 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePHEW: Paths with higher edge-weights give "winning tickets" without training data
Paper and Code
Oct 22, 2020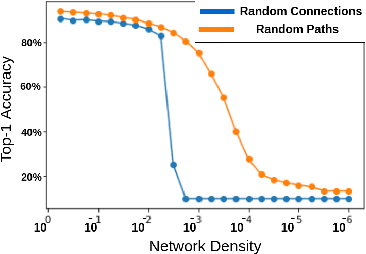
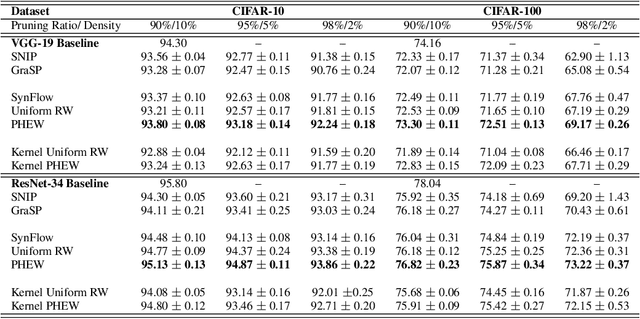
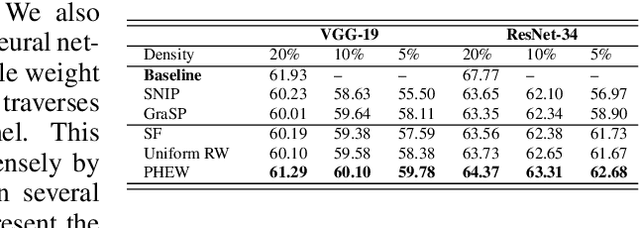
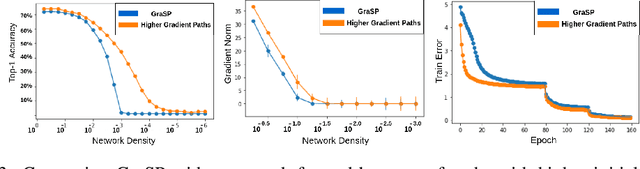
Sparse neural networks have generated substantial interest recently because they can be more efficient in learning and inference, without any significant drop in performance. The "lottery ticket hypothesis" has showed the existence of such sparse subnetworks at initialization. Given a fully-connected initialized architecture, our aim is to find such "winning ticket" networks, without any training data. We first show the advantages of forming input-output paths, over pruning individual connections, to avoid bottlenecks in gradient propagation. Then, we show that Paths with Higher Edge-Weights (PHEW) at initialization have higher loss gradient magnitude, resulting in more efficient training. Selecting such paths can be performed without any data. We empirically validate the effectiveness of the proposed approach against pruning-before-training methods on CIFAR10, CIFAR100 and Tiny-ImageNet for VGG-Net and ResNet. PHEW achieves significant improvements on the current state-of-the-art methods at 10\%, 5\% and 2\% network density. We also evaluate the structural similarity relationship between PHEW networks and pruned networks constructed through Iterated Magnitude Pruning (IMP), concluding that the former belong in the family of winning tickets networks.