 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuest2ROS2: A ROS 2 Framework for Bi-manual VR Teleoperation
Jan 26, 2026Quest2ROS2 is an open-source ROS2 framework for bi-manual teleoperation designed to scale robot data collection. Extending Quest2ROS, it overcomes workspace limitations via relative motion-based control, calculating robot movement from VR controller pose changes to enable intuitive, pose-independent operation. The framework integrates essential usability and safety features, including real-time RViz visualization, streamlined gripper control, and a pause-and-reset function for smooth transitions. We detail a modular architecture that supports "Side-by-Side" and "Mirror" control modes to optimize operator experience across diverse platforms. Code is available at: https://github.com/Taokt/Quest2ROS2.
LRBO2: Improved 3D Vision Based Hand-Eye Calibration for Collaborative Robot Arm
Apr 30, 2025Hand-eye calibration is a common problem in the field of collaborative robotics, involving the determination of the transformation matrix between the visual sensor and the robot flange to enable vision-based robotic tasks. However, this process typically requires multiple movements of the robot arm and an external calibration object, making it both time-consuming and inconvenient, especially in scenarios where frequent recalibration is necessary. In this work, we extend our previous method, Look at Robot Base Once (LRBO), which eliminates the need for external calibration objects such as a chessboard. We propose a generic dataset generation approach for point cloud registration, focusing on aligning the robot base point cloud with the scanned data. Furthermore, a more detailed simulation study is conducted involving several different collaborative robot arms, followed by real-world experiments in an industrial setting. Our improved method is simulated and evaluated using a total of 14 robotic arms from 9 different brands, including KUKA, Universal Robots, UFACTORY, and Franka Emika, all of which are widely used in the field of collaborative robotics. Physical experiments demonstrate that our extended approach achieves performance comparable to existing commercial hand-eye calibration solutions, while completing the entire calibration procedure in just a few seconds. In addition, we provide a user-friendly hand-eye calibration solution, with the code publicly available at github.com/leihui6/LRBO2.
A Unified Framework for Real-Time Failure Handling in Robotics Using Vision-Language Models, Reactive Planner and Behavior Trees
Mar 21, 2025Robotic systems often face execution failures due to unexpected obstacles, sensor errors, or environmental changes. Traditional failure recovery methods rely on predefined strategies or human intervention, making them less adaptable. This paper presents a unified failure recovery framework that combines Vision-Language Models (VLMs), a reactive planner, and Behavior Trees (BTs) to enable real-time failure handling. Our approach includes pre-execution verification, which checks for potential failures before execution, and reactive failure handling, which detects and corrects failures during execution by verifying existing BT conditions, adding missing preconditions and, when necessary, generating new skills. The framework uses a scene graph for structured environmental perception and an execution history for continuous monitoring, enabling context-aware and adaptive failure handling. We evaluate our framework through real-world experiments with an ABB YuMi robot on tasks like peg insertion, object sorting, and drawer placement, as well as in AI2-THOR simulator. Compared to using pre-execution and reactive methods separately, our approach achieves higher task success rates and greater adaptability. Ablation studies highlight the importance of VLM-based reasoning, structured scene representation, and execution history tracking for effective failure recovery in robotics.
Addressing Failures in Robotics using Vision-Based Language Models (VLMs) and Behavior Trees (BT)
Nov 03, 2024In this paper, we propose an approach that combines Vision Language Models (VLMs) and Behavior Trees (BTs) to address failures in robotics. Current robotic systems can handle known failures with pre-existing recovery strategies, but they are often ill-equipped to manage unknown failures or anomalies. We introduce VLMs as a monitoring tool to detect and identify failures during task execution. Additionally, VLMs generate missing conditions or skill templates that are then incorporated into the BT, ensuring the system can autonomously address similar failures in future tasks. We validate our approach through simulations in several failure scenarios.
