 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack to the Manifold: Recovering from Out-of-Distribution States
Jul 18, 2022
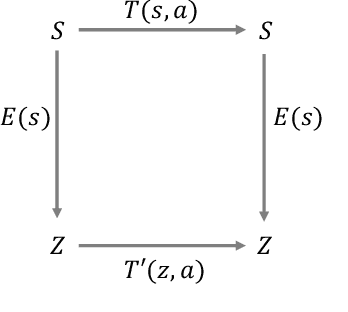
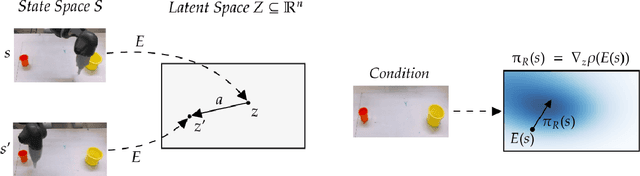

Learning from previously collected datasets of expert data offers the promise of acquiring robotic policies without unsafe and costly online explorations. However, a major challenge is a distributional shift between the states in the training dataset and the ones visited by the learned policy at the test time. While prior works mainly studied the distribution shift caused by the policy during the offline training, the problem of recovering from out-of-distribution states at the deployment time is not very well studied yet. We alleviate the distributional shift at the deployment time by introducing a recovery policy that brings the agent back to the training manifold whenever it steps out of the in-distribution states, e.g., due to an external perturbation. The recovery policy relies on an approximation of the training data density and a learned equivariant mapping that maps visual observations into a latent space in which translations correspond to the robot actions. We demonstrate the effectiveness of the proposed method through several manipulation experiments on a real robotic platform. Our results show that the recovery policy enables the agent to complete tasks while the behavioral cloning alone fails because of the distributional shift problem.
Training and Evaluation of Deep Policies using Reinforcement Learning and Generative Models
Apr 18, 2022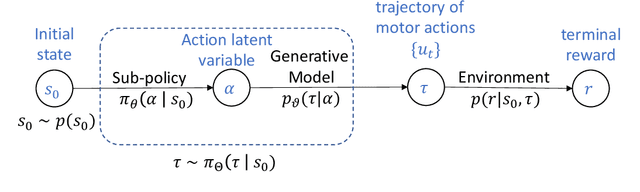
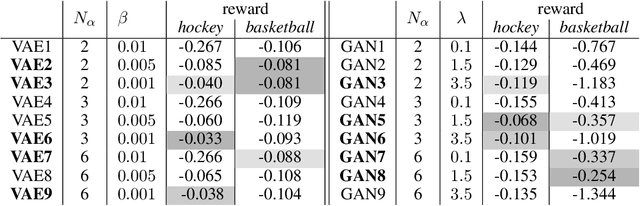
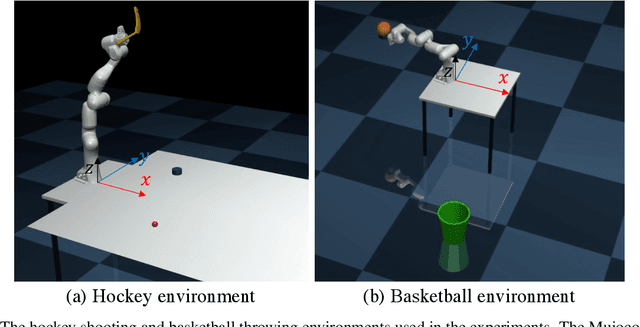
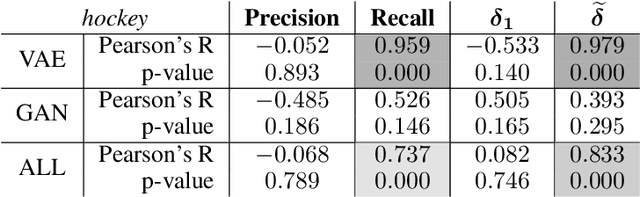
We present a data-efficient framework for solving sequential decision-making problems which exploits the combination of reinforcement learning (RL) and latent variable generative models. The framework, called GenRL, trains deep policies by introducing an action latent variable such that the feed-forward policy search can be divided into two parts: (i) training a sub-policy that outputs a distribution over the action latent variable given a state of the system, and (ii) unsupervised training of a generative model that outputs a sequence of motor actions conditioned on the latent action variable. GenRL enables safe exploration and alleviates the data-inefficiency problem as it exploits prior knowledge about valid sequences of motor actions. Moreover, we provide a set of measures for evaluation of generative models such that we are able to predict the performance of the RL policy training prior to the actual training on a physical robot. We experimentally determine the characteristics of generative models that have most influence on the performance of the final policy training on two robotics tasks: shooting a hockey puck and throwing a basketball. Furthermore, we empirically demonstrate that GenRL is the only method which can safely and efficiently solve the robotics tasks compared to two state-of-the-art RL methods.
Latent-Variable Advantage-Weighted Policy Optimization for Offline RL
Mar 16, 2022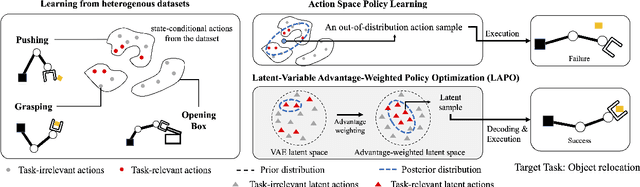
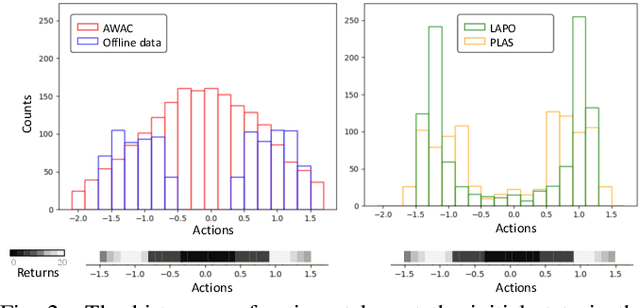

