 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken Pruning for In-Context Generation in Diffusion Transformers
Feb 02, 2026In-context generation significantly enhances Diffusion Transformers (DiTs) by enabling controllable image-to-image generation through reference examples. However, the resulting input concatenation drastically increases sequence length, creating a substantial computational bottleneck. Existing token reduction techniques, primarily tailored for text-to-image synthesis, fall short in this paradigm as they apply uniform reduction strategies, overlooking the inherent role asymmetry between reference contexts and target latents across spatial, temporal, and functional dimensions. To bridge this gap, we introduce ToPi, a training-free token pruning framework tailored for in-context generation in DiTs. Specifically, ToPi utilizes offline calibration-driven sensitivity analysis to identify pivotal attention layers, serving as a robust proxy for redundancy estimation. Leveraging these layers, we derive a novel influence metric to quantify the contribution of each context token for selective pruning, coupled with a temporal update strategy that adapts to the evolving diffusion trajectory. Empirical evaluations demonstrate that ToPi can achieve over 30\% speedup in inference while maintaining structural fidelity and visual consistency across complex image generation tasks.
An Empirical Study of Qwen3 Quantization
May 04, 2025



The Qwen series has emerged as a leading family of open-source Large Language Models (LLMs), demonstrating remarkable capabilities in natural language understanding tasks. With the recent release of Qwen3, which exhibits superior performance across diverse benchmarks, there is growing interest in deploying these models efficiently in resource-constrained environments. Low-bit quantization presents a promising solution, yet its impact on Qwen3's performance remains underexplored. This study conducts a systematic evaluation of Qwen3's robustness under various quantization settings, aiming to uncover both opportunities and challenges in compressing this state-of-the-art model. We rigorously assess 5 existing classic post-training quantization techniques applied to Qwen3, spanning bit-widths from 1 to 8 bits, and evaluate their effectiveness across multiple datasets. Our findings reveal that while Qwen3 maintains competitive performance at moderate bit-widths, it experiences notable degradation in linguistic tasks under ultra-low precision, underscoring the persistent hurdles in LLM compression. These results emphasize the need for further research to mitigate performance loss in extreme quantization scenarios. We anticipate that this empirical analysis will provide actionable insights for advancing quantization methods tailored to Qwen3 and future LLMs, ultimately enhancing their practicality without compromising accuracy. Our project is released on https://github.com/Efficient-ML/Qwen3-Quantization and https://huggingface.co/collections/Efficient-ML/qwen3-quantization-68164450decb1c868788cb2b.
Knitting Robots: A Deep Learning Approach for Reverse-Engineering Fabric Patterns
Apr 18, 2025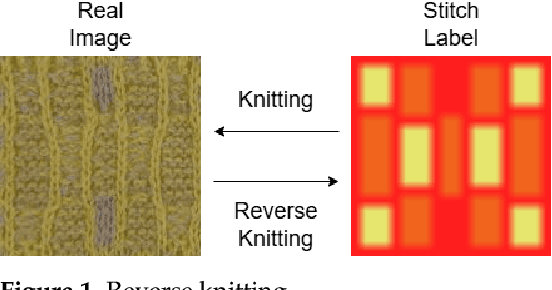



Knitting, a cornerstone of textile manufacturing, is uniquely challenging to automate, particularly in terms of converting fabric designs into precise, machine-readable instructions. This research bridges the gap between textile production and robotic automation by proposing a novel deep learning-based pipeline for reverse knitting to integrate vision-based robotic systems into textile manufacturing. The pipeline employs a two-stage architecture, enabling robots to first identify front labels before inferring complete labels, ensuring accurate, scalable pattern generation. By incorporating diverse yarn structures, including single-yarn (sj) and multi-yarn (mj) patterns, this study demonstrates how our system can adapt to varying material complexities. Critical challenges in robotic textile manipulation, such as label imbalance, underrepresented stitch types, and the need for fine-grained control, are addressed by leveraging specialized deep-learning architectures. This work establishes a foundation for fully automated robotic knitting systems, enabling customizable, flexible production processes that integrate perception, planning, and actuation, thereby advancing textile manufacturing through intelligent robotic automation.
PEAKS: Selecting Key Training Examples Incrementally via Prediction Error Anchored by Kernel Similarity
Apr 08, 2025



