 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReset-free Trial-and-Error Learning for Robot Damage Recovery
Paper and Code

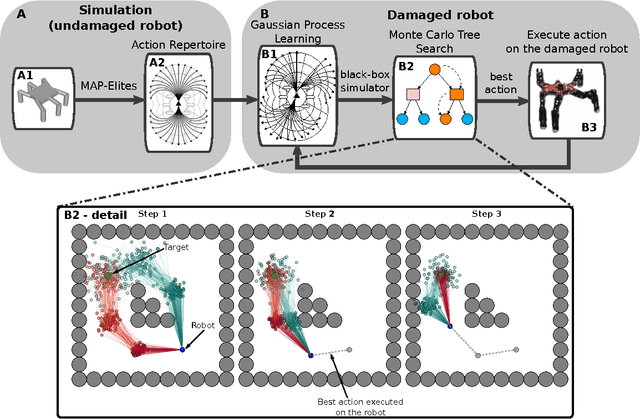
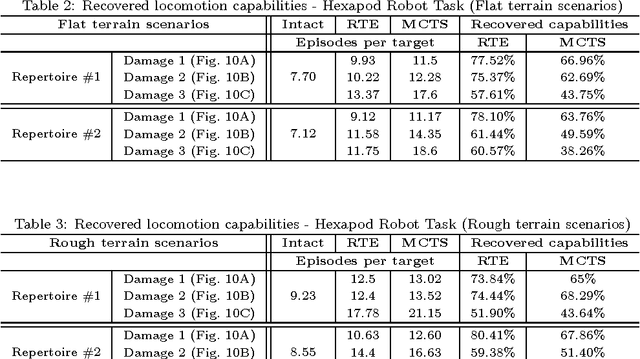
The high probability of hardware failures prevents many advanced robots (e.g., legged robots) from being confidently deployed in real-world situations (e.g., post-disaster rescue). Instead of attempting to diagnose the failures, robots could adapt by trial-and-error in order to be able to complete their tasks. In this situation, damage recovery can be seen as a Reinforcement Learning (RL) problem. However, the best RL algorithms for robotics require the robot and the environment to be reset to an initial state after each episode, that is, the robot is not learning autonomously. In addition, most of the RL methods for robotics do not scale well with complex robots (e.g., walking robots) and either cannot be used at all or take too long to converge to a solution (e.g., hours of learning). In this paper, we introduce a novel learning algorithm called "Reset-free Trial-and-Error" (RTE) that (1) breaks the complexity by pre-generating hundreds of possible behaviors with a dynamics simulator of the intact robot, and (2) allows complex robots to quickly recover from damage while completing their tasks and taking the environment into account. We evaluate our algorithm on a simulated wheeled robot, a simulated six-legged robot, and a real six-legged walking robot that are damaged in several ways (e.g., a missing leg, a shortened leg, faulty motor, etc.) and whose objective is to reach a sequence of targets in an arena. Our experiments show that the robots can recover most of their locomotion abilities in an environment with obstacles, and without any human intervention.