 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector Quantized-Elites: Unsupervised and Problem-Agnostic Quality-Diversity Optimization
Apr 10, 2025Quality-Diversity algorithms have transformed optimization by prioritizing the discovery of diverse, high-performing solutions over a single optimal result. However, traditional Quality-Diversity methods, such as MAP-Elites, rely heavily on predefined behavioral descriptors and complete prior knowledge of the task to define the behavioral space grid, limiting their flexibility and applicability. In this work, we introduce Vector Quantized-Elites (VQ-Elites), a novel Quality-Diversity algorithm that autonomously constructs a structured behavioral space grid using unsupervised learning, eliminating the need for prior task-specific knowledge. At the core of VQ-Elites is the integration of Vector Quantized Variational Autoencoders, which enables the dynamic learning of behavioral descriptors and the generation of a structured, rather than unstructured, behavioral space grid - a significant advancement over existing unsupervised Quality-Diversity approaches. This design establishes VQ-Elites as a flexible, robust, and task-agnostic optimization framework. To further enhance the performance of unsupervised Quality-Diversity algorithms, we introduce two key components: behavioral space bounding and cooperation mechanisms, which significantly improve convergence and performance. We validate VQ-Elites on robotic arm pose-reaching and mobile robot space-covering tasks. The results demonstrate its ability to efficiently generate diverse, high-quality solutions, emphasizing its adaptability, scalability, robustness to hyperparameters, and potential to extend Quality-Diversity optimization to complex, previously inaccessible domains.
Gait Optimization for Legged Systems Through Mixed Distribution Cross-Entropy Optimization
Oct 03, 2024Legged robotic systems can play an important role in real-world applications due to their superior load-bearing capabilities, enhanced autonomy, and effective navigation on uneven terrain. They offer an optimal trade-off between mobility and payload capacity, excelling in diverse environments while maintaining efficiency in transporting heavy loads. However, planning and optimizing gaits and gait sequences for these robots presents significant challenges due to the complexity of their dynamic motion and the numerous optimization variables involved. Traditional trajectory optimization methods address these challenges by formulating the problem as an optimization task, aiming to minimize cost functions, and to automatically discover contact sequences. Despite their structured approach, optimization-based methods face substantial difficulties, particularly because such formulations result in highly nonlinear and difficult to solve problems. To address these limitations, we propose CrEGOpt, a bi-level optimization method that combines traditional trajectory optimization with a black-box optimization scheme. CrEGOpt at the higher level employs the Mixed Distribution Cross-Entropy Method to optimize both the gait sequence and the phase durations, thus simplifying the lower level trajectory optimization problem. This approach allows for fast solutions of complex gait optimization problems. Extensive evaluation in simulated environments demonstrates that CrEGOpt can find solutions for biped, quadruped, and hexapod robots in under 10 seconds. This novel bi-level optimization scheme offers a promising direction for future research in automatic contact scheduling.
End-to-End Stable Imitation Learning via Autonomous Neural Dynamic Policies
May 22, 2023State-of-the-art sensorimotor learning algorithms offer policies that can often produce unstable behaviors, damaging the robot and/or the environment. Traditional robot learning, on the contrary, relies on dynamical system-based policies that can be analyzed for stability/safety. Such policies, however, are neither flexible nor generic and usually work only with proprioceptive sensor states. In this work, we bridge the gap between generic neural network policies and dynamical system-based policies, and we introduce Autonomous Neural Dynamic Policies (ANDPs) that: (a) are based on autonomous dynamical systems, (b) always produce asymptotically stable behaviors, and (c) are more flexible than traditional stable dynamical system-based policies. ANDPs are fully differentiable, flexible generic-policies that can be used in imitation learning setups while ensuring asymptotic stability. In this paper, we explore the flexibility and capacity of ANDPs in several imitation learning tasks including experiments with image observations. The results show that ANDPs combine the benefits of both neural network-based and dynamical system-based methods.
Combining Planning, Reasoning and Reinforcement Learning to solve Industrial Robot Tasks
Dec 07, 2022One of today's goals for industrial robot systems is to allow fast and easy provisioning for new tasks. Skill-based systems that use planning and knowledge representation have long been one possible answer to this. However, especially with contact-rich robot tasks that need careful parameter settings, such reasoning techniques can fall short if the required knowledge not adequately modeled. We show an approach that provides a combination of task-level planning and reasoning with targeted learning of skill parameters for a task at hand. Starting from a task goal formulated in PDDL, the learnable parameters in the plan are identified and an operator can choose reward functions and parameters for the learning process. A tight integration with a knowledge framework allows to form a prior for learning and the usage of multi-objective Bayesian optimization eases to balance aspects such as safety and task performance that can often affect each other. We demonstrate the efficacy and versatility of our approach by learning skill parameters for two different contact-rich tasks and show their successful execution on a real 7-DOF KUKA-iiwa.
