 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural-Symbolic Integration with Evolvable Policies
Jan 08, 2026Neural-Symbolic (NeSy) Artificial Intelligence has emerged as a promising approach for combining the learning capabilities of neural networks with the interpretable reasoning of symbolic systems. However, existing NeSy frameworks typically require either predefined symbolic policies or policies that are differentiable, limiting their applicability when domain expertise is unavailable or when policies are inherently non-differentiable. We propose a framework that addresses this limitation by enabling the concurrent learning of both non-differentiable symbolic policies and neural network weights through an evolutionary process. Our approach casts NeSy systems as organisms in a population that evolve through mutations (both symbolic rule additions and neural weight changes), with fitness-based selection guiding convergence toward hidden target policies. The framework extends the NEUROLOG architecture to make symbolic policies trainable, adapts Valiant's Evolvability framework to the NeSy context, and employs Machine Coaching semantics for mutable symbolic representations. Neural networks are trained through abductive reasoning from the symbolic component, eliminating differentiability requirements. Through extensive experimentation, we demonstrate that NeSy systems starting with empty policies and random neural weights can successfully approximate hidden non-differentiable target policies, achieving median correct performance approaching 100%. This work represents a step toward enabling NeSy research in domains where the acquisition of symbolic knowledge from experts is challenging or infeasible.
PEDESTRIAN: An Egocentric Vision Dataset for Obstacle Detection on Pavements
Dec 22, 2025Walking has always been a primary mode of transportation and is recognized as an essential activity for maintaining good health. Despite the need for safe walking conditions in urban environments, sidewalks are frequently obstructed by various obstacles that hinder free pedestrian movement. Any object obstructing a pedestrian's path can pose a safety hazard. The advancement of pervasive computing and egocentric vision techniques offers the potential to design systems that can automatically detect such obstacles in real time, thereby enhancing pedestrian safety. The development of effective and efficient identification algorithms relies on the availability of comprehensive and well-balanced datasets of egocentric data. In this work, we introduce the PEDESTRIAN dataset, comprising egocentric data for 29 different obstacles commonly found on urban sidewalks. A total of 340 videos were collected using mobile phone cameras, capturing a pedestrian's point of view. Additionally, we present the results of a series of experiments that involved training several state-of-the-art deep learning algorithms using the proposed dataset, which can be used as a benchmark for obstacle detection and recognition tasks. The dataset can be used for training pavement obstacle detectors to enhance the safety of pedestrians in urban areas.
Patch-Based Contrastive Learning and Memory Consolidation for Online Unsupervised Continual Learning
Sep 24, 2024We focus on a relatively unexplored learning paradigm known as {\em Online Unsupervised Continual Learning} (O-UCL), where an agent receives a non-stationary, unlabeled data stream and progressively learns to identify an increasing number of classes. This paradigm is designed to model real-world applications where encountering novelty is the norm, such as exploring a terrain with several unknown and time-varying entities. Unlike prior work in unsupervised, continual, or online learning, O-UCL combines all three areas into a single challenging and realistic learning paradigm. In this setting, agents are frequently evaluated and must aim to maintain the best possible representation at any point of the data stream, rather than at the end of pre-specified offline tasks. The proposed approach, called \textbf{P}atch-based \textbf{C}ontrastive learning and \textbf{M}emory \textbf{C}onsolidation (PCMC), builds a compositional understanding of data by identifying and clustering patch-level features. Embeddings for these patch-level features are extracted with an encoder trained via patch-based contrastive learning. PCMC incorporates new data into its distribution while avoiding catastrophic forgetting, and it consolidates memory examples during ``sleep" periods. We evaluate PCMC's performance on streams created from the ImageNet and Places365 datasets. Additionally, we explore various versions of the PCMC algorithm and compare its performance against several existing methods and simple baselines.
Towards Exploratory Quality Diversity Landscape Analysis
May 22, 2024This work is a preliminary study on using Exploratory Landscape Analysis (ELA) for Quality Diversity (QD) problems. We seek to understand whether ELA features can potentially be used to characterise QD problems paving the way for automating QD algorithm selection. Our results demonstrate that ELA features are affected by QD optimisation differently than random sampling, and more specifically, by the choice of variation operator, behaviour function, archive size and problem dimensionality.
