 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEAKS: Selecting Key Training Examples Incrementally via Prediction Error Anchored by Kernel Similarity
Apr 08, 2025



As deep learning continues to be driven by ever-larger datasets, understanding which examples are most important for generalization has become a critical question. While progress in data selection continues, emerging applications require studying this problem in dynamic contexts. To bridge this gap, we pose the Incremental Data Selection (IDS) problem, where examples arrive as a continuous stream, and need to be selected without access to the full data source. In this setting, the learner must incrementally build a training dataset of predefined size while simultaneously learning the underlying task. We find that in IDS, the impact of a new sample on the model state depends fundamentally on both its geometric relationship in the feature space and its prediction error. Leveraging this insight, we propose PEAKS (Prediction Error Anchored by Kernel Similarity), an efficient data selection method tailored for IDS. Our comprehensive evaluations demonstrate that PEAKS consistently outperforms existing selection strategies. Furthermore, PEAKS yields increasingly better performance returns than random selection as training data size grows on real-world datasets.
Class-Incremental Continual Learning for General Purpose Healthcare Models
Nov 07, 2023Healthcare clinics regularly encounter dynamic data that changes due to variations in patient populations, treatment policies, medical devices, and emerging disease patterns. Deep learning models can suffer from catastrophic forgetting when fine-tuned in such scenarios, causing poor performance on previously learned tasks. Continual learning allows learning on new tasks without performance drop on previous tasks. In this work, we investigate the performance of continual learning models on four different medical imaging scenarios involving ten classification datasets from diverse modalities, clinical specialties, and hospitals. We implement various continual learning approaches and evaluate their performance in these scenarios. Our results demonstrate that a single model can sequentially learn new tasks from different specialties and achieve comparable performance to naive methods. These findings indicate the feasibility of recycling or sharing models across the same or different medical specialties, offering another step towards the development of general-purpose medical imaging AI that can be shared across institutions.
SHARP: Sparsity and Hidden Activation RePlay for Neuro-Inspired Continual Learning
May 29, 2023Deep neural networks (DNNs) struggle to learn in dynamic environments since they rely on fixed datasets or stationary environments. Continual learning (CL) aims to address this limitation and enable DNNs to accumulate knowledge incrementally, similar to human learning. Inspired by how our brain consolidates memories, a powerful strategy in CL is replay, which involves training the DNN on a mixture of new and all seen classes. However, existing replay methods overlook two crucial aspects of biological replay: 1) the brain replays processed neural patterns instead of raw input, and 2) it prioritizes the replay of recently learned information rather than revisiting all past experiences. To address these differences, we propose SHARP, an efficient neuro-inspired CL method that leverages sparse dynamic connectivity and activation replay. Unlike other activation replay methods, which assume layers not subjected to replay have been pretrained and fixed, SHARP can continually update all layers. Also, SHARP is unique in that it only needs to replay few recently seen classes instead of all past classes. Our experiments on five datasets demonstrate that SHARP outperforms state-of-the-art replay methods in class incremental learning. Furthermore, we showcase SHARP's flexibility in a novel CL scenario where the boundaries between learning episodes are blurry. The SHARP code is available at \url{https://github.com/BurakGurbuz97/SHARP-Continual-Learning}.
System Design for an Integrated Lifelong Reinforcement Learning Agent for Real-Time Strategy Games
Dec 08, 2022

