 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the evaluators: Towards human-aligned metrics for missing markers reconstruction
Oct 18, 2024Animation data is often obtained through optical motion capture systems, which utilize a multitude of cameras to establish the position of optical markers. However, system errors or occlusions can result in missing markers, the manual cleaning of which can be time-consuming. This has sparked interest in machine learning-based solutions for missing marker reconstruction in the academic community. Most academic papers utilize a simplistic mean square error as the main metric. In this paper, we show that this metric does not correlate with subjective perception of the fill quality. We introduce and evaluate a set of better-correlated metrics that can drive progress in the field.
Imitating by generating: deep generative models for imitation of interactive tasks
Oct 14, 2019

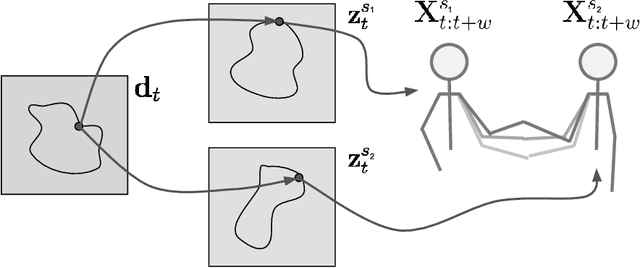
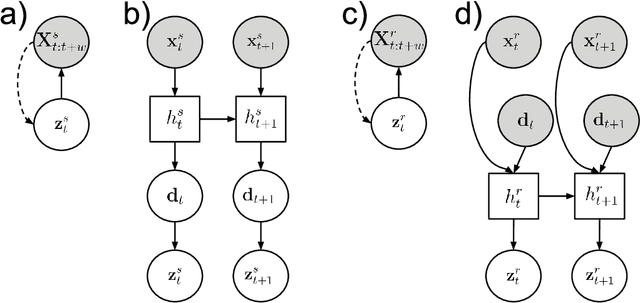
To coordinate actions with an interaction partner requires a constant exchange of sensorimotor signals. Humans acquire these skills in infancy and early childhood mostly by imitation learning and active engagement with a skilled partner. They require the ability to predict and adapt to one's partner during an interaction. In this work we want to explore these ideas in a human-robot interaction setting in which a robot is required to learn interactive tasks from a combination of observational and kinesthetic learning. To this end, we propose a deep learning framework consisting of a number of components for (1) human and robot motion embedding, (2) motion prediction of the human partner and (3) generation of robot joint trajectories matching the human motion. To test these ideas, we collect human-human interaction data and human-robot interaction data of four interactive tasks "hand-shake", "hand-wave", "parachute fist-bump" and "rocket fist-bump". We demonstrate experimentally the importance of predictive and adaptive components as well as low-level abstractions to successfully learn to imitate human behavior in interactive social tasks.
Classify, predict, detect, anticipate and synthesize: Hierarchical recurrent latent variable models for human activity modeling
Nov 06, 2018



Human activity modeling operates on two levels: high-level action modeling, such as classification, prediction, detection and anticipation, and low-level motion trajectory prediction and synthesis. In this work, we propose a semi-supervised generative latent variable model that addresses both of these levels by modeling continuous observations as well as semantic labels. We extend the model to capture the dependencies between different entities, such as a human and objects, and to represent hierarchical label structure, such as high-level actions and sub-activities. In the experiments we investigate our model's capability to classify, predict, detect and anticipate semantic action and affordance labels and to predict and generate human motion. We train our models on data extracted from depth image streams from the Cornell Activity 120, the UTKinect-Action3D and the Stony Brook University Kinect Interaction Dataset. We observe that our model performs well in all of the tasks and often outperforms task-specific models.
Detect, anticipate and generate: Semi-supervised recurrent latent variable models for human activity modeling
Sep 19, 2018