Towards Continual Reinforcement Learning for Quadruped Robots
Nov 12, 2023Quadruped robots have emerged as an evolving technology that currently leverages simulators to develop a robust controller capable of functioning in the real-world without the need for further training. However, since it is impossible to predict all possible real-world situations, our research explores the possibility of enabling them to continue learning even after their deployment. To this end, we designed two continual learning scenarios, sequentially training the robot on different environments while simultaneously evaluating its performance across all of them. Our approach sheds light on the extent of both forward and backward skill transfer, as well as the degree to which the robot might forget previously acquired skills. By addressing these factors, we hope to enhance the adaptability and performance of quadruped robots in real-world scenarios.
Continual Learning on the Edge with TensorFlow Lite
May 05, 2021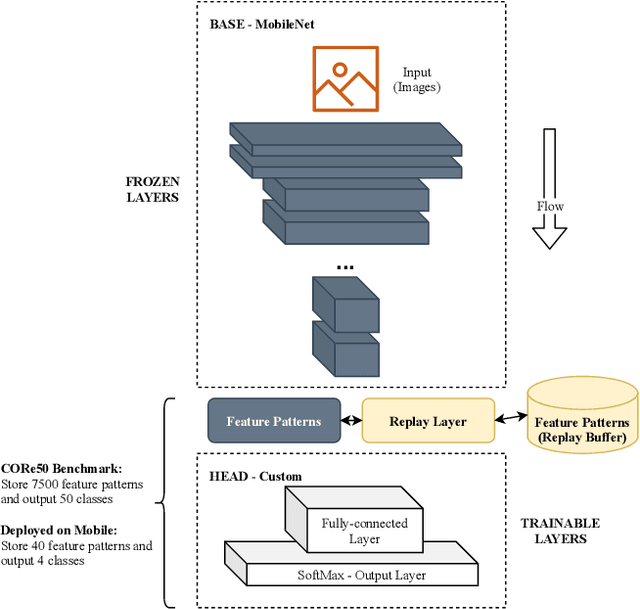
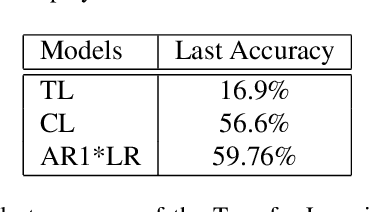
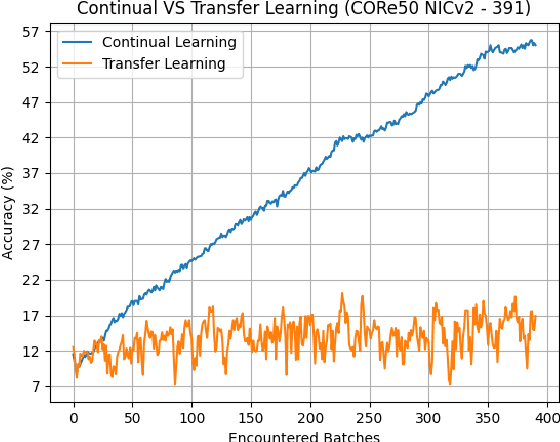
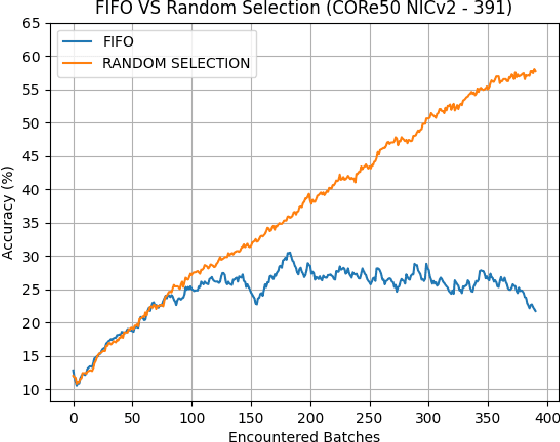
Deploying sophisticated deep learning models on embedded devices with the purpose of solving real-world problems is a struggle using today's technology. Privacy and data limitations, network connection issues, and the need for fast model adaptation are some of the challenges that constitute today's approaches unfit for many applications on the edge and make real-time on-device training a necessity. Google is currently working on tackling these challenges by embedding an experimental transfer learning API to their TensorFlow Lite, machine learning library. In this paper, we show that although transfer learning is a good first step for on-device model training, it suffers from catastrophic forgetting when faced with more realistic scenarios. We present this issue by testing a simple transfer learning model on the CORe50 benchmark as well as by demonstrating its limitations directly on an Android application we developed. In addition, we expand the TensorFlow Lite library to include continual learning capabilities, by integrating a simple replay approach into the head of the current transfer learning model. We test our continual learning model on the CORe50 benchmark to show that it tackles catastrophic forgetting, and we demonstrate its ability to continually learn, even under non-ideal conditions, using the application we developed. Finally, we open-source the code of our Android application to enable developers to integrate continual learning to their own smartphone applications, as well as to facilitate further development of continual learning functionality into the TensorFlow Lite environment.
