 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEAKS: Selecting Key Training Examples Incrementally via Prediction Error Anchored by Kernel Similarity
Apr 08, 2025



As deep learning continues to be driven by ever-larger datasets, understanding which examples are most important for generalization has become a critical question. While progress in data selection continues, emerging applications require studying this problem in dynamic contexts. To bridge this gap, we pose the Incremental Data Selection (IDS) problem, where examples arrive as a continuous stream, and need to be selected without access to the full data source. In this setting, the learner must incrementally build a training dataset of predefined size while simultaneously learning the underlying task. We find that in IDS, the impact of a new sample on the model state depends fundamentally on both its geometric relationship in the feature space and its prediction error. Leveraging this insight, we propose PEAKS (Prediction Error Anchored by Kernel Similarity), an efficient data selection method tailored for IDS. Our comprehensive evaluations demonstrate that PEAKS consistently outperforms existing selection strategies. Furthermore, PEAKS yields increasingly better performance returns than random selection as training data size grows on real-world datasets.
Patch-Based Contrastive Learning and Memory Consolidation for Online Unsupervised Continual Learning
Sep 24, 2024We focus on a relatively unexplored learning paradigm known as {\em Online Unsupervised Continual Learning} (O-UCL), where an agent receives a non-stationary, unlabeled data stream and progressively learns to identify an increasing number of classes. This paradigm is designed to model real-world applications where encountering novelty is the norm, such as exploring a terrain with several unknown and time-varying entities. Unlike prior work in unsupervised, continual, or online learning, O-UCL combines all three areas into a single challenging and realistic learning paradigm. In this setting, agents are frequently evaluated and must aim to maintain the best possible representation at any point of the data stream, rather than at the end of pre-specified offline tasks. The proposed approach, called \textbf{P}atch-based \textbf{C}ontrastive learning and \textbf{M}emory \textbf{C}onsolidation (PCMC), builds a compositional understanding of data by identifying and clustering patch-level features. Embeddings for these patch-level features are extracted with an encoder trained via patch-based contrastive learning. PCMC incorporates new data into its distribution while avoiding catastrophic forgetting, and it consolidates memory examples during ``sleep" periods. We evaluate PCMC's performance on streams created from the ImageNet and Places365 datasets. Additionally, we explore various versions of the PCMC algorithm and compare its performance against several existing methods and simple baselines.
Neural Sculpting: Uncovering hierarchically modular task structure through pruning and network analysis
Jun 03, 2023Natural target functions and tasks typically exhibit hierarchical modularity - they can be broken down into simpler sub-functions that are organized in a hierarchy. Such sub-functions have two important features: they have a distinct set of inputs (input-separability) and they are reused as inputs higher in the hierarchy (reusability). Previous studies have established that hierarchically modular neural networks, which are inherently sparse, offer benefits such as learning efficiency, generalization, multi-task learning, and transferability. However, identifying the underlying sub-functions and their hierarchical structure for a given task can be challenging. The high-level question in this work is: if we learn a task using a sufficiently deep neural network, how can we uncover the underlying hierarchy of sub-functions in that task? As a starting point, we examine the domain of Boolean functions, where it is easier to determine whether a task is hierarchically modular. We propose an approach based on iterative unit and edge pruning (during training), combined with network analysis for module detection and hierarchy inference. Finally, we demonstrate that this method can uncover the hierarchical modularity of a wide range of Boolean functions and two vision tasks based on the MNIST digits dataset.
SHARP: Sparsity and Hidden Activation RePlay for Neuro-Inspired Continual Learning
May 29, 2023Deep neural networks (DNNs) struggle to learn in dynamic environments since they rely on fixed datasets or stationary environments. Continual learning (CL) aims to address this limitation and enable DNNs to accumulate knowledge incrementally, similar to human learning. Inspired by how our brain consolidates memories, a powerful strategy in CL is replay, which involves training the DNN on a mixture of new and all seen classes. However, existing replay methods overlook two crucial aspects of biological replay: 1) the brain replays processed neural patterns instead of raw input, and 2) it prioritizes the replay of recently learned information rather than revisiting all past experiences. To address these differences, we propose SHARP, an efficient neuro-inspired CL method that leverages sparse dynamic connectivity and activation replay. Unlike other activation replay methods, which assume layers not subjected to replay have been pretrained and fixed, SHARP can continually update all layers. Also, SHARP is unique in that it only needs to replay few recently seen classes instead of all past classes. Our experiments on five datasets demonstrate that SHARP outperforms state-of-the-art replay methods in class incremental learning. Furthermore, we showcase SHARP's flexibility in a novel CL scenario where the boundaries between learning episodes are blurry. The SHARP code is available at \url{https://github.com/BurakGurbuz97/SHARP-Continual-Learning}.