Online Damage Recovery for Physical Robots with Hierarchical Quality-Diversity
Oct 18, 2022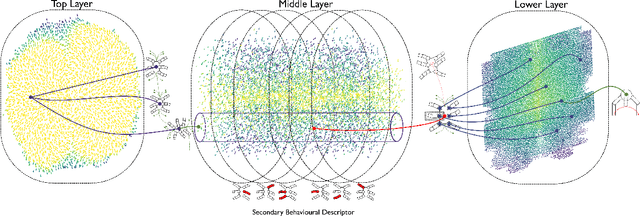


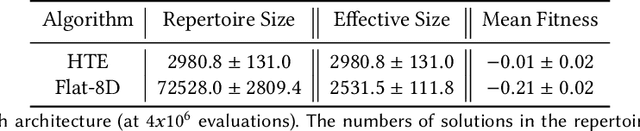
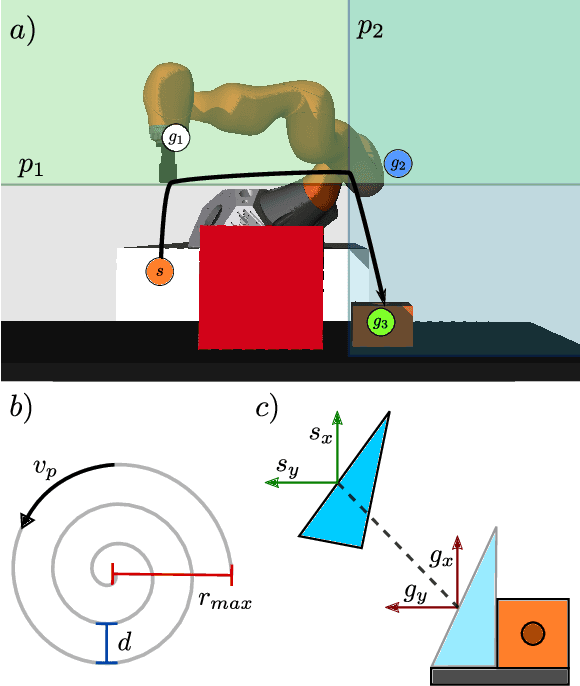
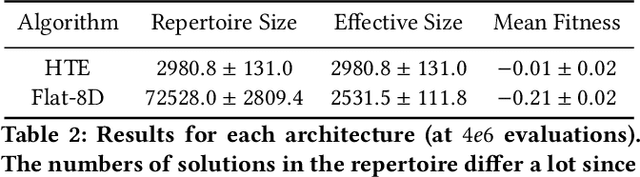
In real-world environments, robots need to be resilient to damages and robust to unforeseen scenarios. Quality-Diversity (QD) algorithms have been successfully used to make robots adapt to damages in seconds by leveraging a diverse set of learned skills. A high diversity of skills increases the chances of a robot to succeed at overcoming new situations since there are more potential alternatives to solve a new task.However, finding and storing a large behavioural diversity of multiple skills often leads to an increase in computational complexity. Furthermore, robot planning in a large skill space is an additional challenge that arises with an increased number of skills. Hierarchical structures can help reducing this search and storage complexity by breaking down skills into primitive skills. In this paper, we introduce the Hierarchical Trial and Error algorithm, which uses a hierarchical behavioural repertoire to learn diverse skills and leverages them to make the robot adapt quickly in the physical world. We show that the hierarchical decomposition of skills enables the robot to learn more complex behaviours while keeping the learning of the repertoire tractable. Experiments with a hexapod robot show that our method solves a maze navigation tasks with 20% less actions in simulation, and 43% less actions in the physical world, for the most challenging scenarios than the best baselines while having 78% less complete failures.