Quality-Diversity Optimization: a novel branch of stochastic optimization
Dec 17, 2020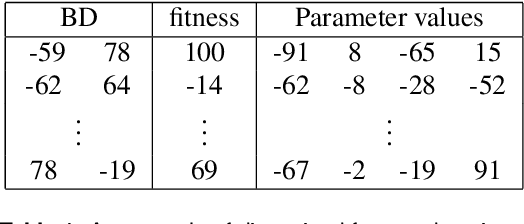
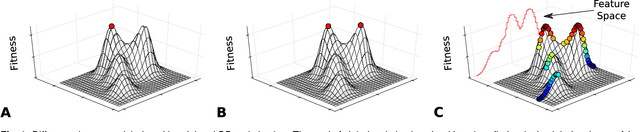
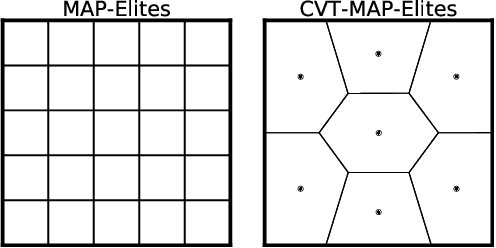
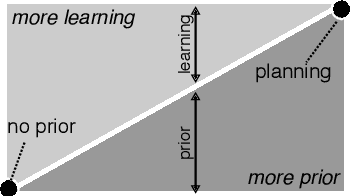
Traditional optimization algorithms search for a single global optimum that maximizes (or minimizes) the objective function. Multimodal optimization algorithms search for the highest peaks in the search space that can be more than one. Quality-Diversity algorithms are a recent addition to the evolutionary computation toolbox that do not only search for a single set of local optima, but instead try to illuminate the search space. In effect, they provide a holistic view of how high-performing solutions are distributed throughout a search space. The main differences with multimodal optimization algorithms are that (1) Quality-Diversity typically works in the behavioral space (or feature space), and not in the genotypic (or parameter) space, and (2) Quality-Diversity attempts to fill the whole behavior space, even if the niche is not a peak in the fitness landscape. In this chapter, we provide a gentle introduction to Quality-Diversity optimization, discuss the main representative algorithms, and the main current topics under consideration in the community. Throughout the chapter, we also discuss several successful applications of Quality-Diversity algorithms, including deep learning, robotics, and reinforcement learning.