NISPA: Neuro-Inspired Stability-Plasticity Adaptation for Continual Learning in Sparse Networks
Jun 18, 2022


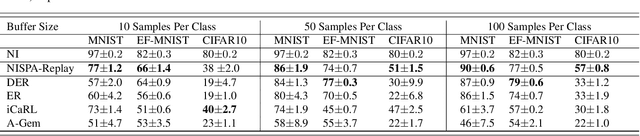
The goal of continual learning (CL) is to learn different tasks over time. The main desiderata associated with CL are to maintain performance on older tasks, leverage the latter to improve learning of future tasks, and to introduce minimal overhead in the training process (for instance, to not require a growing model or retraining). We propose the Neuro-Inspired Stability-Plasticity Adaptation (NISPA) architecture that addresses these desiderata through a sparse neural network with fixed density. NISPA forms stable paths to preserve learned knowledge from older tasks. Also, NISPA uses connection rewiring to create new plastic paths that reuse existing knowledge on novel tasks. Our extensive evaluation on EMNIST, FashionMNIST, CIFAR10, and CIFAR100 datasets shows that NISPA significantly outperforms representative state-of-the-art continual learning baselines, and it uses up to ten times fewer learnable parameters compared to baselines. We also make the case that sparsity is an essential ingredient for continual learning. The NISPA code is available at https://github.com/BurakGurbuz97/NISPA.
PHEW: Paths with higher edge-weights give "winning tickets" without training data
Oct 22, 2020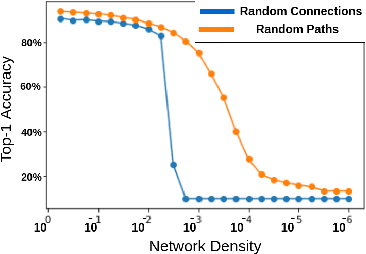
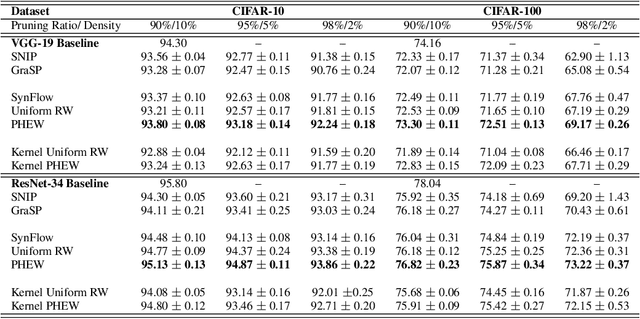
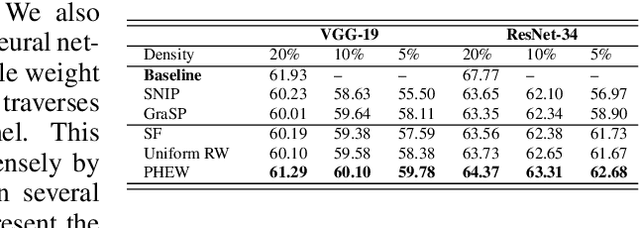
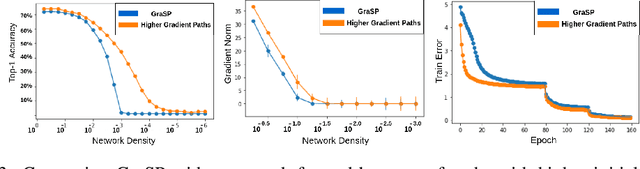
Sparse neural networks have generated substantial interest recently because they can be more efficient in learning and inference, without any significant drop in performance. The "lottery ticket hypothesis" has showed the existence of such sparse subnetworks at initialization. Given a fully-connected initialized architecture, our aim is to find such "winning ticket" networks, without any training data. We first show the advantages of forming input-output paths, over pruning individual connections, to avoid bottlenecks in gradient propagation. Then, we show that Paths with Higher Edge-Weights (PHEW) at initialization have higher loss gradient magnitude, resulting in more efficient training. Selecting such paths can be performed without any data. We empirically validate the effectiveness of the proposed approach against pruning-before-training methods on CIFAR10, CIFAR100 and Tiny-ImageNet for VGG-Net and ResNet. PHEW achieves significant improvements on the current state-of-the-art methods at 10\%, 5\% and 2\% network density. We also evaluate the structural similarity relationship between PHEW networks and pruned networks constructed through Iterated Magnitude Pruning (IMP), concluding that the former belong in the family of winning tickets networks.
