 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeAPT: Safe Simulation-to-Real Robot Learning using Diverse Policies Learned in Simulation
Jan 27, 2022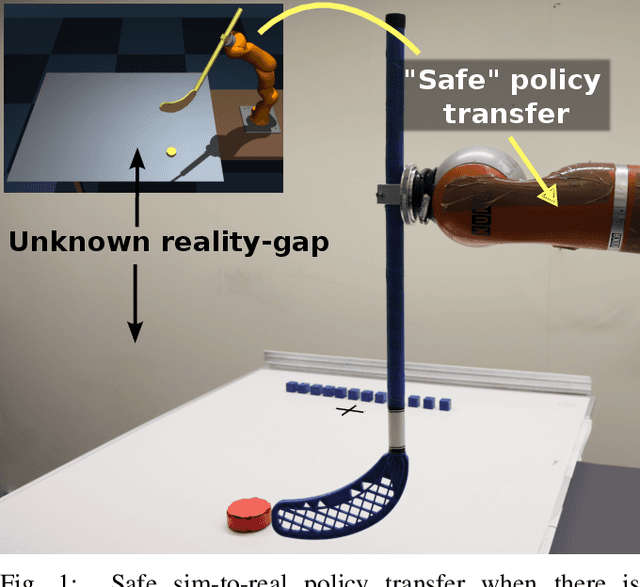

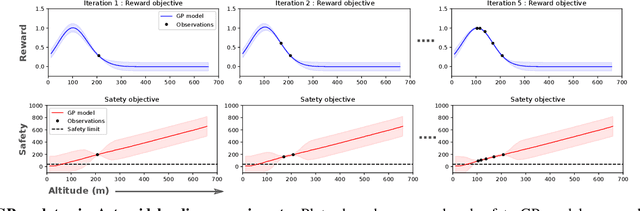

The framework of Simulation-to-real learning, i.e, learning policies in simulation and transferring those policies to the real world is one of the most promising approaches towards data-efficient learning in robotics. However, due to the inevitable reality gap between the simulation and the real world, a policy learned in the simulation may not always generate a safe behaviour on the real robot. As a result, during adaptation of the policy in the real world, the robot may damage itself or cause harm to its surroundings. In this work, we introduce a novel learning algorithm called SafeAPT that leverages a diverse repertoire of policies evolved in the simulation and transfers the most promising safe policy to the real robot through episodic interaction. To achieve this, SafeAPT iteratively learns a probabilistic reward model as well as a safety model using real-world observations combined with simulated experiences as priors. Then, it performs Bayesian optimization on the repertoire with the reward model while maintaining the specified safety constraint using the safety model. SafeAPT allows a robot to adapt to a wide range of goals safely with the same repertoire of policies evolved in the simulation. We compare SafeAPT with several baselines, both in simulated and real robotic experiments and show that SafeAPT finds high-performance policies within a few minutes in the real world while minimizing safety violations during the interactions.
Fast Online Adaptation in Robotics through Meta-Learning Embeddings of Simulated Priors
Mar 10, 2020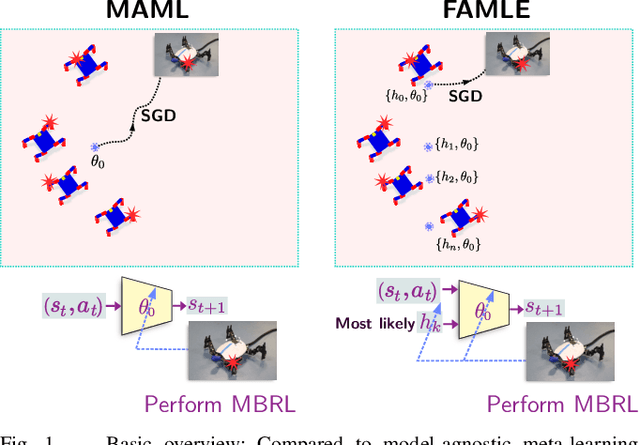
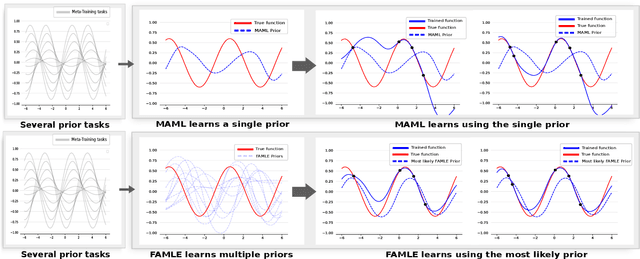
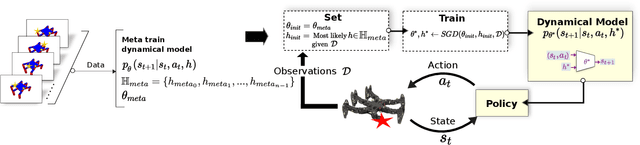
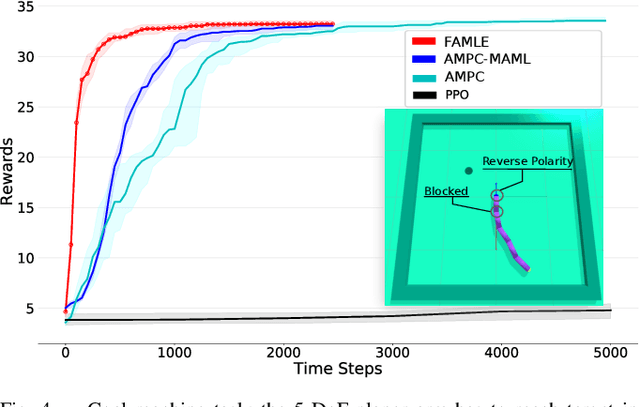
