 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Reinforcement Learning Coordinated Control of a Mobile Manipulator using Joint Clamping
Paper and Code
Oct 05, 2021
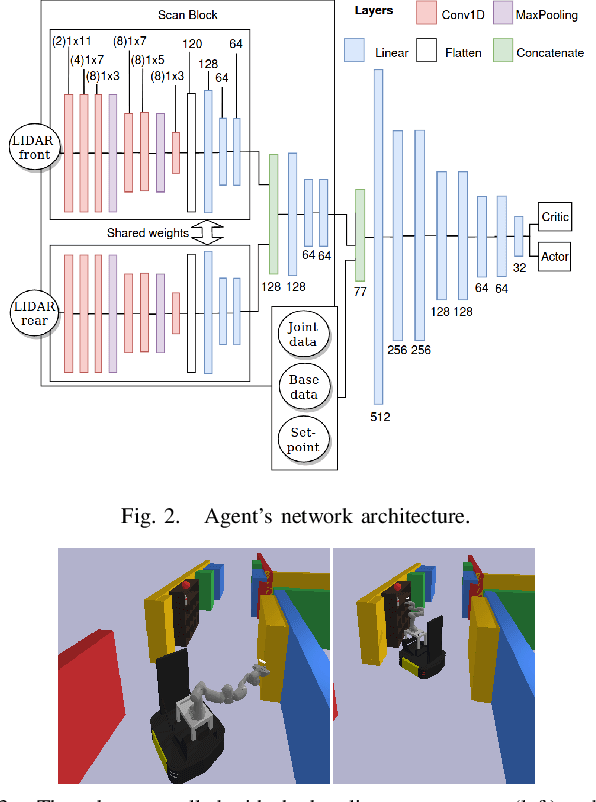

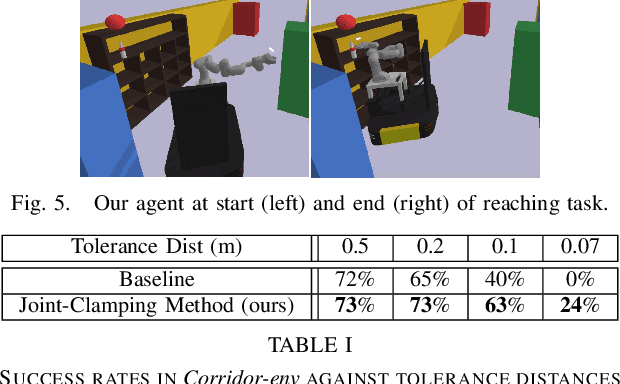
Many robotic path planning problems are continuous, stochastic, and high-dimensional. The ability of a mobile manipulator to coordinate its base and manipulator in order to control its whole-body online is particularly challenging when self and environment collision avoidance is required. Reinforcement Learning techniques have the potential to solve such problems through their ability to generalise over environments. We study joint penalties and joint limits of a state-of-the-art mobile manipulator whole-body controller that uses LIDAR sensing for obstacle collision avoidance. We propose directions to improve the reinforcement learning method. Our agent achieves significantly higher success rates than the baseline in a goal-reaching environment and it can solve environments that require coordinated whole-body control which the baseline fails.