A survey on policy search algorithms for learning robot controllers in a handful of trials
Aug 03, 2018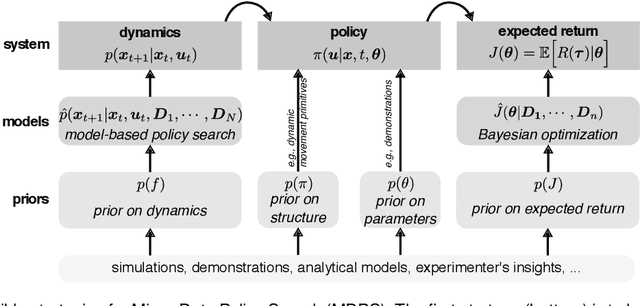
Most policy search algorithms require thousands of training episodes to find an effective policy, which is often infeasible with a physical robot. This survey article focuses on the extreme other end of the spectrum: how can a robot adapt with only a handful of trials (a dozen) and a few minutes? By analogy with the word "big-data", we refer to this challenge as "micro-data reinforcement learning". We show that a first strategy is to leverage prior knowledge on the policy structure (e.g., dynamic movement primitives), on the policy parameters (e.g., demonstrations), or on the dynamics (e.g., simulators). A second strategy is to create data-driven surrogate models of the expected reward (e.g., Bayesian optimization) or the dynamical model (e.g., model-based policy search), so that the policy optimizer queries the model instead of the real system. Overall, all successful micro-data algorithms combine these two strategies by varying the kind of model and prior knowledge. The current scientific challenges essentially revolve around scaling up to complex robots (e.g., humanoids), designing generic priors, and optimizing the computing time.
Discovering the Elite Hypervolume by Leveraging Interspecies Correlation
Apr 11, 2018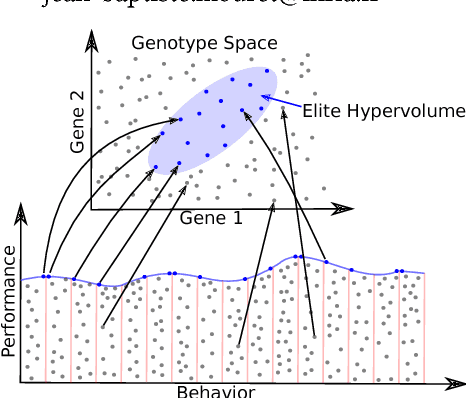

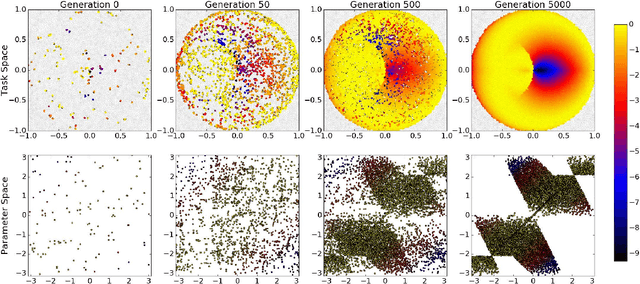
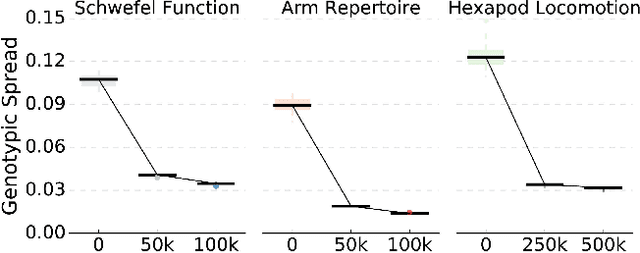
Evolution has produced an astonishing diversity of species, each filling a different niche. Algorithms like MAP-Elites mimic this divergent evolutionary process to find a set of behaviorally diverse but high-performing solutions, called the elites. Our key insight is that species in nature often share a surprisingly large part of their genome, in spite of occupying very different niches; similarly, the elites are likely to be concentrated in a specific "elite hypervolume" whose shape is defined by their common features. In this paper, we first introduce the elite hypervolume concept and propose two metrics to characterize it: the genotypic spread and the genotypic similarity. We then introduce a new variation operator, called "directional variation", that exploits interspecies (or inter-elites) correlations to accelerate the MAP-Elites algorithm. We demonstrate the effectiveness of this operator in three problems (a toy function, a redundant robotic arm, and a hexapod robot).