Meta-learning algorithms can accelerate the model-based reinforcement learning (MBRL) algorithms by finding an initial set of parameters for the dynamical model such that the model can be trained to match the actual dynamics of the system with only a few data-points. However, in the real world, a robot might encounter any situation starting from motor failures to finding itself in a rocky terrain where the dynamics of the robot can be significantly different from one another. In this paper, first, we show that when meta-training situations (the prior situations) have such diverse dynamics, using a single set of meta-trained parameters as a starting point still requires a large number of observations from the real system to learn a useful model of the dynamics. Second, we propose an algorithm called FAMLE that mitigates this limitation by meta-training several initial starting points (i.e., initial parameters) for training the model and allows the robot to select the most suitable starting point to adapt the model to the current situation with only a few gradient steps. We compare FAMLE to MBRL, MBRL with a meta-trained model with MAML, and model-free policy search algorithm PPO for various simulated and real robotic tasks, and show that FAMLE allows the robots to adapt to novel damages in significantly fewer time-steps than the baselines.
Adaptive Prior Selection for Repertoire-based Online Learning in Robotics
Jul 16, 2019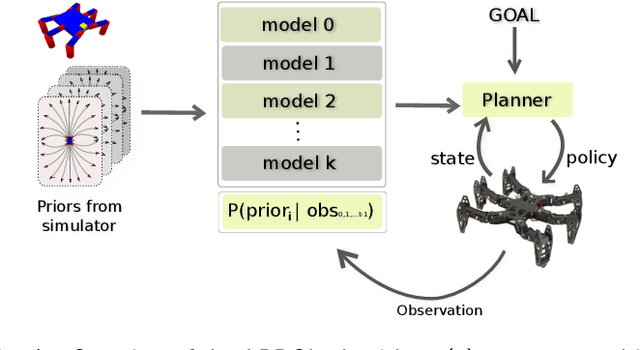
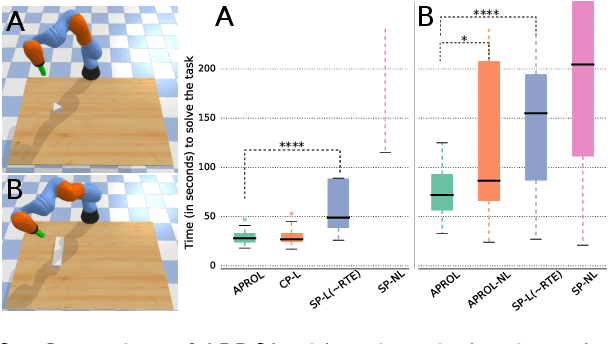
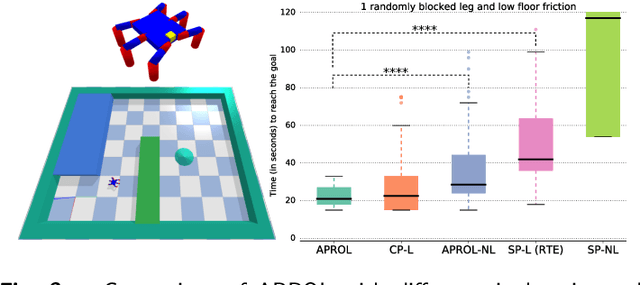

Among the data-efficient approaches for online adaptation in robotics (meta-learning, model-based reinforcement learning, etc.), repertoire-based learning (1) generates a large and diverse set policies in simulation that acts as a "reservoir" for future adaptations and (2) learns to pick online the best working policies according to the current situation (e.g., a damaged robot, a new object, etc.). Each of these policies performs a different task, for instance, walking in different directions; these policies are then sequenced with a planning algorithm to achieve the given task. In this paper, we relax the assumption of previous works that a single repertoire is enough for adaptation. Instead, we generate repertoires for many different situations (e.g., with a missing leg, on different floors, etc.) in simulation that act as priors for adaptation. Our main contribution is an algorithm, APROL (Adaptive Prior selection for Repertoire-based Online