Flexible and Adaptive Manufacturing by Complementing Knowledge Representation, Reasoning and Planning with Reinforcement Learning
Nov 15, 2023This paper describes a novel approach to adaptive manufacturing in the context of small batch production and customization. It focuses on integrating task-level planning and reasoning with reinforcement learning (RL) in the SkiROS2 skill-based robot control platform. This integration enhances the efficiency and adaptability of robotic systems in manufacturing, enabling them to adjust to task variations and learn from interaction data. The paper highlights the architecture of SkiROS2, particularly its world model, skill libraries, and task management. It demonstrates how combining RL with robotic manipulators can learn and improve the execution of industrial tasks. It advocates a multi-objective learning model that eases the learning problem design. The approach can incorporate user priors or previous experiences to accelerate learning and increase safety. Spotlight video: https://youtu.be/H5PmZl2rRbs?si=8wmZ-gbwuSJRxe3S&t=1422 SkiROS2 code: https://github.com/RVMI/skiros2 SkiROS2 talk at ROSCon: https://vimeo.com/879001825/2a0e9d5412 SkiREIL code: https://github.com/matthias-mayr/SkiREIL
BeBOP -- Combining Reactive Planning and Bayesian Optimization to Solve Robotic Manipulation Tasks
Oct 02, 2023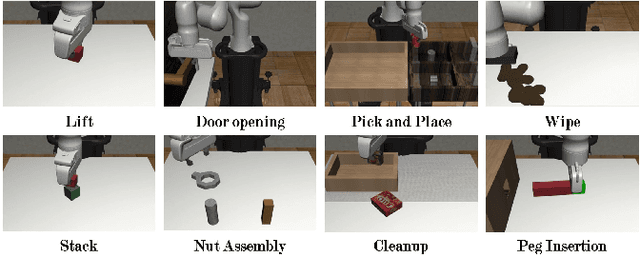
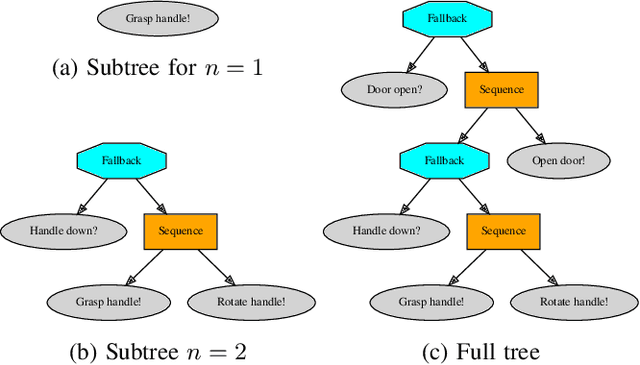
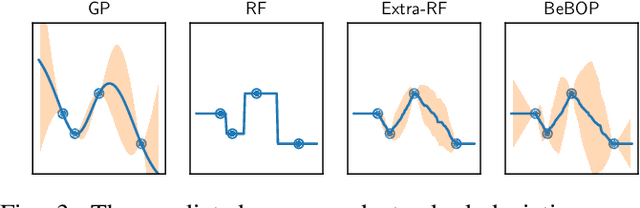
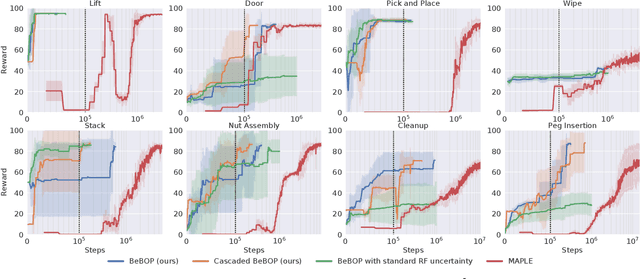
Robotic systems for manipulation tasks are increasingly expected to be easy to configure for new tasks. While in the past, robot programs were often written statically and tuned manually, the current, faster transition times call for robust, modular and interpretable solutions that also allow a robotic system to learn how to perform a task. We propose the method Behavior-based Bayesian Optimization and Planning (BeBOP) that combines two approaches for generating behavior trees: we build the structure using a reactive planner and learn specific parameters with Bayesian optimization. The method is evaluated on a set of robotic manipulation benchmarks and is shown to outperform state-of-the-art reinforcement learning algorithms by being up to 46 times faster while simultaneously being less dependent on reward shaping. We also propose a modification to the uncertainty estimate for the random forest surrogate models that drastically improves the results.