Reset-free Trial-and-Error Learning for Robot Damage Recovery
Dec 12, 2017
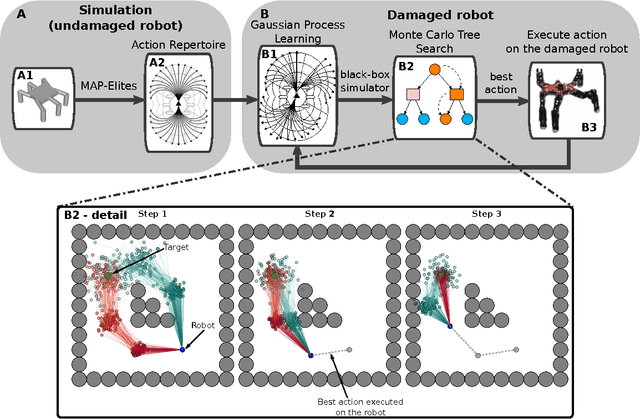
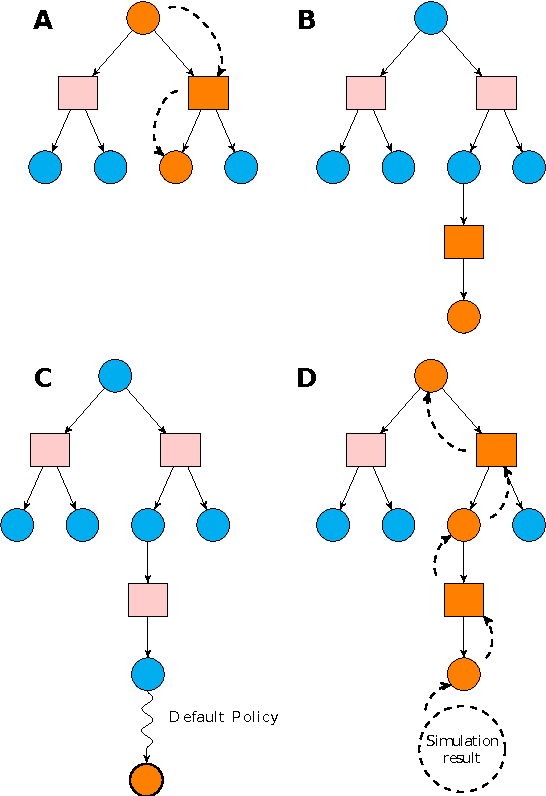
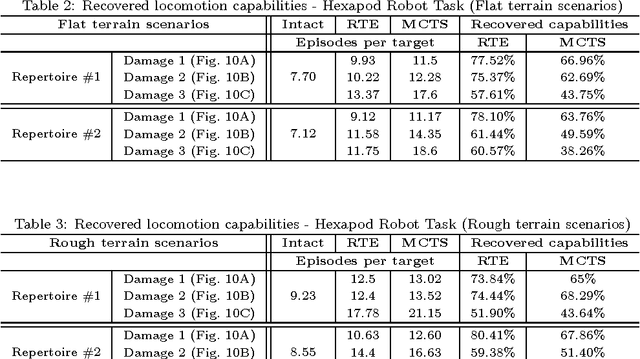
The high probability of hardware failures prevents many advanced robots (e.g., legged robots) from being confidently deployed in real-world situations (e.g., post-disaster rescue). Instead of attempting to diagnose the failures, robots could adapt by trial-and-error in order to be able to complete their tasks. In this situation, damage recovery can be seen as a Reinforcement Learning (RL) problem. However, the best RL algorithms for robotics require the robot and the environment to be reset to an initial state after each episode, that is, the robot is not learning autonomously. In addition, most of the RL methods for robotics do not scale well with complex robots (e.g., walking robots) and either cannot be used at all or take too long to converge to a solution (e.g., hours of learning). In this paper, we introduce a novel learning algorithm called "Reset-free Trial-and-Error" (RTE) that (1) breaks the complexity by pre-generating hundreds of possible behaviors with a dynamics simulator of the intact robot, and (2) allows complex robots to quickly recover from damage while completing their tasks and taking the environment into account. We evaluate our algorithm on a simulated wheeled robot, a simulated six-legged robot, and a real six-legged walking robot that are damaged in several ways (e.g., a missing leg, a shortened leg, faulty motor, etc.) and whose objective is to reach a sequence of targets in an arena. Our experiments show that the robots can recover most of their locomotion abilities in an environment with obstacles, and without any human intervention.