Learning) to plan the next action by incorporating these priors when the robot has no information about the current situation. We evaluate APROL on two simulated tasks: (1) pushing unknown objects of various shapes and sizes with a kuka arm and (2) a goal reaching task with a damaged hexapod robot. We compare with "Reset-free Trial and Error" (RTE) and various single repertoire-based baselines. The results show that APROL solves both tasks in less interaction time than the baselines. Additionally, we demonstrate APROL on a real, damaged hexapod that quickly learns compensatory policies to reach a goal by avoiding obstacle in the path.
Multi-objective Model-based Policy Search for Data-efficient Learning with Sparse Rewards
Oct 11, 2018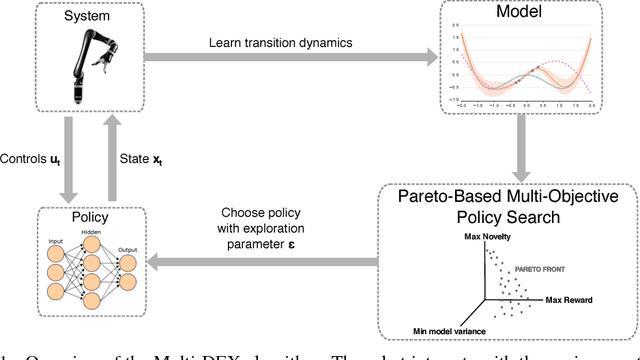
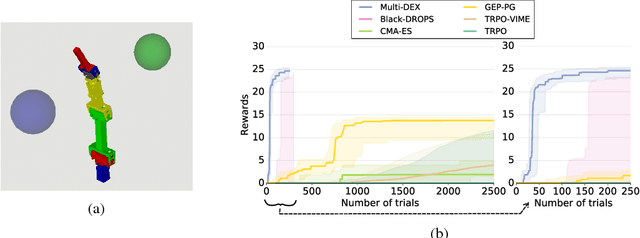
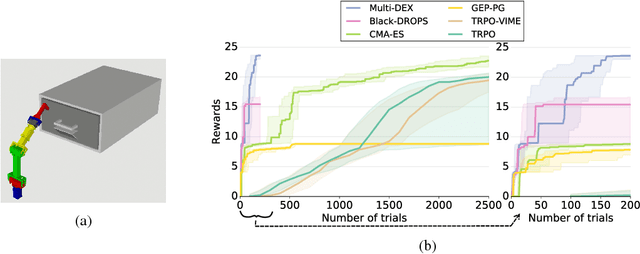
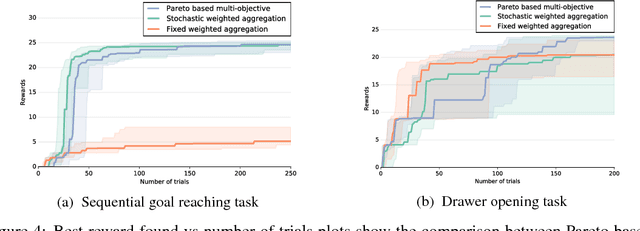
The most data-efficient algorithms for reinforcement learning in robotics are model-based policy search algorithms, which alternate between learning a dynamical model of the robot and optimizing a policy to maximize the expected return given the model and its uncertainties. However, the current algorithms lack an effective exploration strategy to deal with sparse or misleading reward scenarios: if they do not experience any state with a positive reward during the initial random exploration, it is very unlikely to solve the problem. Here, we propose a novel model-based policy search algorithm, Multi-DEX, that leverages a learned dynamical model to efficiently explore the task space and solve tasks with sparse rewards in a few episodes. To achieve this, we frame the policy search problem as a multi-objective, model-based policy optimization problem with three objectives: (1) generate maximally novel state trajectories, (2) maximize the expected return and (3) keep the system in state-space regions for which the model is as accurate as possible. We then optimize these objectives using a Pareto-based multi-objective optimization algorithm. The experiments show that Multi-DEX is able to solve sparse reward scenarios (with a simulated robotic arm) in much lower interaction time than VIME, TRPO, GEP-PG, CMA-ES and Black-DROPS.