Evolution of Hierarchical Structure & Reuse in iGEM Synthetic DNA Sequences
Jun 06, 2019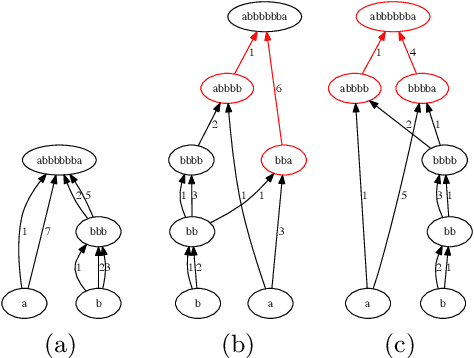
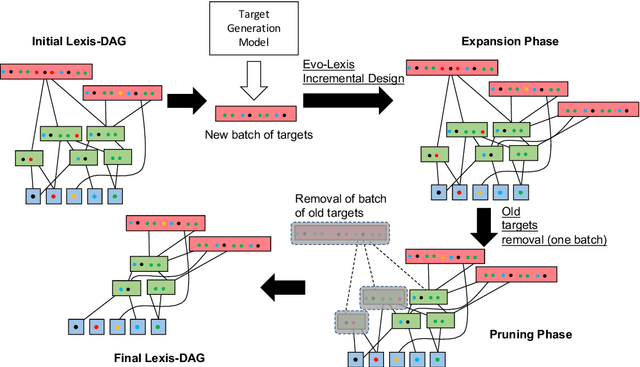

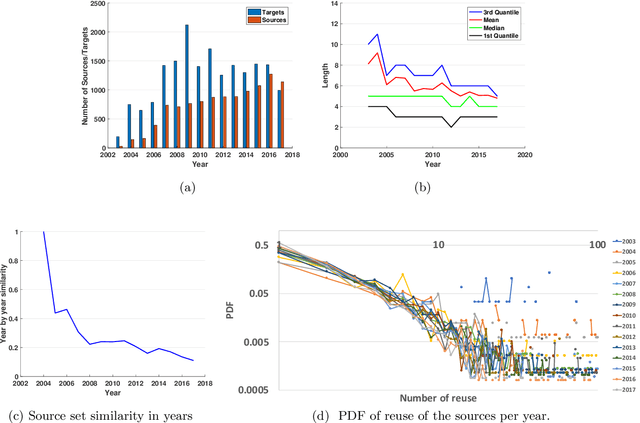
Many complex systems, both in technology and nature, exhibit hierarchical modularity: smaller modules, each of them providing a certain function, are used within larger modules that perform more complex functions. Previously, we have proposed a modeling framework, referred to as Evo-Lexis, that provides insight to some fundamental questions about evolving hierarchical systems. The predictions of the Evo-Lexis model should be tested using real data from evolving systems in which the outputs can be well represented by sequences. In this paper, we investigate the time series of iGEM synthetic DNA dataset sequences, and whether the resulting iGEM hierarchies exhibit the qualitative properties predicted by the Evo-Lexis framework. Contrary to Evo-Lexis, in iGEM the amount of reuse decreases during the timeline of the dataset. Although this results in development of less cost-efficient and less deep Lexis-DAGs, the dataset exhibits a bias in reusing specific nodes more often than others. This results in the Lexis-DAGs to take the shape of an hourglass with relatively high H-score values and stable set of core nodes. Despite the reuse bias and stability of the core set, the dataset presents a high amount of diversity among the targets which is in line with modeling of Evo-Lexis.
