 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTournament Informed Adversarial Quality Diversity
Jan 27, 2026Quality diversity (QD) is a branch of evolutionary computation that seeks high-quality and behaviorally diverse solutions to a problem. While adversarial problems are common, classical QD cannot be easily applied to them, as both the fitness and the behavior depend on the opposing solutions. Recently, Generational Adversarial MAP-Elites (GAME) has been proposed to coevolve both sides of an adversarial problem by alternating the execution of a multi-task QD algorithm against previous elites, called tasks. The original algorithm selects new tasks based on a behavioral criterion, which may lead to undesired dynamics due to inter-side dependencies. In addition, comparing sets of solutions cannot be done directly using classical QD measures due to side dependencies. In this paper, we (1) use an inter-variants tournament to compare the sets of solutions, ensuring a fair comparison, with 6 measures of quality and diversity, and (2) propose two tournament-informed task selection methods to promote higher quality and diversity at each generation. We evaluate the variants across three adversarial problems: Pong, a Cat-and-mouse game, and a Pursuers-and-evaders game. We show that the tournament-informed task selection method leads to higher adversarial quality and diversity. We hope that this work will help further advance adversarial quality diversity. Code, videos, and supplementary material are available at https://github.com/Timothee-ANNE/GAME_tournament_informed.
Adversarial Coevolutionary Illumination with Generational Adversarial MAP-Elites
May 10, 2025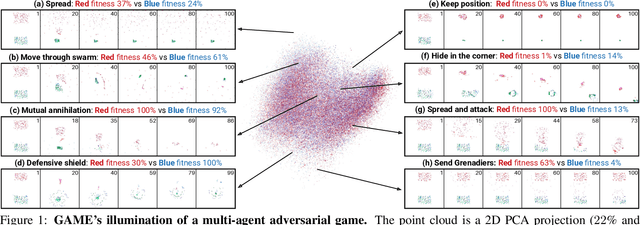

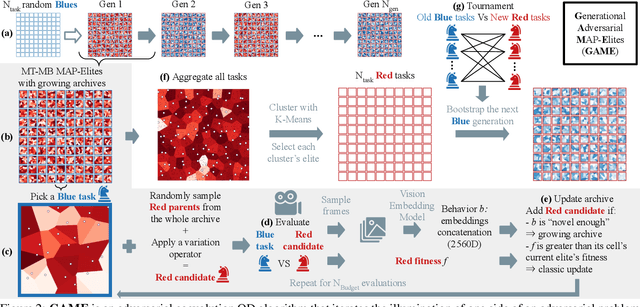

Unlike traditional optimization algorithms focusing on finding a single optimal solution, Quality-Diversity (QD) algorithms illuminate a search space by finding high-performing solutions that cover a specified behavior space. However, tackling adversarial problems is more challenging due to the behavioral interdependence between opposing sides. Most applications of QD algorithms to these problems evolve only one side, thus reducing illumination coverage. In this paper, we propose a new QD algorithm, Generational Adversarial MAP-Elites (GAME), which coevolves solutions by alternating sides through a sequence of generations. Combining GAME with vision embedding models enables the algorithm to directly work from videos of behaviors instead of handcrafted descriptors. Some key findings are that (1) emerging evolutionary dynamics sometimes resemble an arms race, (2) starting each generation from scratch increases open-endedness, and (3) keeping neutral mutations preserves stepping stones that seem necessary to reach the highest performance. In conclusion, the results demonstrate that GAME can successfully illuminate an adversarial multi-agent game, opening up interesting future directions in understanding the emergence of open-ended coevolution.
Harnessing Language for Coordination: A Framework and Benchmark for LLM-Driven Multi-Agent Control
Dec 16, 2024



Large Language Models (LLMs) have demonstrated remarkable performance across various tasks. A promising but largely under-explored area is their potential to facilitate human coordination with many agents. Such capabilities would be useful in domains including disaster response, urban planning, and real-time strategy scenarios. In this work, we introduce (1) a real-time strategy game benchmark designed to evaluate these abilities and (2) a novel framework we term HIVE. HIVE empowers a single human to coordinate swarms of up to 2,000 agents using natural language dialog with an LLM. We present promising results on this multi-agent benchmark, with our hybrid approach solving tasks such as coordinating agent movements, exploiting unit weaknesses, leveraging human annotations, and understanding terrain and strategic points. However, our findings also highlight critical limitations of current models, including difficulties in processing spatial visual information and challenges in formulating long-term strategic plans. This work sheds light on the potential and limitations of LLMs in human-swarm coordination, paving the way for future research in this area. The HIVE project page, which includes videos of the system in action, can be found here: hive.syrkis.com.