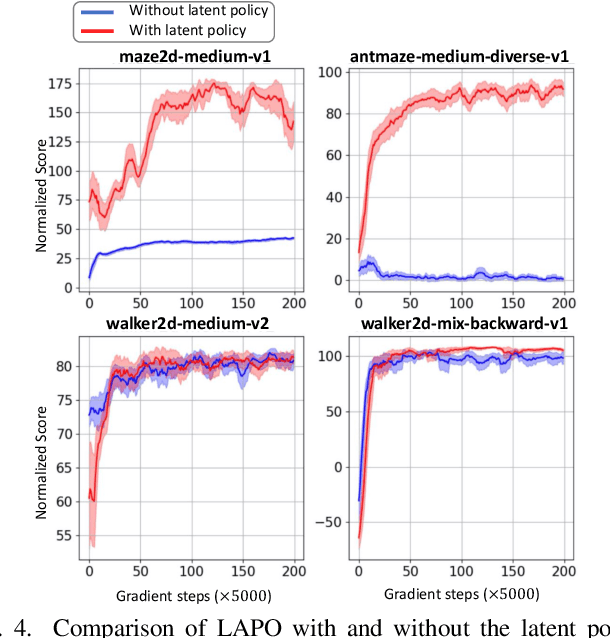
Offline reinforcement learning methods hold the promise of learning policies from pre-collected datasets without the need to query the environment for new transitions. This setting is particularly well-suited for continuous control robotic applications for which online data collection based on trial-and-error is costly and potentially unsafe. In practice, offline datasets are often heterogeneous, i.e., collected in a variety of scenarios, such as data from several human demonstrators or from policies that act with different purposes. Unfortunately, such datasets can exacerbate the distribution shift between the behavior policy underlying the data and the optimal policy to be learned, leading to poor performance. To address this challenge, we propose to leverage latent-variable policies that can represent a broader class of policy distributions, leading to better adherence to the training data distribution while maximizing reward via a policy over the latent variable. As we empirically show on a range of simulated locomotion, navigation, and manipulation tasks, our method referred to as latent-variable advantage-weighted policy optimization (LAPO), improves the average performance of the next best-performing offline reinforcement learning methods by 49% on heterogeneous datasets, and by 8% on datasets with narrow and biased distributions.
Bayesian Meta-Learning for Few-Shot Policy Adaptation Across Robotic Platforms
Mar 05, 2021