Learning Skill-based Industrial Robot Tasks with User Priors
Aug 02, 2022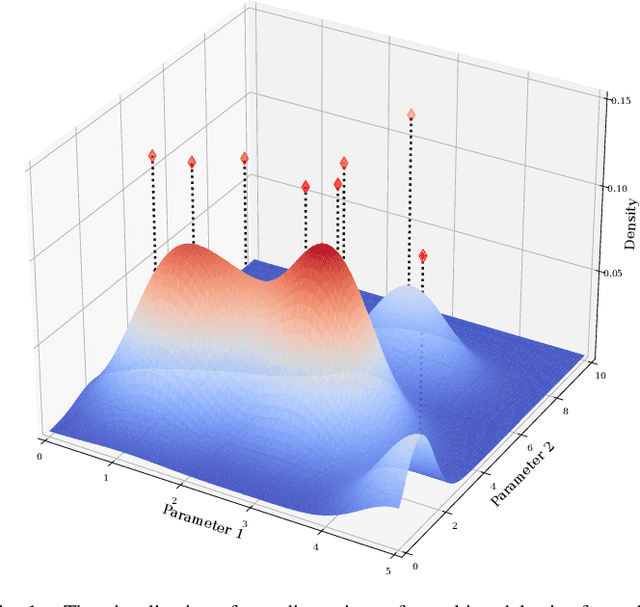

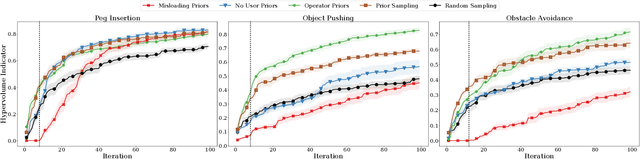
Robot skills systems are meant to reduce robot setup time for new manufacturing tasks. Yet, for dexterous, contact-rich tasks, it is often difficult to find the right skill parameters. One strategy is to learn these parameters by allowing the robot system to learn directly on the task. For a learning problem, a robot operator can typically specify the type and range of values of the parameters. Nevertheless, given their prior experience, robot operators should be able to help the learning process further by providing educated guesses about where in the parameter space potential optimal solutions could be found. Interestingly, such prior knowledge is not exploited in current robot learning frameworks. We introduce an approach that combines user priors and Bayesian optimization to allow fast optimization of robot industrial tasks at robot deployment time. We evaluate our method on three tasks that are learned in simulation as well as on two tasks that are learned directly on a real robot system. Additionally, we transfer knowledge from the corresponding simulation tasks by automatically constructing priors from well-performing configurations for learning on the real system. To handle potentially contradicting task objectives, the tasks are modeled as multi-objective problems. Our results show that operator priors, both user-specified and transferred, vastly accelerate the discovery of rich Pareto fronts, and typically produce final performance far superior to proposed baselines.
Hierarchical Quality-Diversity for Online Damage Recovery
Apr 12, 2022
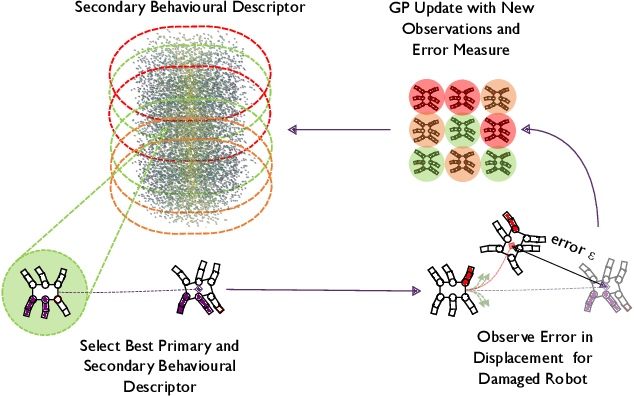

Adaptation capabilities, like damage recovery, are crucial for the deployment of robots in complex environments. Several works have demonstrated that using repertoires of pre-trained skills can enable robots to adapt to unforeseen mechanical damages in a few minutes. These adaptation capabilities are directly linked to the behavioural diversity in the repertoire. The more alternatives the robot has to execute a skill, the better are the chances that it can adapt to a new situation. However, solving complex tasks, like maze navigation, usually requires multiple different skills. Finding a large behavioural diversity for these multiple skills often leads to an intractable exponential growth of the number of required solutions. In this paper, we introduce the Hierarchical Trial and Error algorithm, which uses a hierarchical behavioural repertoire to learn diverse skills and leverages them to make the robot more adaptive to different situations. We show that the hierarchical decomposition of skills enables the robot to learn more complex behaviours while keeping the learning of the repertoire tractable. The experiments with a hexapod robot show that our method solves maze navigation tasks with 20% less actions in the most challenging scenarios than the best baseline while having 57% less complete failures.
