 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeAPT: Safe Simulation-to-Real Robot Learning using Diverse Policies Learned in Simulation
Paper and Code
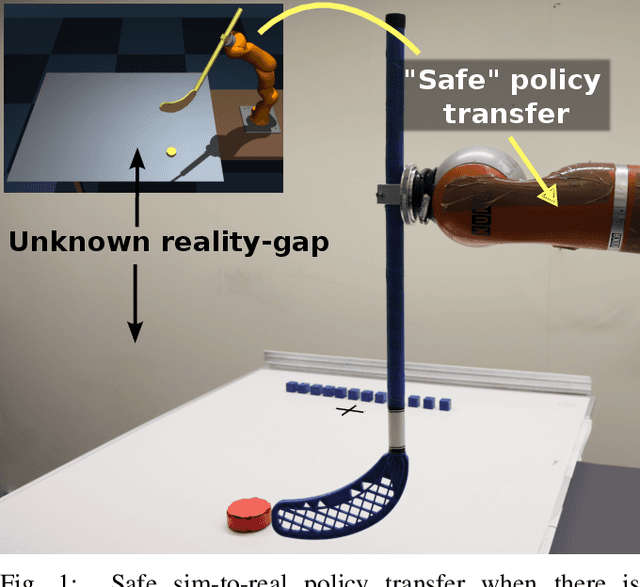

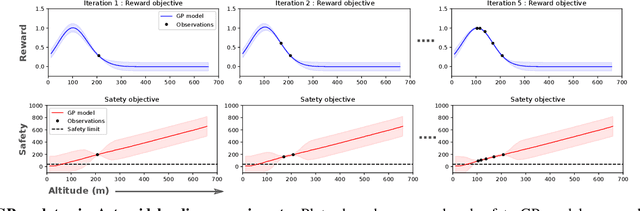

The framework of Simulation-to-real learning, i.e, learning policies in simulation and transferring those policies to the real world is one of the most promising approaches towards data-efficient learning in robotics. However, due to the inevitable reality gap between the simulation and the real world, a policy learned in the simulation may not always generate a safe behaviour on the real robot. As a result, during adaptation of the policy in the real world, the robot may damage itself or cause harm to its surroundings. In this work, we introduce a novel learning algorithm called SafeAPT that leverages a diverse repertoire of policies evolved in the simulation and transfers the most promising safe policy to the real robot through episodic interaction. To achieve this, SafeAPT iteratively learns a probabilistic reward model as well as a safety model using real-world observations combined with simulated experiences as priors. Then, it performs Bayesian optimization on the repertoire with the reward model while maintaining the specified safety constraint using the safety model. SafeAPT allows a robot to adapt to a wide range of goals safely with the same repertoire of policies evolved in the simulation. We compare SafeAPT with several baselines, both in simulated and real robotic experiments and show that SafeAPT finds high-performance policies within a few minutes in the real world while minimizing safety violations during the interactions.