Unsupervised Continual Learning and Self-Taught Associative Memory Hierarchies
Apr 03, 2019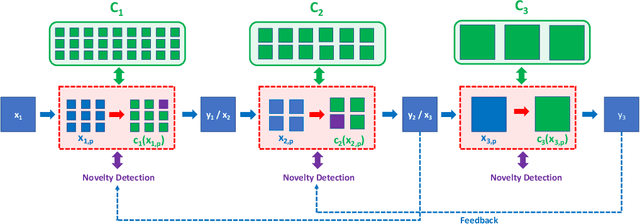

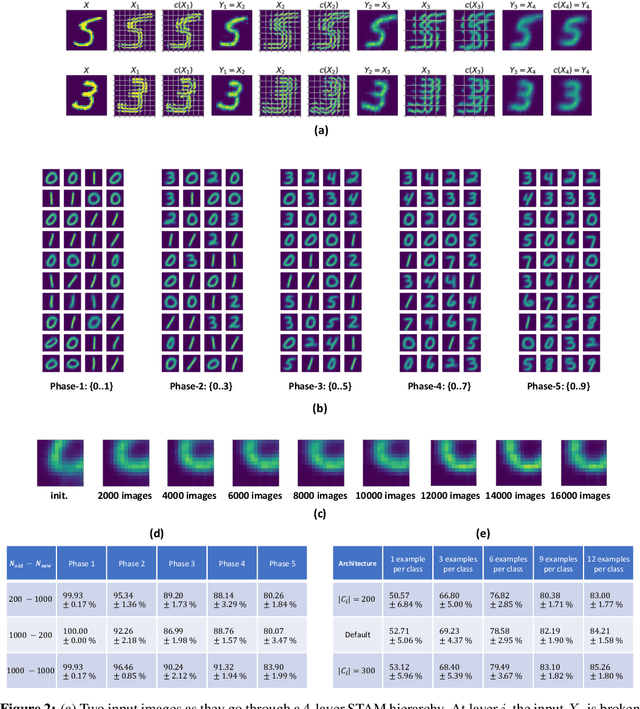
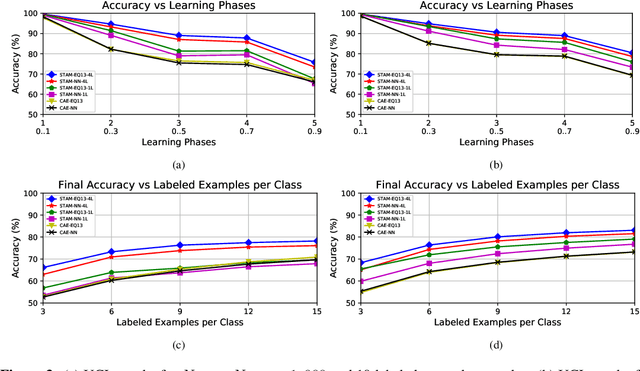
We first pose the Unsupervised Continual Learning (UCL) problem: learning salient representations from a non-stationary stream of unlabeled data in which the number of object classes varies with time. Given limited labeled data just before inference, those representations can also be associated with specific object types to perform classification. To solve the UCL problem, we propose an architecture that involves a single module, called Self-Taught Associative Memory (STAM), which loosely models the function of a cortical column in the mammalian brain. Hierarchies of STAM modules learn based on a combination of Hebbian learning, online clustering, detection of novel patterns, forgetting outliers, and top-down predictions. We illustrate the operation of STAMs in the context of learning handwritten digits in a continual manner with only 3-12 labeled examples per class. STAMs suggest a promising direction to solve the UCL problem without catastrophic forgetting.
A neuro-inspired architecture for unsupervised continual learning based on online clustering and hierarchical predictive coding
Oct 22, 2018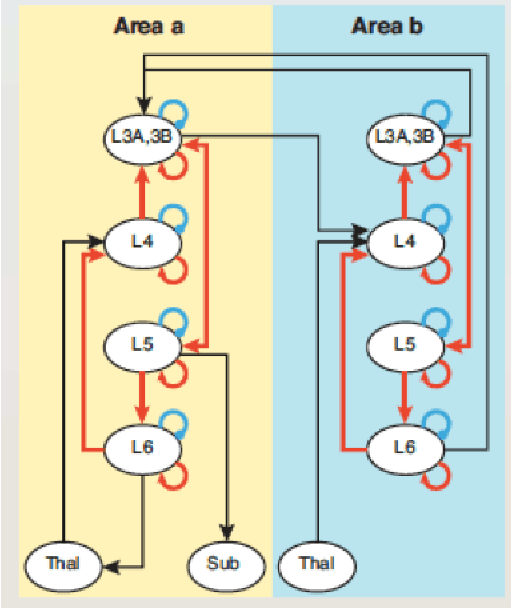
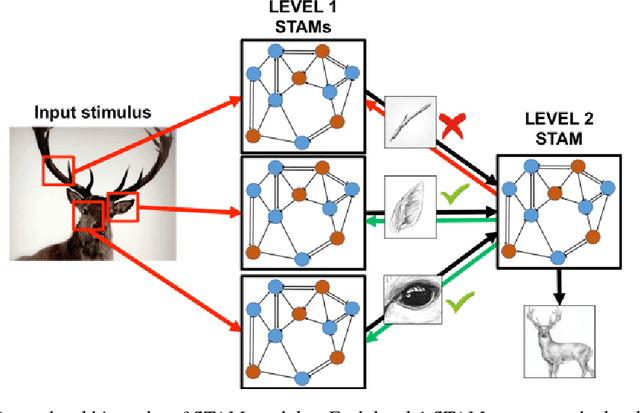
We propose that the Continual Learning desiderata can be achieved through a neuro-inspired architecture, grounded on Mountcastle's cortical column hypothesis. The proposed architecture involves a single module, called Self-Taught Associative Memory (STAM), which models the function of a cortical column. STAMs are repeated in multi-level hierarchies involving feedforward, lateral and feedback connections. STAM networks learn in an unsupervised manner, based on a combination of online clustering and hierarchical predictive coding. This short paper only presents the architecture and its connections with neuroscience. A mathematical formulation and experimental results will be presented in an extended version of this paper.