Skill-based Multi-objective Reinforcement Learning of Industrial Robot Tasks with Planning and Knowledge Integration
Mar 18, 2022

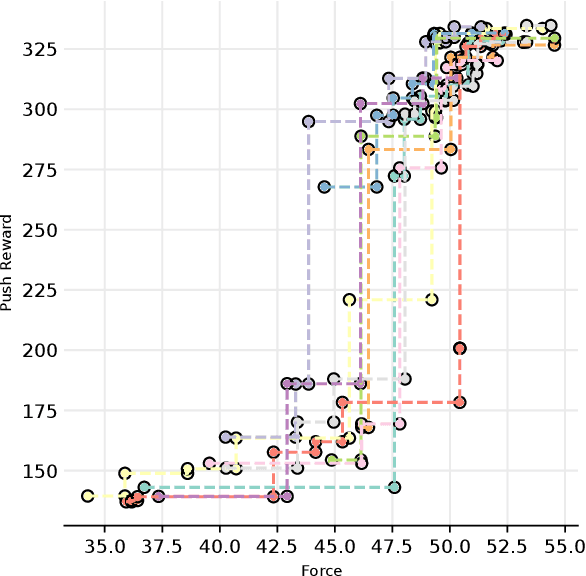
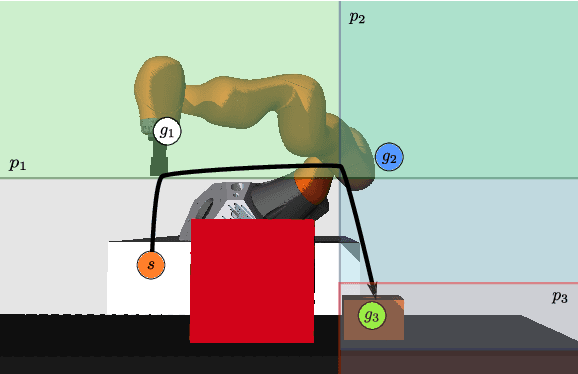
In modern industrial settings with small batch sizes it should be easy to set up a robot system for a new task. Strategies exist, e.g. the use of skills, but when it comes to handling forces and torques, these systems often fall short. We introduce an approach that provides a combination of task-level planning with targeted learning of scenario-specific parameters for skill-based systems. We propose the following pipeline: (1) the user provides a task goal in the planning language PDDL, (2) a plan (i.e., a sequence of skills) is generated and the learnable parameters of the skills are automatically identified. An operator then chooses (3) reward functions and hyperparameters for the learning process. Two aspects of our methodology are critical: (a) learning is tightly integrated with a knowledge framework to support symbolic planning and to provide priors for learning, (b) using multi-objective optimization. This can help to balance key performance indicators (KPIs) such as safety and task performance since they can often affect each other. We adopt a multi-objective Bayesian optimization approach and learn entirely in simulation. We demonstrate the efficacy and versatility of our approach by learning skill parameters for two different contact-rich tasks. We show their successful execution on a real 7-DOF KUKA-iiwa manipulator and outperform the manual parameterization by human robot operators.