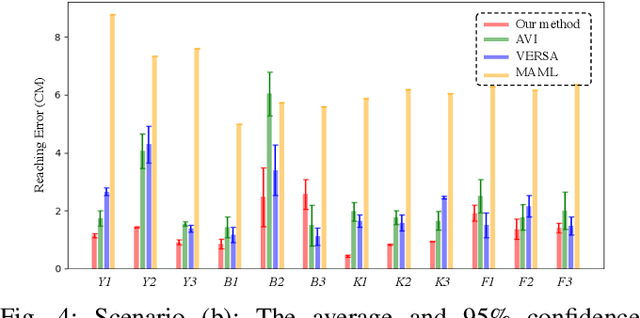
Reinforcement learning methods can achieve significant performance but require a large amount of training data collected on the same robotic platform. A policy trained with expensive data is rendered useless after making even a minor change to the robot hardware. In this paper, we address the challenging problem of adapting a policy, trained to perform a task, to a novel robotic hardware platform given only few demonstrations of robot motion trajectories on the target robot. We formulate it as a few-shot meta-learning problem where the goal is to find a meta-model that captures the common structure shared across different robotic platforms such that data-efficient adaptation can be performed. We achieve such adaptation by introducing a learning framework consisting of a probabilistic gradient-based meta-learning algorithm that models the uncertainty arising from the few-shot setting with a low-dimensional latent variable. We experimentally evaluate our framework on a simulated reaching and a real-robot picking task using 400 simulated robots generated by varying the physical parameters of an existing set of robotic platforms. Our results show that the proposed method can successfully adapt a trained policy to different robotic platforms with novel physical parameters and the superiority of our meta-learning algorithm compared to state-of-the-art methods for the introduced few-shot policy adaptation problem.
Few-shot model-based adaptation in noisy conditions
Oct 16, 2020



Few-shot adaptation is a challenging problem in the context of simulation-to-real transfer in robotics, requiring safe and informative data collection. In physical systems, additional challenge may be posed by domain noise, which is present in virtually all real-world applications. In this paper, we propose to perform few-shot adaptation of dynamics models in noisy conditions using an uncertainty-aware Kalman filter-based neural network architecture. We show that the proposed method, which explicitly addresses domain noise, improves few-shot adaptation error over a blackbox adaptation LSTM baseline, and over a model-free on-policy reinforcement learning approach, which tries to learn an adaptable and informative policy at the same time. The proposed method also allows for system analysis by analyzing hidden states of the model during and after adaptation.
Data-efficient visuomotor policy training using reinforcement learning and generative models
Jul 26, 2020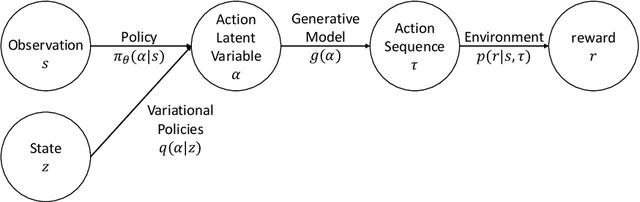



We present a data-efficient framework for solving deep visuomotor sequential decision-making problems which exploits the combination of reinforcement learning (RL) with the latent variable generative models. Our framework trains deep visuomotor policies by introducing an action latent variable such that the feed-forward policy search can be divided into two parts: (1) training a sub-policy that outputs a distribution over the action latent variable given a state of the system, and (2) training a generative model that outputs a sequence of motor actions given a latent action representation. Our approach enables safe exploration and alleviates the data-inefficiency problem as it exploits prior knowledge about valid sequences of motor actions. Moreover, by evaluating the quality of the generative models we are able to predict the performance of the RL policy training prior to the actual training on the physical robot. We achieve this by defining two novel measures, disentanglement and local linearity, for assessing the quality of generative models' latent spaces, and complementing them with the existing measures for evaluation of generative models. We demonstrate the efficiency of our approach on a picking task using several different generative models and determine which of their properties have the most influence on the final policy training.
Human-centered collaborative robots with deep reinforcement learning
Jul 02, 2020