As Artificial and Robotic Systems are increasingly deployed and relied upon for real-world applications, it is important that they exhibit the ability to continually learn and adapt in dynamically-changing environments, becoming Lifelong Learning Machines. Continual/lifelong learning (LL) involves minimizing catastrophic forgetting of old tasks while maximizing a model's capability to learn new tasks. This paper addresses the challenging lifelong reinforcement learning (L2RL) setting. Pushing the state-of-the-art forward in L2RL and making L2RL useful for practical applications requires more than developing individual L2RL algorithms; it requires making progress at the systems-level, especially research into the non-trivial problem of how to integrate multiple L2RL algorithms into a common framework. In this paper, we introduce the Lifelong Reinforcement Learning Components Framework (L2RLCF), which standardizes L2RL systems and assimilates different continual learning components (each addressing different aspects of the lifelong learning problem) into a unified system. As an instantiation of L2RLCF, we develop a standard API allowing easy integration of novel lifelong learning components. We describe a case study that demonstrates how multiple independently-developed LL components can be integrated into a single realized system. We also introduce an evaluation environment in order to measure the effect of combining various system components. Our evaluation environment employs different LL scenarios (sequences of tasks) consisting of Starcraft-2 minigames and allows for the fair, comprehensive, and quantitative comparison of different combinations of components within a challenging common evaluation environment.
NISPA: Neuro-Inspired Stability-Plasticity Adaptation for Continual Learning in Sparse Networks
Jun 18, 2022


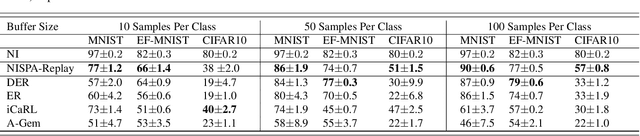
The goal of continual learning (CL) is to learn different tasks over time. The main desiderata associated with CL are to maintain performance on older tasks, leverage the latter to improve learning of future tasks, and to introduce minimal overhead in the training process (for instance, to not require a growing model or retraining). We propose the Neuro-Inspired Stability-Plasticity Adaptation (NISPA) architecture that addresses these desiderata through a sparse neural network with fixed density. NISPA forms stable paths to preserve learned knowledge from older tasks. Also, NISPA uses connection rewiring to create new plastic paths that reuse existing knowledge on novel tasks. Our extensive evaluation on EMNIST, FashionMNIST, CIFAR10, and CIFAR100 datasets shows that NISPA significantly outperforms representative state-of-the-art continual learning baselines, and it uses up to ten times fewer learnable parameters compared to baselines. We also make the case that sparsity is an essential ingredient for continual learning. The NISPA code is available at https://github.com/BurakGurbuz97/NISPA.
MGN-Net: a multi-view graph normalizer for integrating heterogeneous biological network populations
Apr 04, 2021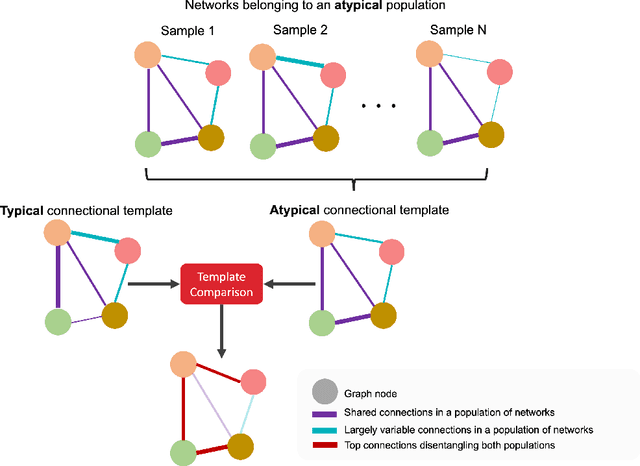


