Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Shot Transfer of Affordance Regions? AffCorrs!
Paper and Code
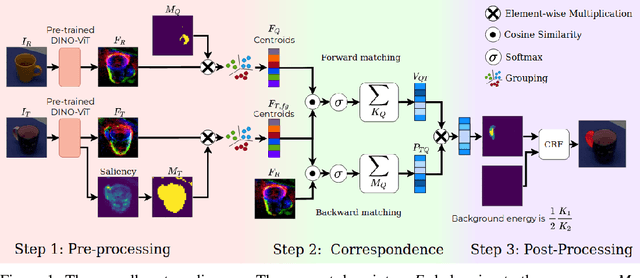
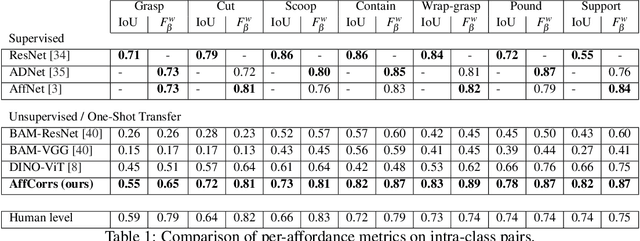


In this work, we tackle one-shot visual search of object parts. Given a single reference image of an object with annotated affordance regions, we segment semantically corresponding parts within a target scene. We propose AffCorrs, an unsupervised model that combines the properties of pre-trained DINO-ViT's image descriptors and cyclic correspondences. We use AffCorrs to find corresponding affordances both for intra- and inter-class one-shot part segmentation. This task is more difficult than supervised alternatives, but enables future work such as learning affordances via imitation and assisted teleoperation.
* Published in Conference on Robot Learning, 2022 For code and dataset,
refer to https://sites.google.com/view/affcorrs
View paper on
 OpenReview
OpenReview