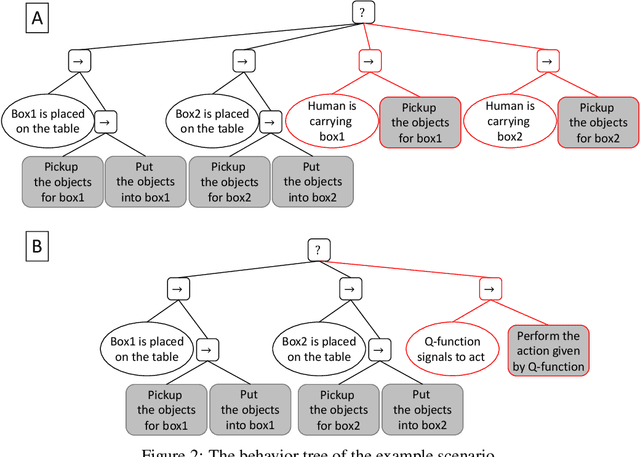
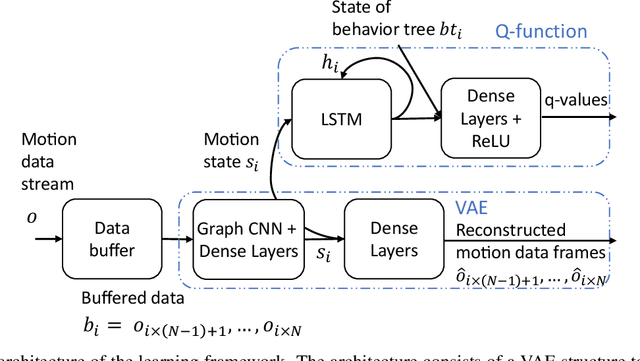
We present a reinforcement learning based framework for human-centered collaborative systems. The framework is proactive and balances the benefits of timely actions with the risk of taking improper actions by minimizing the total time spent to complete the task. The framework is learned end-to-end in an unsupervised fashion addressing the perception uncertainties and decision making in an integrated manner. The framework is shown to provide more fluent coordination between human and robot partners on an example task of packaging compared to alternatives for which perception and decision-making systems are learned independently, using supervised learning. The foremost benefit of the proposed approach is that it allows for fast adaptation to new human partners and tasks since tedious annotation of motion data is avoided and the learning is performed on-line.
Imitating by generating: deep generative models for imitation of interactive tasks
Oct 14, 2019