Learning of Parameters in Behavior Trees for Movement Skills
Sep 27, 2021

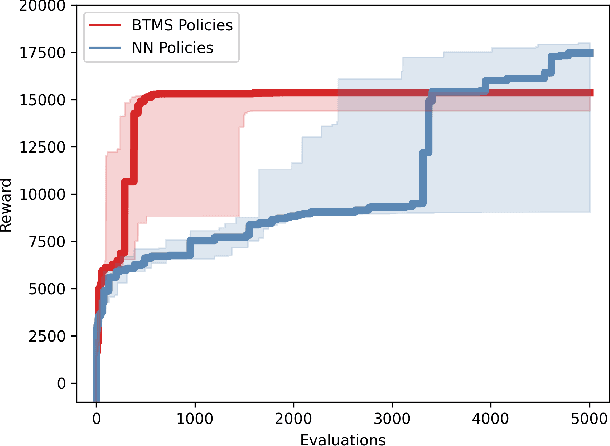
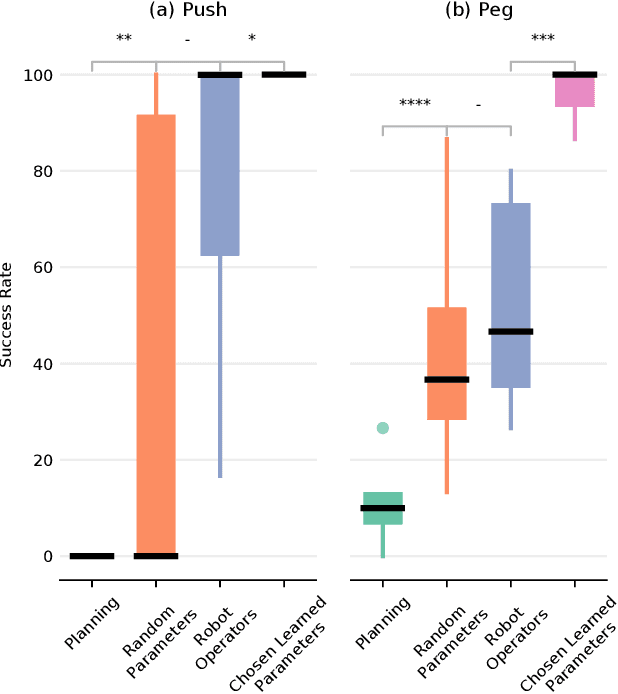
Reinforcement Learning (RL) is a powerful mathematical framework that allows robots to learn complex skills by trial-and-error. Despite numerous successes in many applications, RL algorithms still require thousands of trials to converge to high-performing policies, can produce dangerous behaviors while learning, and the optimized policies (usually modeled as neural networks) give almost zero explanation when they fail to perform the task. For these reasons, the adoption of RL in industrial settings is not common. Behavior Trees (BTs), on the other hand, can provide a policy representation that a) supports modular and composable skills, b) allows for easy interpretation of the robot actions, and c) provides an advantageous low-dimensional parameter space. In this paper, we present a novel algorithm that can learn the parameters of a BT policy in simulation and then generalize to the physical robot without any additional training. We leverage a physical simulator with a digital twin of our workstation, and optimize the relevant parameters with a black-box optimizer. We showcase the efficacy of our method with a 7-DOF KUKA-iiwa manipulator in a task that includes obstacle avoidance and a contact-rich insertion (peg-in-hole), in which our method outperforms the baselines.
Quality-Diversity Optimization: a novel branch of stochastic optimization
Dec 17, 2020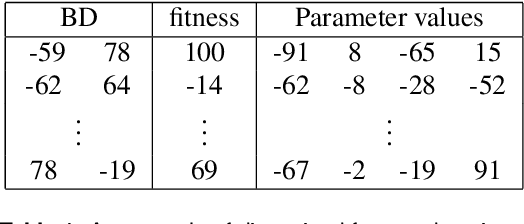
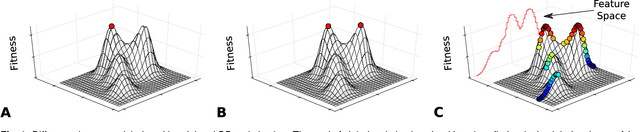
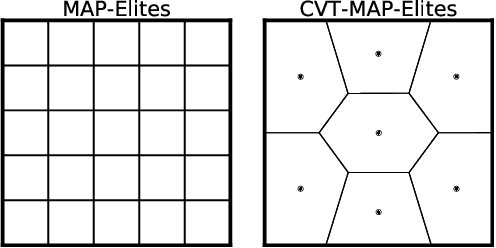
Traditional optimization algorithms search for a single global optimum that maximizes (or minimizes) the objective function. Multimodal optimization algorithms search for the highest peaks in the search space that can be more than one. Quality-Diversity algorithms are a recent addition to the evolutionary computation toolbox that do not only search for a single set of local optima, but instead try to illuminate the search space. In effect, they provide a holistic view of how high-performing solutions are distributed throughout a search space. The main differences with multimodal optimization algorithms are that (1) Quality-Diversity typically works in the behavioral space (or feature space), and not in the genotypic (or parameter) space, and (2) Quality-Diversity attempts to fill the whole behavior space, even if the niche is not a peak in the fitness landscape. In this chapter, we provide a gentle introduction to Quality-Diversity optimization, discuss the main representative algorithms, and the main current topics under consideration in the community. Throughout the chapter, we also discuss several successful applications of Quality-Diversity algorithms, including deep learning, robotics, and reinforcement learning.