Learning Actions and Control of Focus of Attention with a Log-Polar-like Sensor
Sep 22, 2023With the long-term goal of reducing the image processing time on an autonomous mobile robot in mind we explore in this paper the use of log-polar like image data with gaze control. The gaze control is not done on the Cartesian image but on the log-polar like image data. For this we start out from the classic deep reinforcement learning approach for Atari games. We extend an A3C deep RL approach with an LSTM network, and we learn the policy for playing three Atari games and a policy for gaze control. While the Atari games already use low-resolution images of 80 by 80 pixels, we are able to further reduce the amount of image pixels by a factor of 5 without losing any gaming performance.
Using Knowledge Representation and Task Planning for Robot-agnostic Skills on the Example of Contact-Rich Wiping Tasks
Aug 27, 2023The transition to agile manufacturing, Industry 4.0, and high-mix-low-volume tasks require robot programming solutions that are flexible. However, most deployed robot solutions are still statically programmed and use stiff position control, which limit their usefulness. In this paper, we show how a single robot skill that utilizes knowledge representation, task planning, and automatic selection of skill implementations based on the input parameters can be executed in different contexts. We demonstrate how the skill-based control platform enables this with contact-rich wiping tasks on different robot systems. To achieve that in this case study, our approach needs to address different kinematics, gripper types, vendors, and fundamentally different control interfaces. We conducted the experiments with a mobile platform that has a Universal Robots UR5e 6 degree-of-freedom robot arm with position control and a 7 degree-of-freedom KUKA iiwa with torque control.
SkiROS2: A skill-based Robot Control Platform for ROS
Jun 29, 2023The need for autonomous robot systems in both the service and the industrial domain is larger than ever. In the latter, the transition to small batches or even "batch size 1" in production created a need for robot control system architectures that can provide the required flexibility. Such architectures must not only have a sufficient knowledge integration framework. It must also support autonomous mission execution and allow for interchangeability and interoperability between different tasks and robot systems. We introduce SkiROS2, a skill-based robot control platform on top of ROS. SkiROS2 proposes a layered, hybrid control structure for automated task planning, and reactive execution, supported by a knowledge base for reasoning about the world state and entities. The scheduling formulation builds on the extended behavior tree model that merges task-level planning and execution. This allows for a high degree of modularity and a fast reaction to changes in the environment. The skill formulation based on pre-, hold- and post-conditions allows to organize robot programs and to compose diverse skills reaching from perception to low-level control and the incorporation of external tools. We relate SkiROS2 to the field and outline three example use cases that cover task planning, reasoning, multisensory input, integration in a manufacturing execution system and reinforcement learning.
Out-of-Distribution Detection for Adaptive Computer Vision
May 16, 2023It is well known that computer vision can be unreliable when faced with previously unseen imaging conditions. This paper proposes a method to adapt camera parameters according to a normalizing flow-based out-of-distibution detector. A small-scale study is conducted which shows that adapting camera parameters according to this out-of-distibution detector leads to an average increase of 3 to 4 percentage points in mAP, mAR and F1 performance metrics of a YOLOv4 object detector. As a secondary result, this paper also shows that it is possible to train a normalizing flow model for out-of-distribution detection on the COCO dataset, which is larger and more diverse than most benchmarks for out-of-distibution detectors.
* Published in Springer Lecture Notes for Computer Science Vol. 13886 as part of the conference proceedings for Scandinavian Conference on Image Analysis 2023