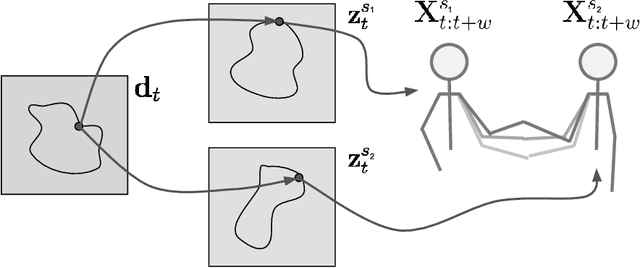
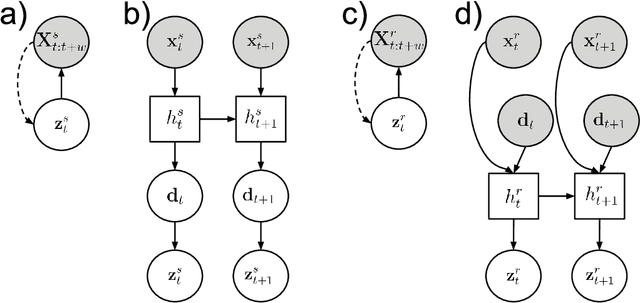
To coordinate actions with an interaction partner requires a constant exchange of sensorimotor signals. Humans acquire these skills in infancy and early childhood mostly by imitation learning and active engagement with a skilled partner. They require the ability to predict and adapt to one's partner during an interaction. In this work we want to explore these ideas in a human-robot interaction setting in which a robot is required to learn interactive tasks from a combination of observational and kinesthetic learning. To this end, we propose a deep learning framework consisting of a number of components for (1) human and robot motion embedding, (2) motion prediction of the human partner and (3) generation of robot joint trajectories matching the human motion. To test these ideas, we collect human-human interaction data and human-robot interaction data of four interactive tasks "hand-shake", "hand-wave", "parachute fist-bump" and "rocket fist-bump". We demonstrate experimentally the importance of predictive and adaptive components as well as low-level abstractions to successfully learn to imitate human behavior in interactive social tasks.
Adversarial Feature Training for Generalizable Robotic Visuomotor Control
Sep 17, 2019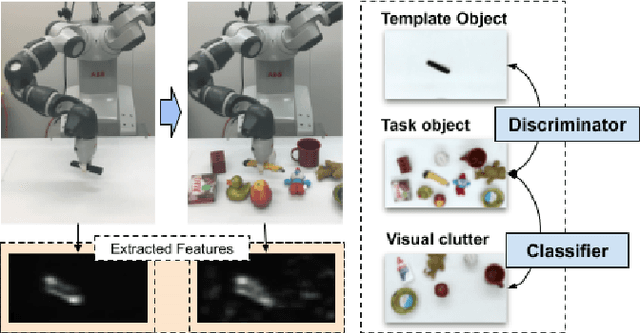



Deep reinforcement learning (RL) has enabled training action-selection policies, end-to-end, by learning a function which maps image pixels to action outputs. However, it's application to visuomotor robotic policy training has been limited because of the challenge of large-scale data collection when working with physical hardware. A suitable visuomotor policy should perform well not just for the task-setup it has been trained for, but also for all varieties of the task, including novel objects at different viewpoints surrounded by task-irrelevant objects. However, it is impractical for a robotic setup to sufficiently collect interactive samples in a RL framework to generalize well to novel aspects of a task. In this work, we demonstrate that by using adversarial training for domain transfer, it is possible to train visuomotor policies based on RL frameworks, and then transfer the acquired policy to other novel task domains. We propose to leverage the deep RL capabilities to learn complex visuomotor skills for uncomplicated task setups, and then exploit transfer learning to generalize to new task domains provided only still images of the task in the target domain. We evaluate our method on two real robotic tasks, picking and pouring, and compare it to a number of prior works, demonstrating its superiority.
Meta Reinforcement Learning for Sim-to-real Domain Adaptation
Sep 16, 2019

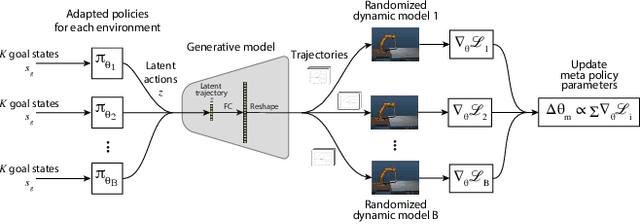

Modern reinforcement learning methods suffer from low sample efficiency and unsafe exploration, making it infeasible to train robotic policies entirely on real hardware. In this work, we propose to address the problem of sim-to-real domain transfer by using meta learning to train a policy that can adapt to a variety of dynamic conditions, and using a task-specific trajectory generation model to provide an action space that facilitates quick exploration. We evaluate the method by performing domain adaptation in simulation and analyzing the structure of the latent space during adaptation. We then deploy this policy on a KUKA LBR 4+ robot and evaluate its performance on a task of hitting a hockey puck to a target. Our method shows more consistent and stable domain adaptation than the baseline, resulting in better overall performance.