As deep learning continues to be driven by ever-larger datasets, understanding which examples are most important for generalization has become a critical question. While progress in data selection continues, emerging applications require studying this problem in dynamic contexts. To bridge this gap, we pose the Incremental Data Selection (IDS) problem, where examples arrive as a continuous stream, and need to be selected without access to the full data source. In this setting, the learner must incrementally build a training dataset of predefined size while simultaneously learning the underlying task. We find that in IDS, the impact of a new sample on the model state depends fundamentally on both its geometric relationship in the feature space and its prediction error. Leveraging this insight, we propose PEAKS (Prediction Error Anchored by Kernel Similarity), an efficient data selection method tailored for IDS. Our comprehensive evaluations demonstrate that PEAKS consistently outperforms existing selection strategies. Furthermore, PEAKS yields increasingly better performance returns than random selection as training data size grows on real-world datasets.
AniSora: Exploring the Frontiers of Animation Video Generation in the Sora Era
Dec 19, 2024



Animation has gained significant interest in the recent film and TV industry. Despite the success of advanced video generation models like Sora, Kling, and CogVideoX in generating natural videos, they lack the same effectiveness in handling animation videos. Evaluating animation video generation is also a great challenge due to its unique artist styles, violating the laws of physics and exaggerated motions. In this paper, we present a comprehensive system, AniSora, designed for animation video generation, which includes a data processing pipeline, a controllable generation model, and an evaluation dataset. Supported by the data processing pipeline with over 10M high-quality data, the generation model incorporates a spatiotemporal mask module to facilitate key animation production functions such as image-to-video generation, frame interpolation, and localized image-guided animation. We also collect an evaluation benchmark of 948 various animation videos, the evaluation on VBench and human double-blind test demonstrates consistency in character and motion, achieving state-of-the-art results in animation video generation. Our evaluation benchmark will be publicly available at https://github.com/bilibili/Index-anisora.
BiDM: Pushing the Limit of Quantization for Diffusion Models
Dec 08, 2024



Diffusion models (DMs) have been significantly developed and widely used in various applications due to their excellent generative qualities. However, the expensive computation and massive parameters of DMs hinder their practical use in resource-constrained scenarios. As one of the effective compression approaches, quantization allows DMs to achieve storage saving and inference acceleration by reducing bit-width while maintaining generation performance. However, as the most extreme quantization form, 1-bit binarization causes the generation performance of DMs to face severe degradation or even collapse. This paper proposes a novel method, namely BiDM, for fully binarizing weights and activations of DMs, pushing quantization to the 1-bit limit. From a temporal perspective, we introduce the Timestep-friendly Binary Structure (TBS), which uses learnable activation binarizers and cross-timestep feature connections to address the highly timestep-correlated activation features of DMs. From a spatial perspective, we propose Space Patched Distillation (SPD) to address the difficulty of matching binary features during distillation, focusing on the spatial locality of image generation tasks and noise estimation networks. As the first work to fully binarize DMs, the W1A1 BiDM on the LDM-4 model for LSUN-Bedrooms 256$\times$256 achieves a remarkable FID of 22.74, significantly outperforming the current state-of-the-art general binarization methods with an FID of 59.44 and invalid generative samples, and achieves up to excellent 28.0 times storage and 52.7 times OPs savings. The code is available at https://github.com/Xingyu-Zheng/BiDM .
A Survey of Low-bit Large Language Models: Basics, Systems, and Algorithms
Sep 25, 2024



