 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViT-A*: Legged Robot Path Planning using Vision Transformer A*
Oct 11, 2023Legged robots, particularly quadrupeds, offer promising navigation capabilities, especially in scenarios requiring traversal over diverse terrains and obstacle avoidance. This paper addresses the challenge of enabling legged robots to navigate complex environments effectively through the integration of data-driven path-planning methods. We propose an approach that utilizes differentiable planners, allowing the learning of end-to-end global plans via a neural network for commanding quadruped robots. The approach leverages 2D maps and obstacle specifications as inputs to generate a global path. To enhance the functionality of the developed neural network-based path planner, we use Vision Transformers (ViT) for map pre-processing, to enable the effective handling of larger maps. Experimental evaluations on two real robotic quadrupeds (Boston Dynamics Spot and Unitree Go1) demonstrate the effectiveness and versatility of the proposed approach in generating reliable path plans.
* 6 pages, 6 figures, conference
End-to-End Stable Imitation Learning via Autonomous Neural Dynamic Policies
May 22, 2023State-of-the-art sensorimotor learning algorithms offer policies that can often produce unstable behaviors, damaging the robot and/or the environment. Traditional robot learning, on the contrary, relies on dynamical system-based policies that can be analyzed for stability/safety. Such policies, however, are neither flexible nor generic and usually work only with proprioceptive sensor states. In this work, we bridge the gap between generic neural network policies and dynamical system-based policies, and we introduce Autonomous Neural Dynamic Policies (ANDPs) that: (a) are based on autonomous dynamical systems, (b) always produce asymptotically stable behaviors, and (c) are more flexible than traditional stable dynamical system-based policies. ANDPs are fully differentiable, flexible generic-policies that can be used in imitation learning setups while ensuring asymptotic stability. In this paper, we explore the flexibility and capacity of ANDPs in several imitation learning tasks including experiments with image observations. The results show that ANDPs combine the benefits of both neural network-based and dynamical system-based methods.
One-Shot Transfer of Affordance Regions? AffCorrs!
Sep 16, 2022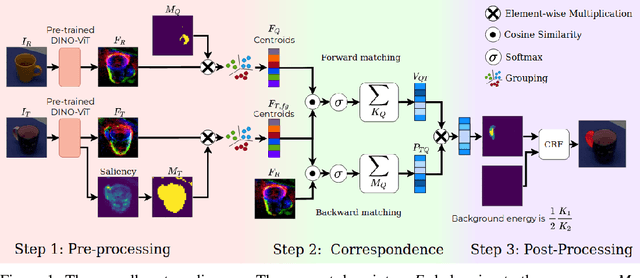
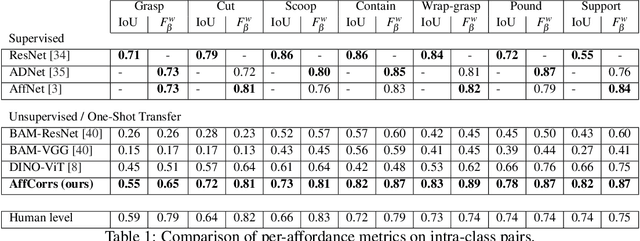


In this work, we tackle one-shot visual search of object parts. Given a single reference image of an object with annotated affordance regions, we segment semantically corresponding parts within a target scene. We propose AffCorrs, an unsupervised model that combines the properties of pre-trained DINO-ViT's image descriptors and cyclic correspondences. We use AffCorrs to find corresponding affordances both for intra- and inter-class one-shot part segmentation. This task is more difficult than supervised alternatives, but enables future work such as learning affordances via imitation and assisted teleoperation.
Fully Self-Supervised Class Awareness in Dense Object Descriptors
Oct 05, 2021

We address the problem of inferring self-supervised dense semantic correspondences between objects in multi-object scenes. The method introduces learning of class-aware dense object descriptors by providing either unsupervised discrete labels or confidence in object similarities. We quantitatively and qualitatively show that the introduced method outperforms previous techniques with more robust pixel-to-pixel matches. An example robotic application is also shown~- grasping of objects in clutter based on corresponding points.
Improved Reinforcement Learning Coordinated Control of a Mobile Manipulator using Joint Clamping
Oct 05, 2021
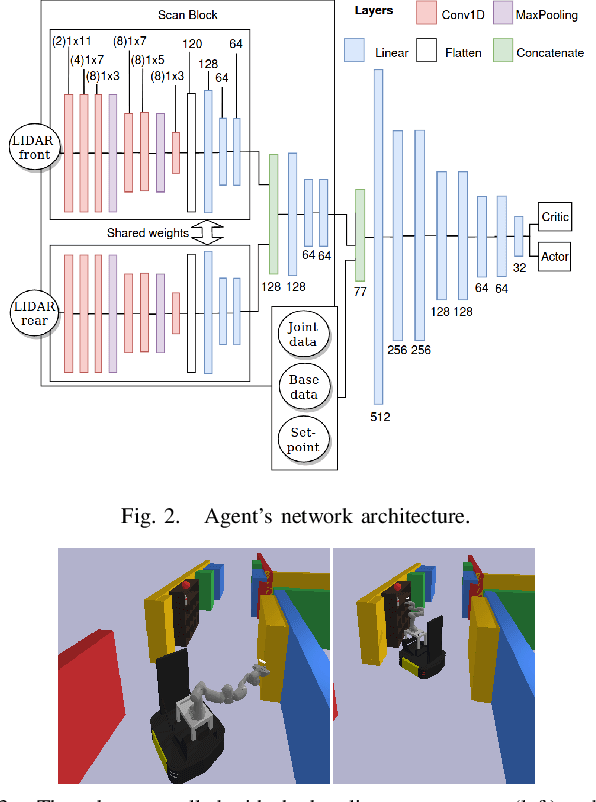

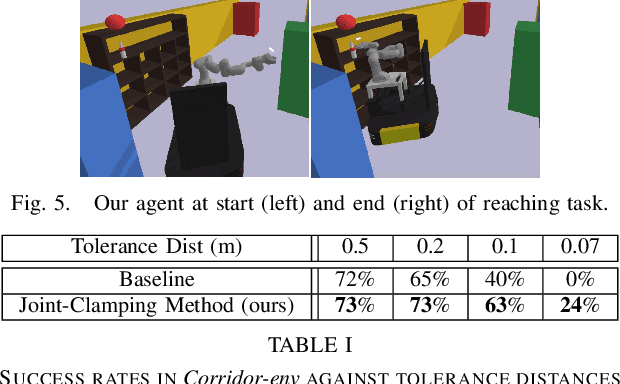
Many robotic path planning problems are continuous, stochastic, and high-dimensional. The ability of a mobile manipulator to coordinate its base and manipulator in order to control its whole-body online is particularly challenging when self and environment collision avoidance is required. Reinforcement Learning techniques have the potential to solve such problems through their ability to generalise over environments. We study joint penalties and joint limits of a state-of-the-art mobile manipulator whole-body controller that uses LIDAR sensing for obstacle collision avoidance. We propose directions to improve the reinforcement learning method. Our agent achieves significantly higher success rates than the baseline in a goal-reaching environment and it can solve environments that require coordinated whole-body control which the baseline fails.