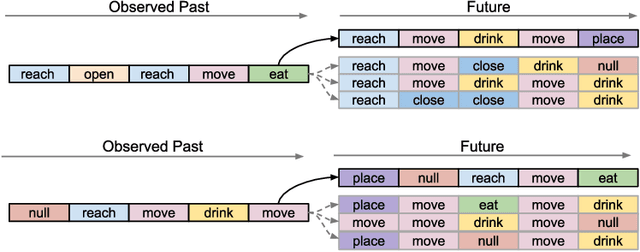

Successful Human-Robot collaboration requires a predictive model of human behavior. The robot needs to be able to recognize current goals and actions and to predict future activities in a given context. However, the spatio-temporal sequence of human actions is difficult to model since latent factors such as intention, task, knowledge, intuition and preference determine the action choices of each individual. In this work we introduce semi-supervised variational recurrent neural networks which are able to a) model temporal distributions over latent factors and the observable feature space, b) incorporate discrete labels such as activity type when available, and c) generate possible future action sequences on both feature and label level. We evaluate our model on the Cornell Activity Dataset CAD-120 dataset. Our model outperforms state-of-the-art approaches in both activity and affordance detection and anticipation. Additionally, we show how samples of possible future action sequences are in line with past observations.
Human-Robot Collaboration: From Psychology to Social Robotics
May 29, 2017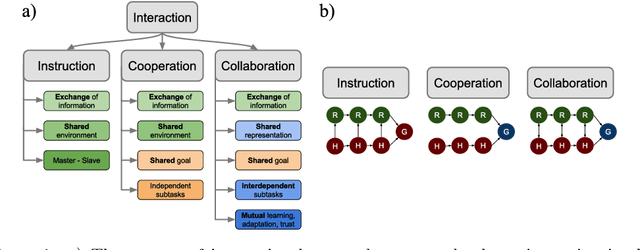

