Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Self-Supervised Class Awareness in Dense Object Descriptors
Paper and Code
Oct 05, 2021
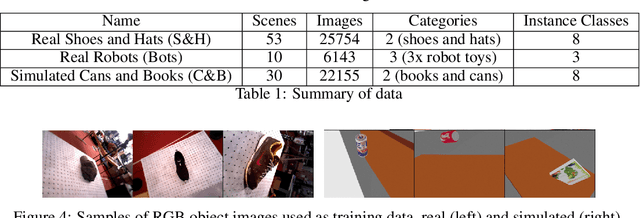
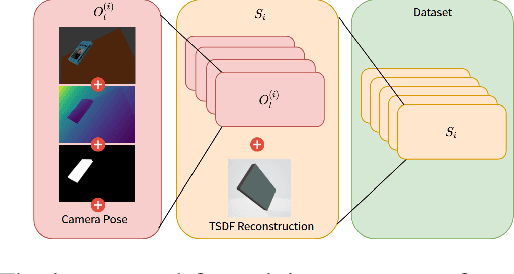

We address the problem of inferring self-supervised dense semantic correspondences between objects in multi-object scenes. The method introduces learning of class-aware dense object descriptors by providing either unsupervised discrete labels or confidence in object similarities. We quantitatively and qualitatively show that the introduced method outperforms previous techniques with more robust pixel-to-pixel matches. An example robotic application is also shown~- grasping of objects in clutter based on corresponding points.
* CoRL 2021, Site:
https://sites.google.com/view/multi-object-dense-descriptors
View paper on
 OpenReview
OpenReview