Parametric-Task MAP-Elites
Feb 02, 2024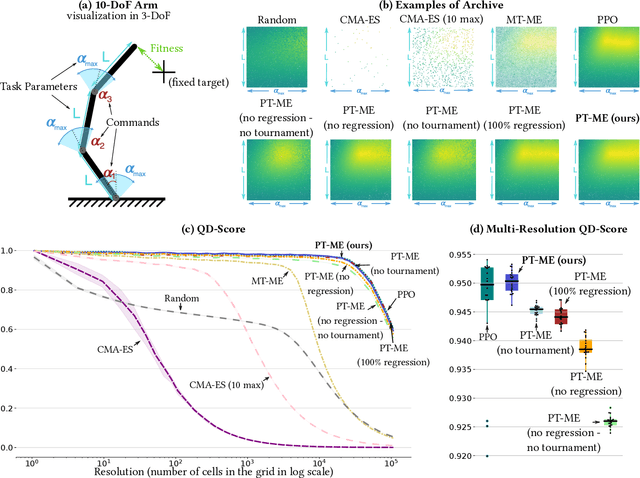
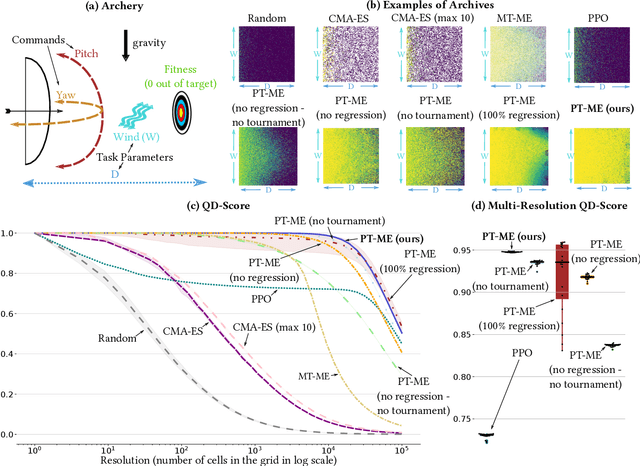
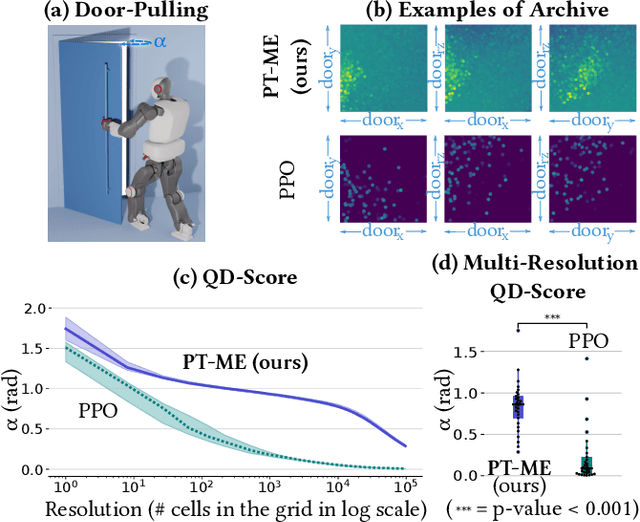
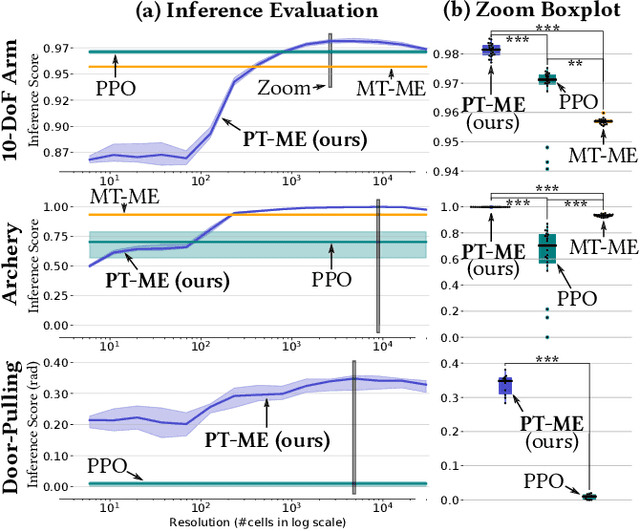
Optimizing a set of functions simultaneously by leveraging their similarity is called multi-task optimization. Current black-box multi-task algorithms only solve a finite set of tasks, even when the tasks originate from a continuous space. In this paper, we introduce Parametric-task MAP-Elites (PT-ME), a novel black-box algorithm to solve continuous multi-task optimization problems. This algorithm (1) solves a new task at each iteration, effectively covering the continuous space, and (2) exploits a new variation operator based on local linear regression. The resulting dataset of solutions makes it possible to create a function that maps any task parameter to its optimal solution. We show on two parametric-task toy problems and a more realistic and challenging robotic problem in simulation that PT-ME outperforms all baselines, including the deep reinforcement learning algorithm PPO.