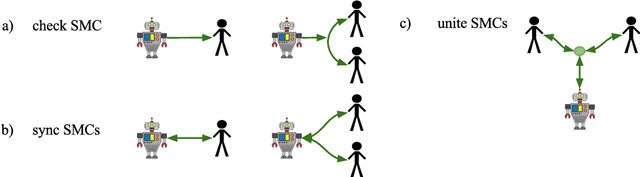
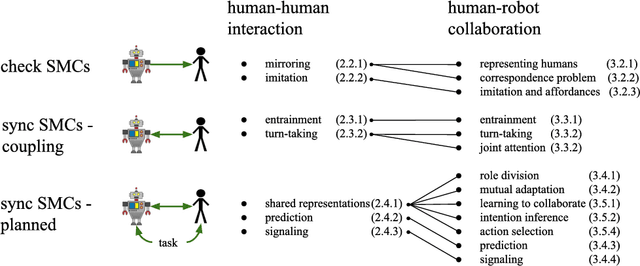
With the advances in robotic technology, research in human-robot collaboration (HRC) has gained in importance. For robots to interact with humans autonomously they need active decision making that takes human partners into account. However, state-of-the-art research in HRC does often assume a leader-follower division, in which one agent leads the interaction. We believe that this is caused by the lack of a reliable representation of the human and the environment to allow autonomous decision making. This problem can be overcome by an embodied approach to HRC which is inspired by psychological studies of human-human interaction (HHI). In this survey, we review neuroscientific and psychological findings of the sensorimotor patterns that govern HHI and view them in a robotics context. Additionally, we study the advances made by the robotic community into the direction of embodied HRC. We focus on the mechanisms that are required for active, physical human-robot collaboration. Finally, we discuss the similarities and differences in the two fields of study which pinpoint directions of future research.
Deep representation learning for human motion prediction and classification
Apr 13, 2017
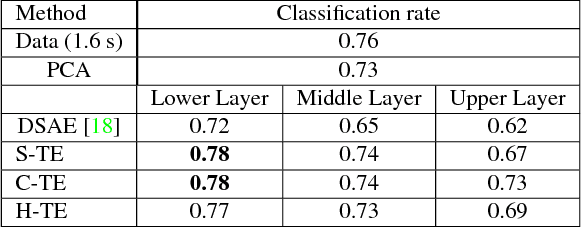
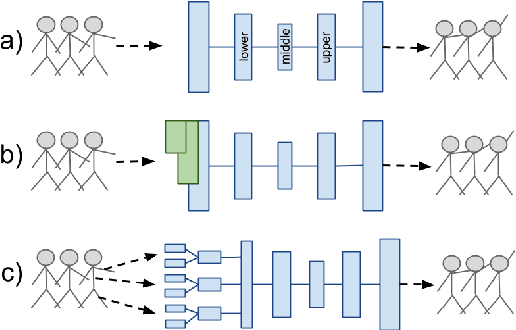
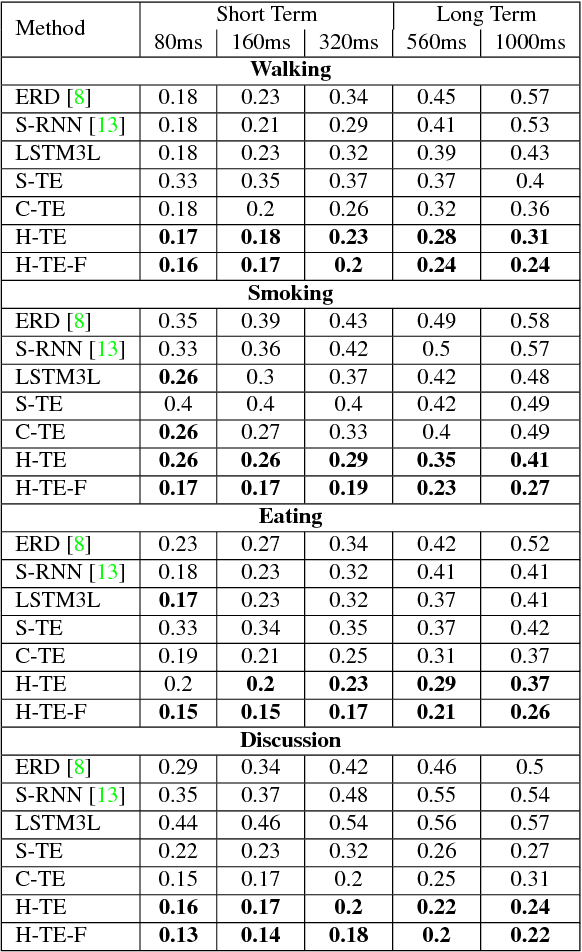
Generative models of 3D human motion are often restricted to a small number of activities and can therefore not generalize well to novel movements or applications. In this work we propose a deep learning framework for human motion capture data that learns a generic representation from a large corpus of motion capture data and generalizes well to new, unseen, motions. Using an encoding-decoding network that learns to predict future 3D poses from the most recent past, we extract a feature representation of human motion. Most work on deep learning for sequence prediction focuses on video and speech. Since skeletal data has a different structure, we present and evaluate different network architectures that make different assumptions about time dependencies and limb correlations. To quantify the learned features, we use the output of different layers for action classification and visualize the receptive fields of the network units. Our method outperforms the recent state of the art in skeletal motion prediction even though these use action specific training data. Our results show that deep feedforward networks, trained from a generic mocap database, can successfully be used for feature extraction from human motion data and that this representation can be used as a foundation for classification and prediction.
Anticipating many futures: Online human motion prediction and synthesis for human-robot collaboration
Feb 27, 2017
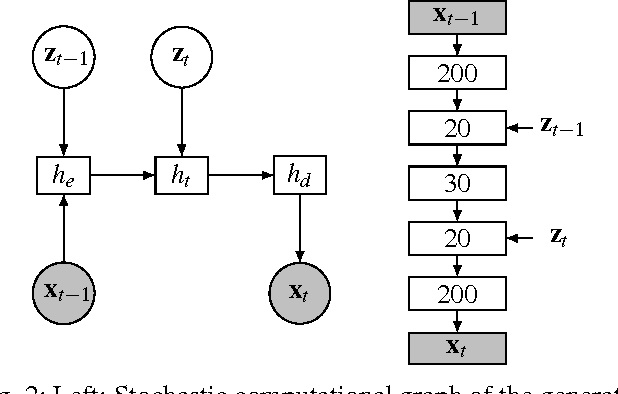