With the recent technological advances, biological datasets, often represented by networks (i.e., graphs) of interacting entities, proliferate with unprecedented complexity and heterogeneity. Although modern network science opens new frontiers of analyzing connectivity patterns in such datasets, we still lack data-driven methods for extracting an integral connectional fingerprint of a multi-view graph population, let alone disentangling the typical from the atypical variations across the population samples. We present the multi-view graph normalizer network (MGN-Net; https://github.com/basiralab/MGN-Net), a graph neural network based method to normalize and integrate a set of multi-view biological networks into a single connectional template that is centered, representative, and topologically sound. We demonstrate the use of MGN-Net by discovering the connectional fingerprints of healthy and neurologically disordered brain network populations including Alzheimer's disease and Autism spectrum disorder patients. Additionally, by comparing the learned templates of healthy and disordered populations, we show that MGN-Net significantly outperforms conventional network integration methods across extensive experiments in terms of producing the most centered templates, recapitulating unique traits of populations, and preserving the complex topology of biological networks. Our evaluations showed that MGN-Net is powerfully generic and easily adaptable in design to different graph-based problems such as identification of relevant connections, normalization and integration.
Deep Graph Normalizer: A Geometric Deep Learning Approach for Estimating Connectional Brain Templates
Dec 28, 2020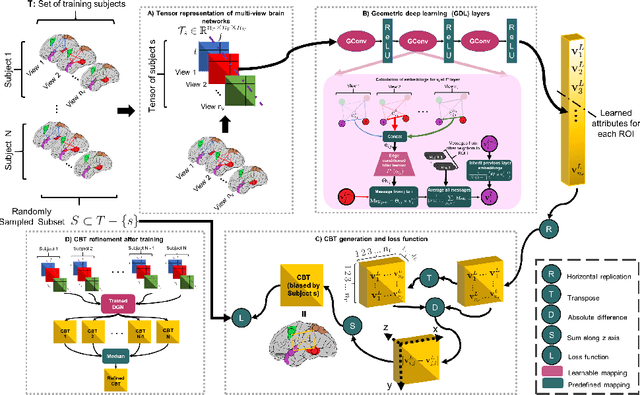

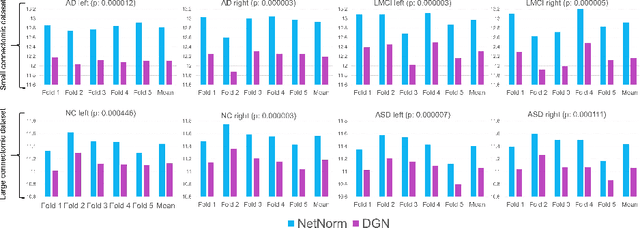
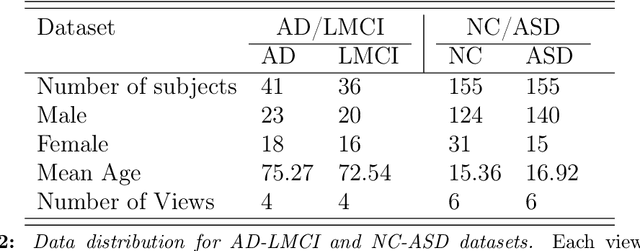
A connectional brain template (CBT) is a normalized graph-based representation of a population of brain networks also regarded as an average connectome. CBTs are powerful tools for creating representative maps of brain connectivity in typical and atypical populations. Particularly, estimating a well-centered and representative CBT for populations of multi-view brain networks (MVBN) is more challenging since these networks sit on complex manifolds and there is no easy way to fuse different heterogeneous network views. This problem remains unexplored with the exception of a few recent works rooted in the assumption that the relationship between connectomes are mostly linear. However, such an assumption fails to capture complex patterns and non-linear variation across individuals. Besides, existing methods are simply composed of sequential MVBN processing blocks without any feedback mechanism, leading to error accumulation. To address these issues, we propose Deep Graph Normalizer (DGN), the first geometric deep learning (GDL) architecture for normalizing a population of MVBNs by integrating them into a single connectional brain template. Our end-to-end DGN learns how to fuse multi-view brain networks while capturing non-linear patterns across subjects and preserving brain graph topological properties by capitalizing on graph convolutional neural networks. We also introduce a randomized weighted loss function which also acts as a regularizer to minimize the distance between the population of MVBNs and the estimated CBT, thereby enforcing its centeredness. We demonstrate that DGN significantly outperforms existing state-of-the-art methods on estimating CBTs on both small-scale and large-scale connectomic datasets in terms of both representativeness and discriminability (i.e., identifying distinctive connectivities fingerprinting each brain network population).
* 11 pages, 2 figures