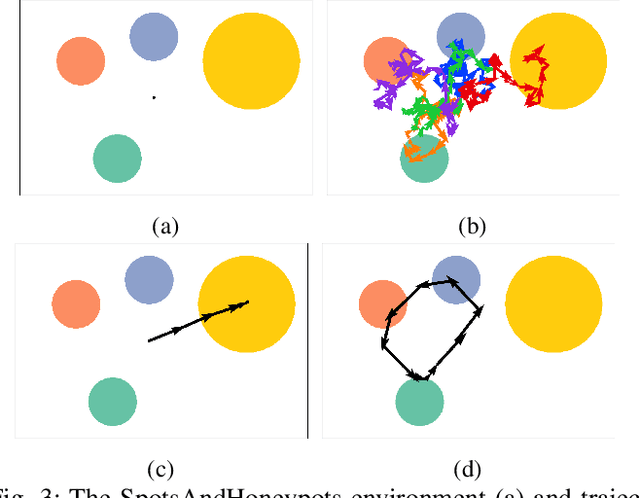
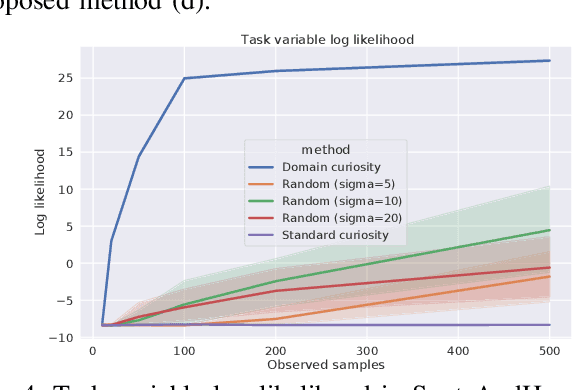
Domain adaptation is a common problem in robotics, with applications such as transferring policies from simulation to real world and lifelong learning. Performing such adaptation, however, requires informative data about the environment to be available during the adaptation. In this paper, we present domain curiosity -- a method of training exploratory policies that are explicitly optimized to provide data that allows a model to learn about the unknown aspects of the environment. In contrast to most curiosity methods, our approach explicitly rewards learning, which makes it robust to environment noise without sacrificing its ability to learn. We evaluate the proposed method by comparing how much a model can learn about environment dynamics given data collected by the proposed approach, compared to standard curious and random policies. The evaluation is performed using a toy environment, two simulated robot setups, and on a real-world haptic exploration task. The results show that the proposed method allows data-efficient and accurate estimation of dynamics.
Few-shot model-based adaptation in noisy conditions
Oct 16, 2020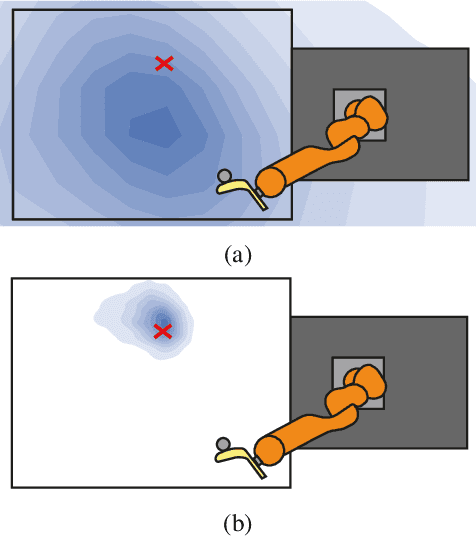



Few-shot adaptation is a challenging problem in the context of simulation-to-real transfer in robotics, requiring safe and informative data collection. In physical systems, additional challenge may be posed by domain noise, which is present in virtually all real-world applications. In this paper, we propose to perform few-shot adaptation of dynamics models in noisy conditions using an uncertainty-aware Kalman filter-based neural network architecture. We show that the proposed method, which explicitly addresses domain noise, improves few-shot adaptation error over a blackbox adaptation LSTM baseline, and over a model-free on-policy reinforcement learning approach, which tries to learn an adaptable and informative policy at the same time. The proposed method also allows for system analysis by analyzing hidden states of the model during and after adaptation.