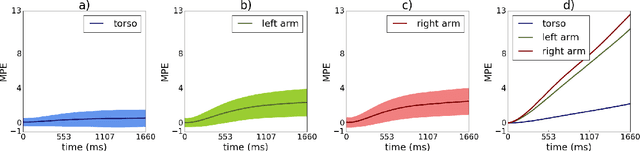
Fluent and safe interactions of humans and robots require both partners to anticipate the others' actions. A common approach to human intention inference is to model specific trajectories towards known goals with supervised classifiers. However, these approaches do not take possible future movements into account nor do they make use of kinematic cues, such as legible and predictable motion. The bottleneck of these methods is the lack of an accurate model of general human motion. In this work, we present a conditional variational autoencoder that is trained to predict a window of future human motion given a window of past frames. Using skeletal data obtained from RGB depth images, we show how this unsupervised approach can be used for online motion prediction for up to 1660 ms. Additionally, we demonstrate online target prediction within the first 300-500 ms after motion onset without the use of target specific training data. The advantage of our probabilistic approach is the possibility to draw samples of possible future motions. Finally, we investigate how movements and kinematic cues are represented on the learned low dimensional manifold.
CapriDB - Capture, Print, Innovate: A Low-Cost Pipeline and Database for Reproducible Manipulation Research
Oct 17, 2016



We present a novel approach and database which combines the inexpensive generation of 3D object models via monocular or RGB-D camera images with 3D printing and a state of the art object tracking algorithm. Unlike recent efforts towards the creation of 3D object databases for robotics, our approach does not require expensive and controlled 3D scanning setups and enables anyone with a camera to scan, print and track complex objects for manipulation research. The proposed approach results in highly detailed mesh models whose 3D printed replicas are at times difficult to distinguish from the original. A key motivation for utilizing 3D printed objects is the ability to precisely control and vary object properties such as the mass distribution and size in the 3D printing process to obtain reproducible conditions for robotic manipulation research. We present CapriDB - an extensible database resulting from this approach containing initially 40 textured and 3D printable mesh models together with tracking features to facilitate the adoption of the proposed approach.
A Sensorimotor Reinforcement Learning Framework for Physical Human-Robot Interaction
Jul 27, 2016



Modeling of physical human-robot collaborations is generally a challenging problem due to the unpredictive nature of human behavior. To address this issue, we present a data-efficient reinforcement learning framework which enables a robot to learn how to collaborate with a human partner. The robot learns the task from its own sensorimotor experiences in an unsupervised manner. The uncertainty of the human actions is modeled using Gaussian processes (GP) to implement action-value functions. Optimal action selection given the uncertain GP model is ensured by Bayesian optimization. We apply the framework to a scenario in which a human and a PR2 robot jointly control the ball position on a plank based on vision and force/torque data. Our experimental results show the suitability of the proposed method in terms of fast and data-efficient model learning, optimal action selection under uncertainties and equal role sharing between the partners.
Self-learning and adaptation in a sensorimotor framework
Jan 05, 2016



We present a general framework to autonomously achieve a task, where autonomy is acquired by learning sensorimotor patterns of a robot, while it is interacting with its environment. To accomplish the task, using the learned sensorimotor contingencies, our approach predicts a sequence of actions that will lead to the desirable observations. Gaussian processes (GP) with automatic relevance determination is used to learn the sensorimotor mapping. In this way, relevant sensory and motor components can be systematically found in high-dimensional sensory and motor spaces. We propose an incremental GP learning strategy, which discerns between situations, when an update or an adaptation must be implemented. RRT* is exploited to enable long-term planning and generating a sequence of states that lead to a given goal; while a gradient-based search finds the optimum action to steer to a neighbouring state in a single time step. Our experimental results prove the successfulness of the proposed framework to learn a joint space controller with high data dimensions (10$\times$15). It demonstrates short training phase (less than 12 seconds), real-time performance and rapid adaptations capabilities.