Emergence and Evolution of Hierarchical Structure in Complex Systems
Aug 04, 2018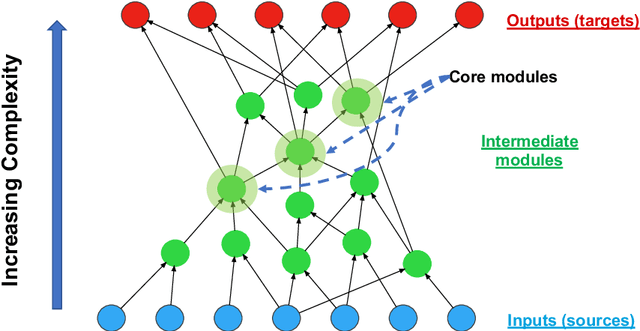

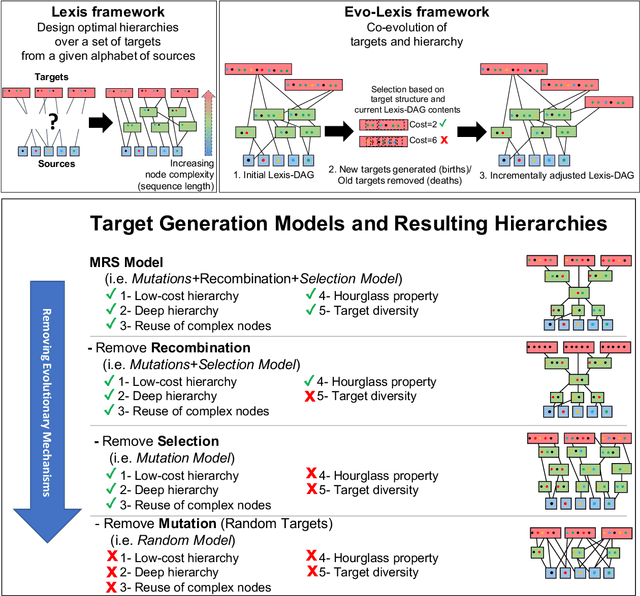
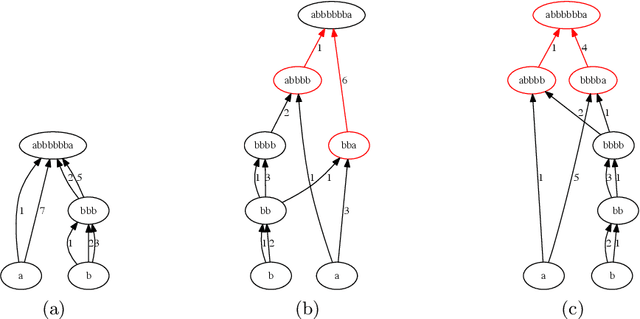
It is well known that many complex systems, both in technology and nature, exhibit hierarchical modularity: smaller modules, each of them providing a certain function, are used within larger modules that perform more complex functions. What is not well understood however is how this hierarchical structure (which is fundamentally a network property) emerges, and how it evolves over time. We propose a modeling framework, referred to as Evo-Lexis, that provides insight to some fundamental questions about evolving hierarchical systems. Evo-Lexis models the most elementary modules of the system as symbols ("sources") and the modules at the highest level of the hierarchy as sequences of those symbols ("targets"). Evo-Lexis computes the optimized adjustment of a given hierarchy when the set of targets changes over time by additions and removals (a process referred to as "incremental design"). In this paper we use computation modeling to show that: - Low-cost and deep hierarchies emerge when the population of target sequences evolves through tinkering and mutation. - Strong selection on the cost of new candidate targets results in reuse of more complex (longer) nodes in an optimized hierarchy. - The bias towards reuse of complex nodes results in an "hourglass architecture" (i.e., few intermediate nodes that cover almost all source-target paths). - With such bias, the core nodes are conserved for relatively long time periods although still being vulnerable to major transitions and punctuated equilibria. - Finally, we analyze the differences in terms of cost and structure between incrementally designed hierarchies and the corresponding "clean-slate" hierarchies which result when the system is designed from scratch after a change.