First do not fall: learning to exploit the environment with a damaged humanoid robot
Mar 01, 2022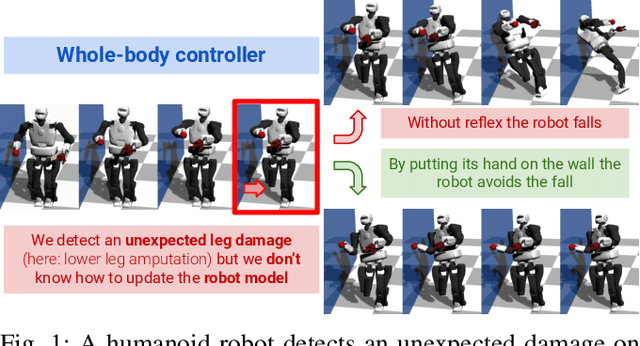
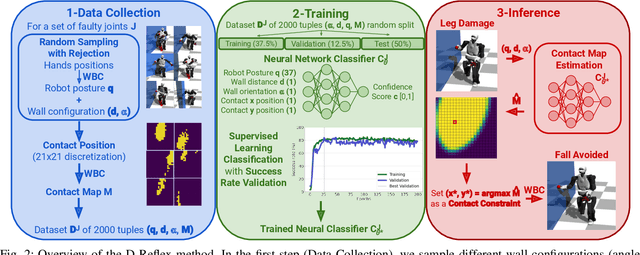
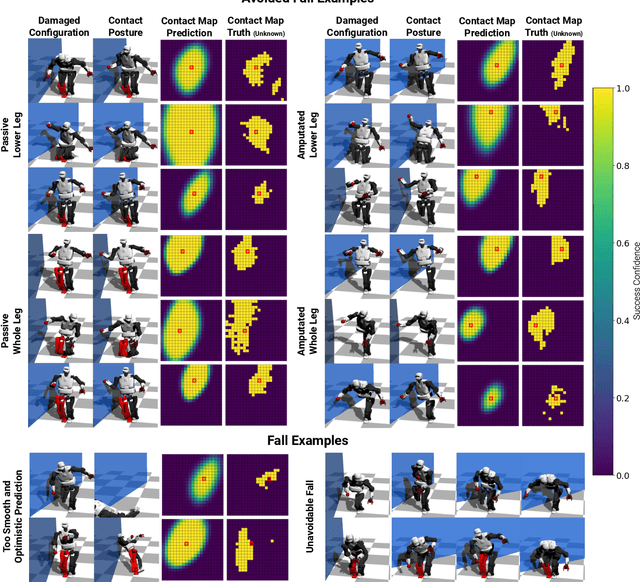
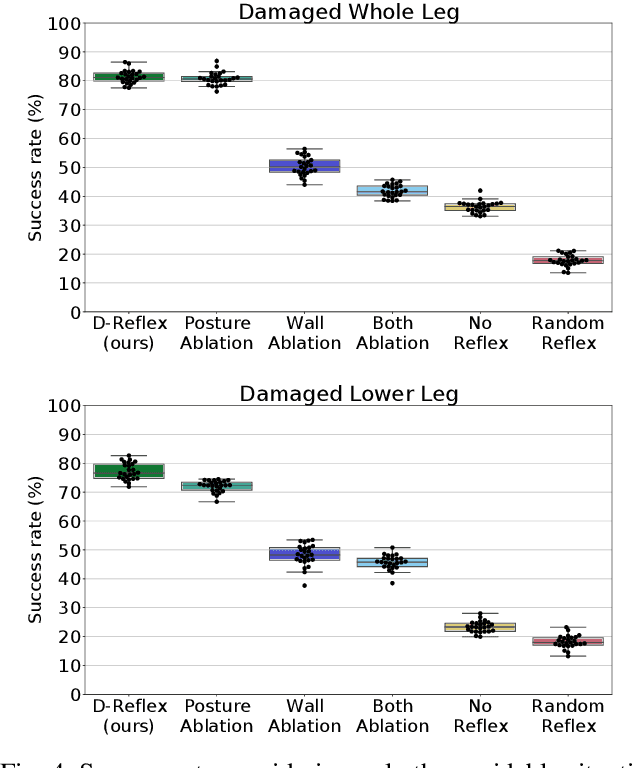
Humanoid robots could replace humans in hazardous situations but most of such situations are equally dangerous for them, which means that they have a high chance of being damaged and fall. We hypothesize that humanoid robots would be mostly used in buildings, which makes them likely to be close to a wall. To avoid a fall, they can therefore lean on the closest wall, like a human would do, provided that they find in a few milliseconds where to put the hand(s). This article introduces a method, called D-Reflex, that learns a neural network that chooses this contact position given the wall orientation, the wall distance, and the posture of the robot. This contact position is then used by a whole-body controller to reach a stable posture. We show that D-Reflex allows a simulated TALOS robot (1.75m, 100kg, 30 degrees of freedom) to avoid more than 75% of the avoidable falls.
Meta-Reinforcement Learning for Adaptive Motor Control in Changing Robot Dynamics and Environments
Jan 19, 2021