Large language models (LLMs) have achieved remarkable advancements in natural language processing, showcasing exceptional performance across various tasks. However, the expensive memory and computational requirements present significant challenges for their practical deployment. Low-bit quantization has emerged as a critical approach to mitigate these challenges by reducing the bit-width of model parameters, activations, and gradients, thus decreasing memory usage and computational demands. This paper presents a comprehensive survey of low-bit quantization methods tailored for LLMs, covering the fundamental principles, system implementations, and algorithmic strategies. An overview of basic concepts and new data formats specific to low-bit LLMs is first introduced, followed by a review of frameworks and systems that facilitate low-bit LLMs across various hardware platforms. Then, we categorize and analyze techniques and toolkits for efficient low-bit training and inference of LLMs. Finally, we conclude with a discussion of future trends and potential advancements of low-bit LLMs. Our systematic overview from basic, system, and algorithm perspectives can offer valuable insights and guidelines for future works to enhance the efficiency and applicability of LLMs through low-bit quantization.
How Good Are Low-bit Quantized LLaMA3 Models? An Empirical Study
Apr 22, 2024Meta's LLaMA family has become one of the most powerful open-source Large Language Model (LLM) series. Notably, LLaMA3 models have recently been released and achieve impressive performance across various with super-large scale pre-training on over 15T tokens of data. Given the wide application of low-bit quantization for LLMs in resource-limited scenarios, we explore LLaMA3's capabilities when quantized to low bit-width. This exploration holds the potential to unveil new insights and challenges for low-bit quantization of LLaMA3 and other forthcoming LLMs, especially in addressing performance degradation problems that suffer in LLM compression. Specifically, we evaluate the 10 existing post-training quantization and LoRA-finetuning methods of LLaMA3 on 1-8 bits and diverse datasets to comprehensively reveal LLaMA3's low-bit quantization performance. Our experiment results indicate that LLaMA3 still suffers non-negligent degradation in these scenarios, especially in ultra-low bit-width. This highlights the significant performance gap under low bit-width that needs to be bridged in future developments. We expect that this empirical study will prove valuable in advancing future models, pushing the LLMs to lower bit-width with higher accuracy for being practical. Our project is released on https://github.com/Macaronlin/LLaMA3-Quantization and quantized LLaMA3 models are released in https://huggingface.co/LLMQ.
BinaryDM: Towards Accurate Binarization of Diffusion Model
Apr 08, 2024



With the advancement of diffusion models (DMs) and the substantially increased computational requirements, quantization emerges as a practical solution to obtain compact and efficient low-bit DMs. However, the highly discrete representation leads to severe accuracy degradation, hindering the quantization of diffusion models to ultra-low bit-widths. In this paper, we propose BinaryDM, a novel accurate quantization-aware training approach to push the weights of diffusion models towards the limit of 1-bit. Firstly, we present a Learnable Multi-basis Binarizer (LMB) to recover the representations generated by the binarized DM, which improves the information in details of representations crucial to the DM. Secondly, a Low-rank Representation Mimicking (LRM) is applied to enhance the binarization-aware optimization of the DM, alleviating the optimization direction ambiguity caused by fine-grained alignment. Moreover, a progressive initialization strategy is applied to training DMs to avoid convergence difficulties. Comprehensive experiments demonstrate that BinaryDM achieves significant accuracy and efficiency gains compared to SOTA quantization methods of DMs under ultra-low bit-widths. As the first binarization method for diffusion models, BinaryDM achieves impressive 16.0 times FLOPs and 27.1 times storage savings with 1-bit weight and 4-bit activation, showcasing its substantial advantages and potential for deploying DMs on resource-limited scenarios.
Accurate LoRA-Finetuning Quantization of LLMs via Information Retention
Feb 08, 2024The LoRA-finetuning quantization of LLMs has been extensively studied to obtain accurate yet compact LLMs for deployment on resource-constrained hardware. However, existing methods cause the quantized LLM to severely degrade and even fail to benefit from the finetuning of LoRA. This paper proposes a novel IR-QLoRA for pushing quantized LLMs with LoRA to be highly accurate through information retention. The proposed IR-QLoRA mainly relies on two technologies derived from the perspective of unified information: (1) statistics-based Information Calibration Quantization allows the quantized parameters of LLM to retain original information accurately; (2) finetuning-based Information Elastic Connection makes LoRA utilizes elastic representation transformation with diverse information. Comprehensive experiments show that IR-QLoRA can significantly improve accuracy across LLaMA and LLaMA2 families under 2-4 bit-widths, e.g., 4- bit LLaMA-7B achieves 1.4% improvement on MMLU compared with the state-of-the-art methods. The significant performance gain requires only a tiny 0.31% additional time consumption, revealing the satisfactory efficiency of our IRQLoRA. We highlight that IR-QLoRA enjoys excellent versatility, compatible with various frameworks (e.g., NormalFloat and Integer quantization) and brings general accuracy gains. The code is available at https://github.com/htqin/ir-qlora.