Black-Box Data-efficient Policy Search for Robotics
Jul 22, 2017
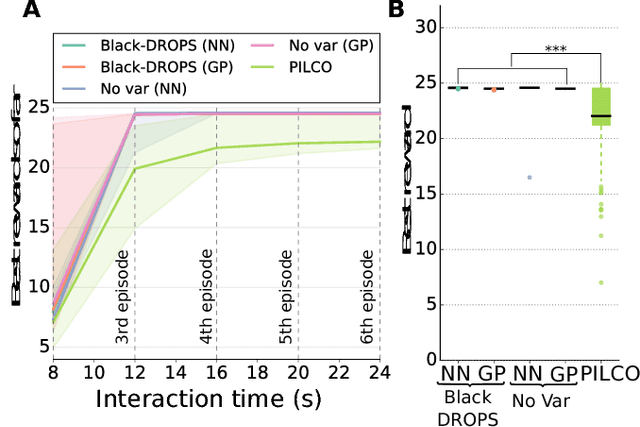
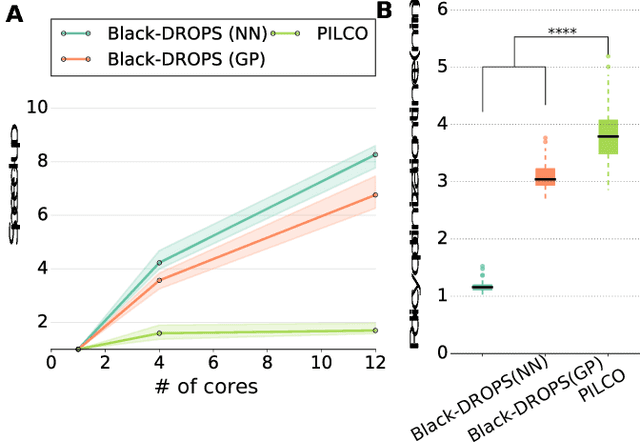
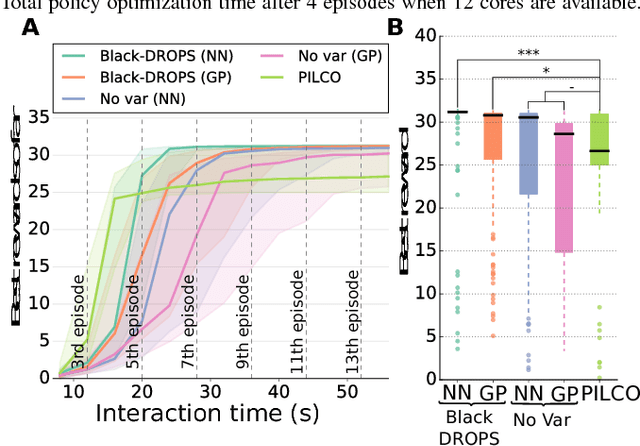
The most data-efficient algorithms for reinforcement learning (RL) in robotics are based on uncertain dynamical models: after each episode, they first learn a dynamical model of the robot, then they use an optimization algorithm to find a policy that maximizes the expected return given the model and its uncertainties. It is often believed that this optimization can be tractable only if analytical, gradient-based algorithms are used; however, these algorithms require using specific families of reward functions and policies, which greatly limits the flexibility of the overall approach. In this paper, we introduce a novel model-based RL algorithm, called Black-DROPS (Black-box Data-efficient RObot Policy Search) that: (1) does not impose any constraint on the reward function or the policy (they are treated as black-boxes), (2) is as data-efficient as the state-of-the-art algorithm for data-efficient RL in robotics, and (3) is as fast (or faster) than analytical approaches when several cores are available. The key idea is to replace the gradient-based optimization algorithm with a parallel, black-box algorithm that takes into account the model uncertainties. We demonstrate the performance of our new algorithm on two standard control benchmark problems (in simulation) and a low-cost robotic manipulator (with a real robot).