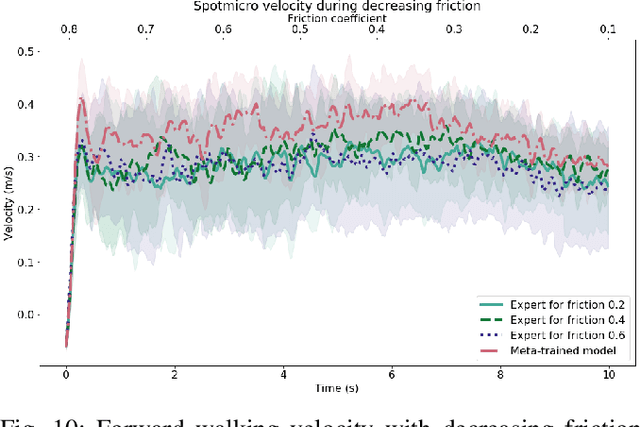
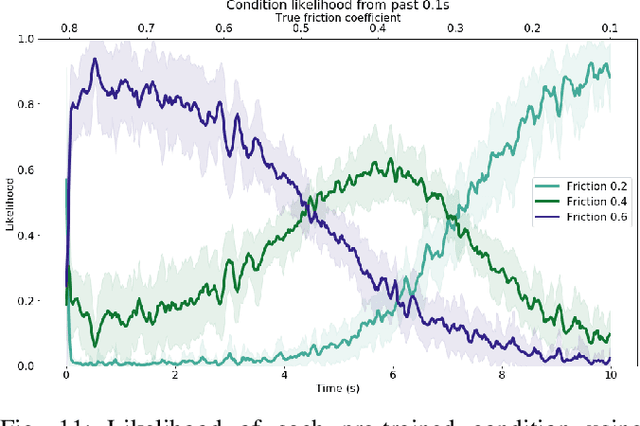
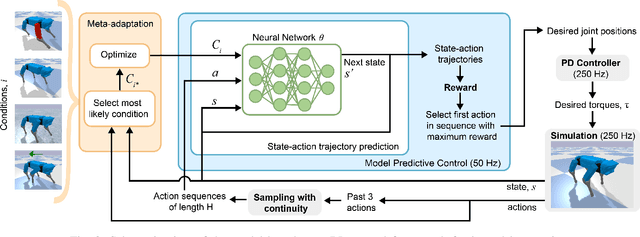
This work developed a meta-learning approach that adapts the control policy on the fly to different changing conditions for robust locomotion. The proposed method constantly updates the interaction model, samples feasible sequences of actions of estimated the state-action trajectories, and then applies the optimal actions to maximize the reward. To achieve online model adaptation, our proposed method learns different latent vectors of each training condition, which are selected online given the newly collected data. Our work designs appropriate state space and reward functions, and optimizes feasible actions in an MPC fashion which are then sampled directly in the joint space considering constraints, hence requiring no prior design of specific walking gaits. We further demonstrate the robot's capability of detecting unexpected changes during interaction and adapting control policies quickly. The extensive validation on the SpotMicro robot in a physics simulation shows adaptive and robust locomotion skills under varying ground friction, external pushes, and different robot models including hardware faults and changes.
Fast Online Adaptation in Robotics through Meta-Learning Embeddings of Simulated Priors
Mar 10, 2020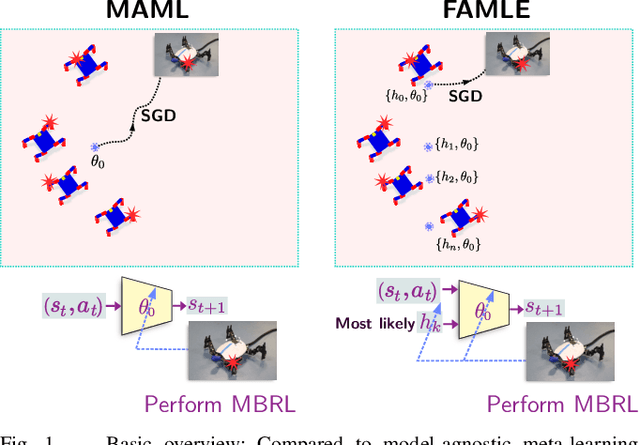
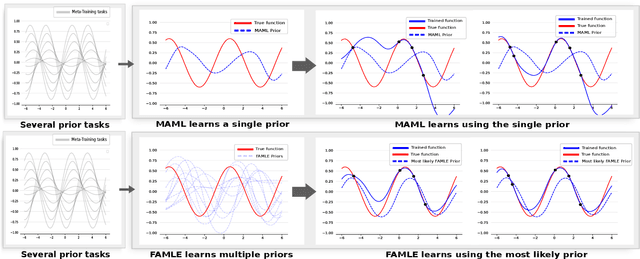
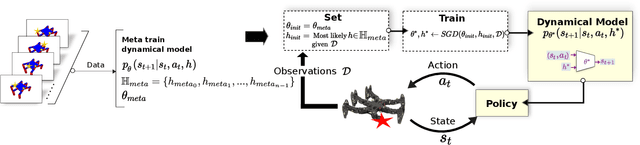
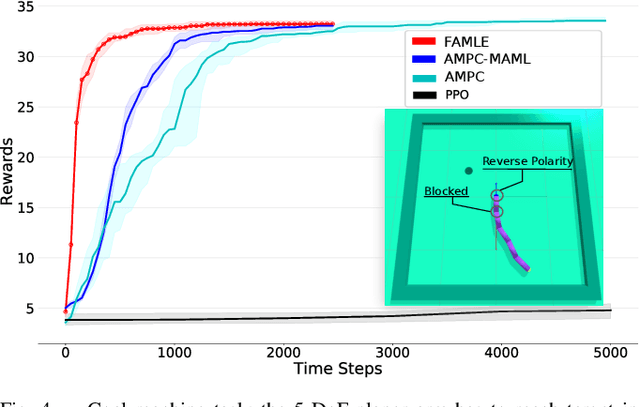
Meta-learning algorithms can accelerate the model-based reinforcement learning (MBRL) algorithms by finding an initial set of parameters for the dynamical model such that the model can be trained to match the actual dynamics of the system with only a few data-points. However, in the real world, a robot might encounter any situation starting from motor failures to finding itself in a rocky terrain where the dynamics of the robot can be significantly different from one another. In this paper, first, we show that when meta-training situations (the prior situations) have such diverse dynamics, using a single set of meta-trained parameters as a starting point still requires a large number of observations from the real system to learn a useful model of the dynamics. Second, we propose an algorithm called FAMLE that mitigates this limitation by meta-training several initial starting points (i.e., initial parameters) for training the model and allows the robot to select the most suitable starting point to adapt the model to the current situation with only a few gradient steps. We compare FAMLE to MBRL, MBRL with a meta-trained model with MAML, and model-free policy search algorithm PPO for various simulated and real robotic tasks, and show that FAMLE allows the robots to adapt to novel damages in significantly fewer time-steps than the baselines.